Enhancing Test Time Adaptation with Few-shot Guidance

0

Sign in to get full access
Overview
- This paper introduces an approach to enhance test-time adaptation with few-shot guidance.
- The key ideas are to leverage a small set of labeled examples at test time to guide the adaptation process, and to combine this with an uncertainty-aware adaptation framework.
- The proposed method is evaluated on several computer vision tasks and shown to outperform existing test-time adaptation techniques.
Plain English Explanation
The paper explores a way to improve the performance of machine learning models when they are applied to new, unseen data. This process is called "test-time adaptation."
Typically, test-time adaptation tries to adjust the model on the fly to work better with the new data, without requiring any extra labeled examples. However, the paper on test-time adaptation with few-shot guidance proposes a different approach - it suggests using a small set of labeled examples to guide the adaptation process.
The key idea is that by providing the model with a few representative examples from the new data, it can better understand the characteristics of that data and adapt more effectively. This is combined with an "uncertainty-aware" adaptation framework, which helps the model determine which parts of the new data it is most uncertain about and focus the adaptation on those areas.
Overall, this method is shown to outperform existing test-time adaptation techniques across a range of computer vision tasks. It provides a way to get better performance from machine learning models when they are deployed in the real world, where the data they encounter may differ from what they were trained on.
Technical Explanation
The paper introduces a novel approach called "Few-Shot Guided Test-Time Adaptation" (FSGTA) to enhance the performance of machine learning models at test time.
The core components of FSGTA are:
-
Few-Shot Guidance: At test time, the model is provided with a small set of labeled examples from the target domain. This "few-shot guidance" helps the model better understand the characteristics of the new data and adapt accordingly.
-
Uncertainty-Aware Adaptation: The adaptation process is guided by the model's own uncertainty about its predictions on the target data. Areas where the model is most uncertain are given more focus during adaptation.
-
Optimization-Based Adaptation: The model parameters are updated through an optimization-based adaptation procedure that aims to minimize the loss on both the few-shot guidance examples and the unlabeled target data.
The authors evaluate FSGTA on several computer vision tasks, including image classification, semantic segmentation, and object detection. Compared to standard test-time adaptation methods, FSGTA is shown to provide significant performance improvements, especially when the domain shift between training and test data is large.
Critical Analysis
One key strength of the FSGTA approach is its ability to leverage a small amount of labeled data at test time to guide the adaptation process. This is an important practical consideration, as obtaining large amounts of labeled data for new domains can be costly and time-consuming.
However, the paper does not extensively explore the sensitivity of the method to the size and quality of the few-shot guidance examples. It would be valuable to understand how much labeled data is needed to see meaningful improvements, and whether the method is robust to noisy or non-representative guidance examples.
Additionally, the paper focuses on computer vision tasks, and it is unclear how well the FSGTA approach would generalize to other domains, such as natural language processing or speech recognition. Further research would be needed to validate the broader applicability of the method.
Finally, the paper does not provide a deeper analysis of the types of domain shifts or data distribution changes that FSGTA is most effective at handling. A more thorough investigation of the method's strengths and limitations in different real-world scenarios would help inform its practical deployment.
Conclusion
The "Few-Shot Guided Test-Time Adaptation" (FSGTA) approach presented in this paper offers a promising way to enhance the performance of machine learning models when they are applied to new, unseen data. By leveraging a small set of labeled examples to guide the adaptation process, and using an uncertainty-aware framework, FSGTA is shown to outperform existing test-time adaptation techniques.
This work has important implications for the real-world deployment of machine learning models, where the data they encounter may differ from the data they were trained on. The FSGTA method provides a practical solution to this domain adaptation challenge, and could help unlock the full potential of these models in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Test Time Adaptation with Few-shot Guidance
Siqi Luo, Yi Xin, Yuntao Du, Zhongwei Wan, Tao Tan, Guangtao Zhai, Xiaohong Liu
Deep neural networks often encounter significant performance drops while facing with domain shifts between training (source) and test (target) data. To address this issue, Test Time Adaptation (TTA) methods have been proposed to adapt pre-trained source model to handle out-of-distribution streaming target data. Although these methods offer some relief, they lack a reliable mechanism for domain shift correction, which can often be erratic in real-world applications. In response, we develop Few-Shot Test Time Adaptation (FS-TTA), a novel and practical setting that utilizes a few-shot support set on top of TTA. Adhering to the principle of few inputs, big gains, FS-TTA reduces blind exploration in unseen target domains. Furthermore, we propose a two-stage framework to tackle FS-TTA, including (i) fine-tuning the pre-trained source model with few-shot support set, along with using feature diversity augmentation module to avoid overfitting, (ii) implementing test time adaptation based on prototype memory bank guidance to produce high quality pseudo-label for model adaptation. Through extensive experiments on three cross-domain classification benchmarks, we demonstrate the superior performance and reliability of our FS-TTA and framework.
