Enhancing Uncertainty Quantification in Drug Discovery with Censored Regression Labels

0

Sign in to get full access
Overview
- This paper explores how to enhance uncertainty quantification in drug discovery using censored regression labels.
- The researchers propose a method to account for censored data, which occurs when the true value of a measurement is only known to be above or below a certain threshold.
- This approach aims to improve the reliability and accuracy of machine learning models used in drug discovery and development.
Plain English Explanation
The paper focuses on a challenge in drug discovery called uncertainty quantification. This refers to the need to understand how confident we can be in the predictions made by machine learning models used in the drug development process.
One issue that can affect this is censored data. This happens when the true value of a measurement (like the potency of a drug compound) is only known to be above or below a certain threshold, rather than a precise number.
The researchers propose a new method to account for censored data when training machine learning models for drug discovery. This aims to make the model's predictions more reliable and better reflect the true underlying uncertainty.
By improving uncertainty quantification, this approach could lead to better decision-making in the costly and risky drug development process. It could help researchers focus resources on the most promising compounds and avoid pursuing dead ends.
Technical Explanation
The key innovation in this paper is the use of censored regression to handle censored labels in machine learning models for drug discovery.
Censored data occurs when the true value of a measurement is only known to be above or below a certain threshold. This is common in drug discovery, where the potency of a compound may only be reported as greater than a minimum inhibitory concentration.
The researchers propose modifying standard regression models to explicitly account for this censored information. This involves formulating the loss function to penalize errors based on whether the prediction is above or below the censoring threshold, rather than the exact value.
They demonstrate this approach on several drug discovery datasets, showing that it can improve the calibration and discrimination of the model's uncertainty estimates compared to standard regression. This suggests the censored regression method can lead to more reliable and informative uncertainty quantification.
Critical Analysis
The paper provides a rigorous technical explanation of the censored regression approach and its benefits for drug discovery applications. The experimental results appear to support the claims about improved uncertainty quantification.
However, the authors note some limitations to their work. The method assumes the censoring thresholds are known, which may not always be the case in practice. They also only evaluate on a few specific datasets, so more research is needed to assess the broader applicability.
Additionally, the paper does not address potential issues around interpretability or the "black box" nature of the machine learning models. Uncertainty estimates alone may not be enough - there could also be value in making the models more transparent and explainable to domain experts.
Overall, this research represents a valuable contribution to enhancing the reliability of machine learning in drug discovery. But further work is likely needed to fully realize the potential of this approach in real-world pharmaceutical R&D workflows.
Conclusion
This paper introduces a censored regression technique to improve uncertainty quantification in machine learning models for drug discovery. By explicitly accounting for censored data, the method can produce more reliable and informative uncertainty estimates.
The authors demonstrate the benefits of this approach on several drug discovery datasets. This suggests it could lead to better decision-making in the costly and risky drug development process, helping researchers focus resources on the most promising compounds.
While the technical details are complex, the core idea is relatively straightforward - improving how machine learning models handle noisy, incomplete data to provide more trustworthy predictions. As AI continues to play a growing role in pharmaceutical R&D, techniques like this will be crucial for realizing the full potential of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Uncertainty Quantification in Drug Discovery with Censored Regression Labels
Emma Svensson, Hannah Rosa Friesacher, Susanne Winiwarter, Lewis Mervin, Adam Arany, Ola Engkvist
In the early stages of drug discovery, decisions regarding which experiments to pursue can be influenced by computational models. These decisions are critical due to the time-consuming and expensive nature of the experiments. Therefore, it is becoming essential to accurately quantify the uncertainty in machine learning predictions, such that resources can be used optimally and trust in the models improves. While computational methods for drug discovery often suffer from limited data and sparse experimental observations, additional information can exist in the form of censored labels that provide thresholds rather than precise values of observations. However, the standard approaches that quantify uncertainty in machine learning cannot fully utilize censored labels. In this work, we adapt ensemble-based, Bayesian, and Gaussian models with tools to learn from censored labels by using the Tobit model from survival analysis. Our results demonstrate that despite the partial information available in censored labels, they are essential to accurately and reliably model the real pharmaceutical setting.
