Enhancing Sequential Music Recommendation with Negative Feedback-informed Contrastive Learning

0
📶
Sign in to get full access
Overview
- This research paper proposes a novel approach to enhance sequential music recommendation using negative feedback-informed contrastive learning.
- The key ideas are to leverage negative feedback from users to learn better representations, and use contrastive learning to enhance the recommendation model.
- The authors conduct experiments to evaluate their proposed method on real-world music streaming datasets, and demonstrate its effectiveness compared to traditional recommendation approaches.
Plain English Explanation
When we use music streaming services, the recommendations we get are often based on what we've liked or listened to in the past. But what about the songs we didn't like? Enhancing Sequential Music Recommendation with Negative Feedback-informed Contrastive Learning explores how incorporating this "negative feedback" can improve music recommendations.
The researchers developed a new recommendation model that learns from both the songs we've enjoyed and the ones we didn't. It uses a technique called "contrastive learning" to ensure the model understands the differences between songs we like and dislike. This helps the model make better recommendations tailored to our personal music preferences.
By testing their approach on real-world music streaming data, the researchers showed that their negative feedback-informed contrastive learning model outperforms traditional recommendation methods. This suggests that considering both positive and negative feedback can lead to more personalized and relevant music recommendations for users.
Technical Explanation
Enhancing Sequential Music Recommendation with Negative Feedback-informed Contrastive Learning presents a new approach to sequential music recommendation that leverages negative feedback from users.
The key components of their model are:
-
Negative Feedback Representation Learning: The model learns user representations that capture both positive and negative feedback, using a contrastive learning objective to distinguish liked and disliked items.
-
Negative Feedback-aware Recommendation: The learned user and item representations are then used to make personalized music recommendations, with the negative feedback helping the model better understand user preferences.
The authors conduct experiments on real-world music streaming datasets, comparing their approach to several baseline recommendation methods. Their results demonstrate that incorporating negative feedback through contrastive learning leads to significant improvements in recommendation performance, as measured by metrics like normalized discounted cumulative gain (NDCG) and hit rate.
Critical Analysis
The paper makes a convincing case for the value of incorporating negative feedback into sequential music recommendation models. The authors provide a solid technical explanation of their approach and present compelling experimental results.
However, one potential limitation is the reliance on explicit negative feedback from users. In practical music streaming scenarios, users may not always provide negative feedback, and the model would need to infer implicit negative signals from user behavior. The authors acknowledge this challenge and suggest exploring ways to leverage implicit negative feedback in future work.
Additionally, the paper does not delve deeply into the interpretability or explainability of the learned user and item representations. Understanding how the negative feedback-informed contrastive learning process shapes these representations could yield further insights and enable more transparent recommendation systems.
Overall, this research represents an important step forward in enhancing sequential music recommendation by leveraging negative feedback, and the ideas presented could be fruitfully explored in other recommendation domains as well.
Conclusion
Enhancing Sequential Music Recommendation with Negative Feedback-informed Contrastive Learning introduces a novel approach to improve music recommendation systems by incorporating both positive and negative user feedback.
The key innovation is the use of contrastive learning to learn user and item representations that capture information about disliked as well as liked items. This allows the recommendation model to make more personalized and relevant suggestions, as demonstrated by the authors' experiments on real-world music streaming data.
This research highlights the potential benefits of considering negative feedback in recommendation systems, and could inspire further work on leveraging diverse user signals to enhance the quality and transparency of personalized recommendations across various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
Enhancing Sequential Music Recommendation with Negative Feedback-informed Contrastive Learning
Pavan Seshadri, Shahrzad Shashaani, Peter Knees
Modern music streaming services are heavily based on recommendation engines to serve content to users. Sequential recommendation -- continuously providing new items within a single session in a contextually coherent manner -- has been an emerging topic in current literature. User feedback -- a positive or negative response to the item presented -- is used to drive content recommendations by learning user preferences. We extend this idea to session-based recommendation to provide context-coherent music recommendations by modelling negative user feedback, i.e., skips, in the loss function. We propose a sequence-aware contrastive sub-task to structure item embeddings in session-based music recommendation, such that true next-positive items (ignoring skipped items) are structured closer in the session embedding space, while skipped tracks are structured farther away from all items in the session. This directly affects item rankings using a K-nearest-neighbors search for next-item recommendations, while also promoting the rank of the true next item. Experiments incorporating this task into SoTA methods for sequential item recommendation show consistent performance gains in terms of next-item hit rate, item ranking, and skip down-ranking on three music recommendation datasets, strongly benefiting from the increasing presence of user feedback.
Read more9/12/2024

0
Negative Feedback for Music Personalization
M. Jeffrey Mei, Oliver Bembom, Andreas F. Ehmann
Next-item recommender systems are often trained using only positive feedback with randomly-sampled negative feedback. We show the benefits of using real negative feedback both as inputs into the user sequence and also as negative targets for training a next-song recommender system for internet radio. In particular, using explicit negative samples during training helps reduce training time by ~60% while also improving test accuracy by ~6%; adding user skips as additional inputs also can considerably increase user coverage alongside slightly improving accuracy. We test the impact of using a large number of random negative samples to capture a 'harder' one and find that the test accuracy increases with more randomly-sampled negatives, but only to a point. Too many random negatives leads to false negatives that limits the lift, which is still lower than if using true negative feedback. We also find that the test accuracy is fairly robust with respect to the proportion of different feedback types, and compare the learned embeddings for different feedback types.