Read more9/4/2024

0
Everything to the Synthetic: Diffusion-driven Test-time Adaptation via Synthetic-Domain Alignment
Jiayi Guo, Junhao Zhao, Chunjiang Ge, Chaoqun Du, Zanlin Ni, Shiji Song, Humphrey Shi, Gao Huang
Test-time adaptation (TTA) aims to enhance the performance of source-domain pretrained models when tested on unknown shifted target domains. Traditional TTA methods primarily adapt model weights based on target data streams, making model performance sensitive to the amount and order of target data. Recently, diffusion-driven TTA methods have demonstrated strong performance by using an unconditional diffusion model, which is also trained on the source domain to transform target data into synthetic data as a source domain projection. This allows the source model to make predictions without weight adaptation. In this paper, we argue that the domains of the source model and the synthetic data in diffusion-driven TTA methods are not aligned. To adapt the source model to the synthetic domain of the unconditional diffusion model, we introduce a Synthetic-Domain Alignment (SDA) framework to fine-tune the source model with synthetic data. Specifically, we first employ a conditional diffusion model to generate labeled samples, creating a synthetic dataset. Subsequently, we use the aforementioned unconditional diffusion model to add noise to and denoise each sample before fine-tuning. This process mitigates the potential domain gap between the conditional and unconditional models. Extensive experiments across various models and benchmarks demonstrate that SDA achieves superior domain alignment and consistently outperforms existing diffusion-driven TTA methods. Our code is available at https://github.com/SHI-Labs/Diffusion-Driven-Test-Time-Adaptation-via-Synthetic-Domain-Alignment.
Read more6/7/2024

0
Hybrid-TTA: Continual Test-time Adaptation via Dynamic Domain Shift Detection
Hyewon Park, Hyejin Park, Jueun Ko, Dongbo Min
Continual Test Time Adaptation (CTTA) has emerged as a critical approach for bridging the domain gap between the controlled training environments and the real-world scenarios, enhancing model adaptability and robustness. Existing CTTA methods, typically categorized into Full-Tuning (FT) and Efficient-Tuning (ET), struggle with effectively addressing domain shifts. To overcome these challenges, we propose Hybrid-TTA, a holistic approach that dynamically selects instance-wise tuning method for optimal adaptation. Our approach introduces the Dynamic Domain Shift Detection (DDSD) strategy, which identifies domain shifts by leveraging temporal correlations in input sequences and dynamically switches between FT and ET to adapt to varying domain shifts effectively. Additionally, the Masked Image Modeling based Adaptation (MIMA) framework is integrated to ensure domain-agnostic robustness with minimal computational overhead. Our Hybrid-TTA achieves a notable 1.6%p improvement in mIoU on the Cityscapes-to-ACDC benchmark dataset, surpassing previous state-of-the-art methods and offering a robust solution for real-world continual adaptation challenges.