Read more9/9/2024
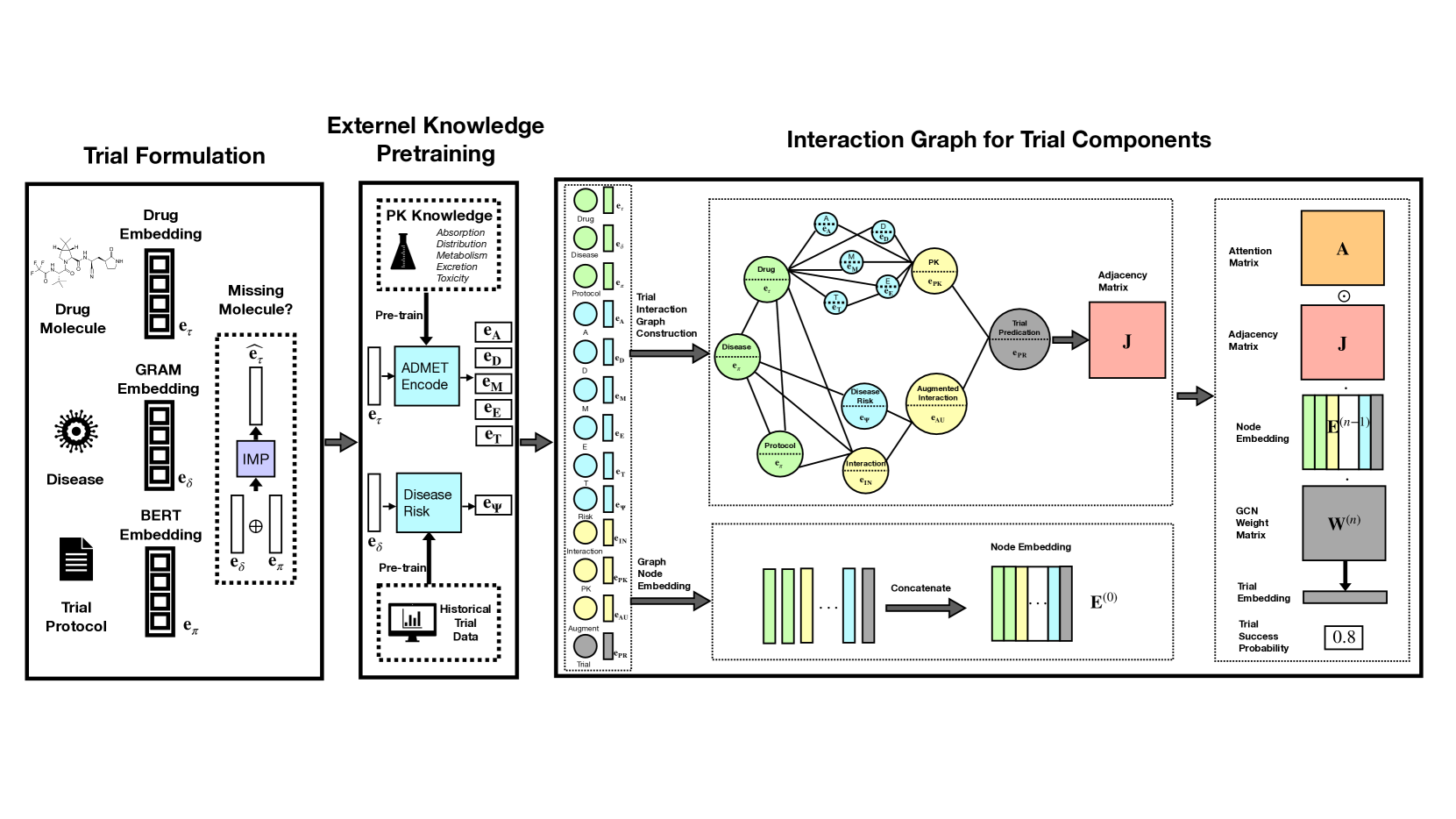
0
Uncertainty Quantification on Clinical Trial Outcome Prediction
Tianyi Chen, Yingzhou Lu, Nan Hao, Capucine Van Rechem, Jintai Chen, Tianfan Fu
The importance of uncertainty quantification is increasingly recognized in the diverse field of machine learning. Accurately assessing model prediction uncertainty can help provide deeper understanding and confidence for researchers and practitioners. This is especially critical in medical diagnosis and drug discovery areas, where reliable predictions directly impact research quality and patient health. In this paper, we proposed incorporating uncertainty quantification into clinical trial outcome predictions. Our main goal is to enhance the model's ability to discern nuanced differences, thereby significantly improving its overall performance. We have adopted a selective classification approach to fulfill our objective, integrating it seamlessly with the Hierarchical Interaction Network (HINT), which is at the forefront of clinical trial prediction modeling. Selective classification, encompassing a spectrum of methods for uncertainty quantification, empowers the model to withhold decision-making in the face of samples marked by ambiguity or low confidence, thereby amplifying the accuracy of predictions for the instances it chooses to classify. A series of comprehensive experiments demonstrate that incorporating selective classification into clinical trial predictions markedly enhances the model's performance, as evidenced by significant upticks in pivotal metrics such as PR-AUC, F1, ROC-AUC, and overall accuracy. Specifically, the proposed method achieved 32.37%, 21.43%, and 13.27% relative improvement on PR-AUC over the base model (HINT) in phase I, II, and III trial outcome prediction, respectively. When predicting phase III, our method reaches 0.9022 PR-AUC scores. These findings illustrate the robustness and prospective utility of this strategy within the area of clinical trial predictions, potentially setting a new benchmark in the field.
Read more6/19/2024

0
Improving Label Error Detection and Elimination with Uncertainty Quantification
Johannes Jakubik, Michael Vossing, Manil Maskey, Christopher Wolfle, Gerhard Satzger