Read more6/10/2024
📶
0
Diffusion-based Contrastive Learning for Sequential Recommendation
Ziqiang Cui, Haolun Wu, Bowei He, Ji Cheng, Chen Ma
Self-supervised contrastive learning, which directly extracts inherent data correlations from unlabeled data, has been widely utilized to mitigate the data sparsity issue in sequential recommendation. The majority of existing methods create different augmented views of the same user sequence via random augmentation, and subsequently minimize their distance in the embedding space to enhance the quality of user representations. However, random augmentation often disrupts the semantic information and interest evolution pattern inherent in the user sequence, leading to the generation of semantically distinct augmented views. Promoting similarity of these semantically diverse augmented sequences can render the learned user representations insensitive to variations in user preferences and interest evolution, contradicting the core learning objectives of sequential recommendation. To address this issue, we leverage the inherent characteristics of sequential recommendation and propose the use of context information to generate more reasonable augmented positive samples. Specifically, we introduce a context-aware diffusion-based contrastive learning method for sequential recommendation. Given a user sequence, our method selects certain positions and employs a context-aware diffusion model to generate alternative items for these positions with the guidance of context information. These generated items then replace the corresponding original items, creating a semantically consistent augmented view of the original sequence. Additionally, to maintain representation cohesion, item embeddings are shared between the diffusion model and the recommendation model, and the entire framework is trained in an end-to-end manner. Extensive experiments on five benchmark datasets demonstrate the superiority of our proposed method.
Read more6/10/2024
0
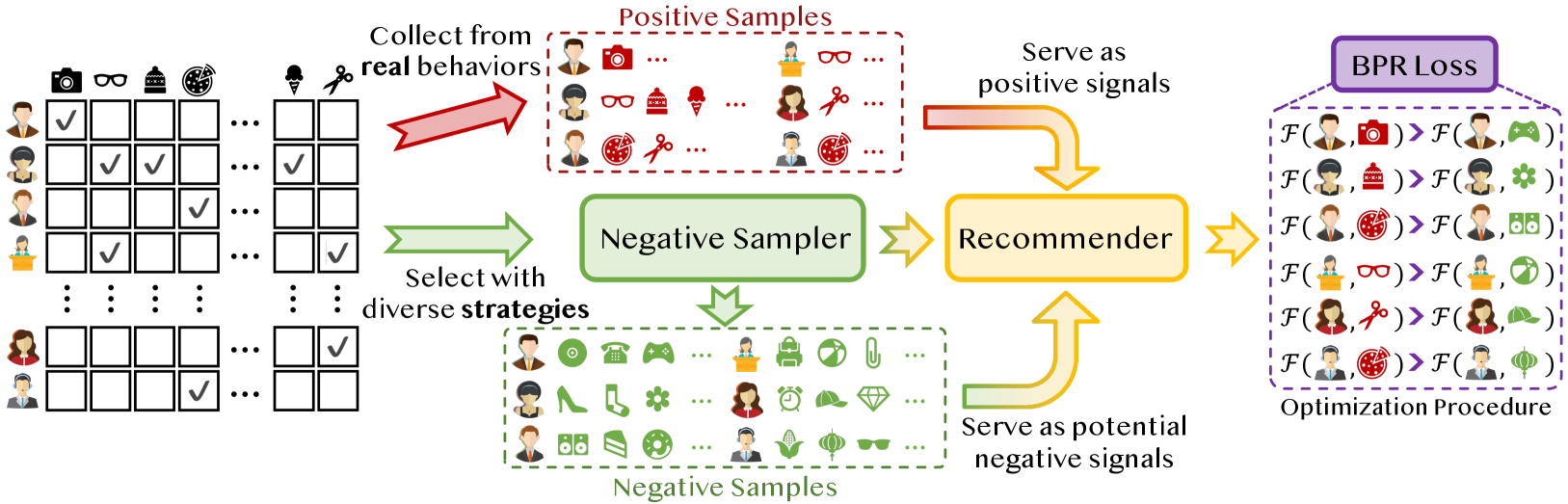
Negative Sampling in Recommendation: A Survey and Future Directions
Haokai Ma, Ruobing Xie, Lei Meng, Fuli Feng, Xiaoyu Du, Xingwu Sun, Zhanhui Kang, Xiangxu Meng
Recommender systems aim to capture users' personalized preferences from the cast amount of user behaviors, making them pivotal in the era of information explosion. However, the presence of the dynamic preference, the information cocoons, and the inherent feedback loops in recommendation make users interact with a limited number of items. Conventional recommendation algorithms typically focus on the positive historical behaviors, while neglecting the essential role of negative feedback in user interest understanding. As a promising but easy-to-ignored area, negative sampling is proficients in revealing the genuine negative aspect inherent in user behaviors, emerging as an inescapable procedure in recommendation. In this survey, we first discuss the role of negative sampling in recommendation and thoroughly analyze challenges that consistently impede its progress. Then, we conduct an extensive literature review on the existing negative sampling strategies in recommendation and classify them into five categories with their discrepant techniques. Finally, we detail the insights of the tailored negative sampling strategies in diverse recommendation scenarios and outline an overview of the prospective research directions toward which the community may engage and benefit.
Read more9/12/2024