Read more9/16/2024
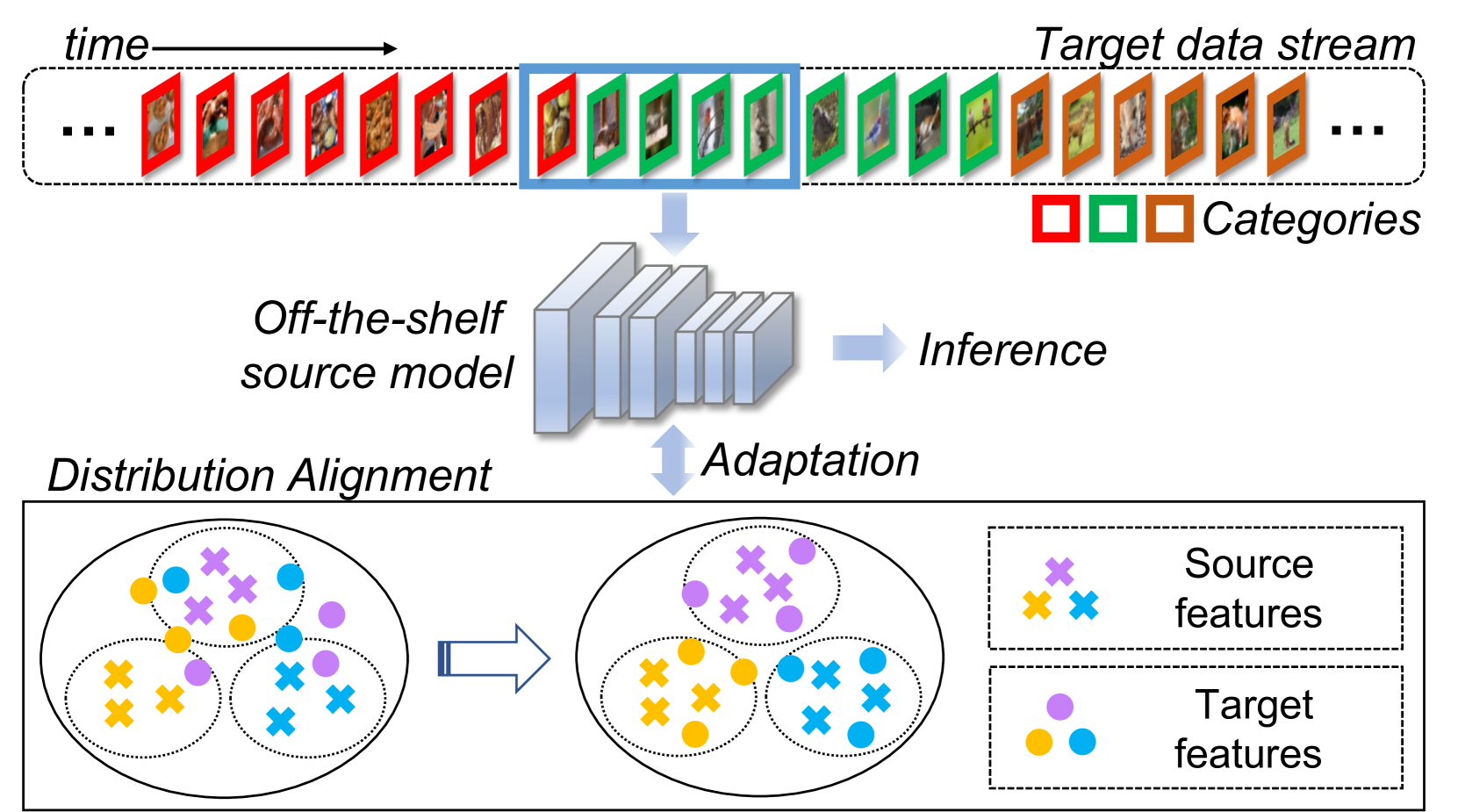
0
Distribution Alignment for Fully Test-Time Adaptation with Dynamic Online Data Streams
Ziqiang Wang, Zhixiang Chi, Yanan Wu, Li Gu, Zhi Liu, Konstantinos Plataniotis, Yang Wang
Given a model trained on source data, Test-Time Adaptation (TTA) enables adaptation and inference in test data streams with domain shifts from the source. Current methods predominantly optimize the model for each incoming test data batch using self-training loss. While these methods yield commendable results in ideal test data streams, where batches are independently and identically sampled from the target distribution, they falter under more practical test data streams that are not independent and identically distributed (non-i.i.d.). The data batches in a non-i.i.d. stream display prominent label shifts relative to each other. It leads to conflicting optimization objectives among batches during the TTA process. Given the inherent risks of adapting the source model to unpredictable test-time distributions, we reverse the adaptation process and propose a novel Distribution Alignment loss for TTA. This loss guides the distributions of test-time features back towards the source distributions, which ensures compatibility with the well-trained source model and eliminates the pitfalls associated with conflicting optimization objectives. Moreover, we devise a domain shift detection mechanism to extend the success of our proposed TTA method in the continual domain shift scenarios. Our extensive experiments validate the logic and efficacy of our method. On six benchmark datasets, we surpass existing methods in non-i.i.d. scenarios and maintain competitive performance under the ideal i.i.d. assumption.
Read more7/18/2024