Identifying and handling label errors can significantly enhance the accuracy of supervised machine learning models. Recent approaches for identifying label errors demonstrate that a low self-confidence of models with respect to a certain label represents a good indicator of an erroneous label. However, latest work has built on softmax probabilities to measure self-confidence. In this paper, we argue that -- as softmax probabilities do not reflect a model's predictive uncertainty accurately -- label error detection requires more sophisticated measures of model uncertainty. Therefore, we develop a range of novel, model-agnostic algorithms for Uncertainty Quantification-Based Label Error Detection (UQ-LED), which combine the techniques of confident learning (CL), Monte Carlo Dropout (MCD), model uncertainty measures (e.g., entropy), and ensemble learning to enhance label error detection. We comprehensively evaluate our algorithms on four image classification benchmark datasets in two stages. In the first stage, we demonstrate that our UQ-LED algorithms outperform state-of-the-art confident learning in identifying label errors. In the second stage, we show that removing all identified errors from the training data based on our approach results in higher accuracies than training on all available labeled data. Importantly, besides our contributions to the detection of label errors, we particularly propose a novel approach to generate realistic, class-dependent label errors synthetically. Overall, our study demonstrates that selectively cleaning datasets with UQ-LED algorithms leads to more accurate classifications than using larger, noisier datasets.
Read more5/17/2024

0
Uncertainty Quantification Using Ensemble Learning and Monte Carlo Sampling for Performance Prediction and Monitoring in Cell Culture Processes
Thanh Tung Khuat, Robert Bassett, Ellen Otte, Bogdan Gabrys
Biopharmaceutical products, particularly monoclonal antibodies (mAbs), have gained prominence in the pharmaceutical market due to their high specificity and efficacy. As these products are projected to constitute a substantial portion of global pharmaceutical sales, the application of machine learning models in mAb development and manufacturing is gaining momentum. This paper addresses the critical need for uncertainty quantification in machine learning predictions, particularly in scenarios with limited training data. Leveraging ensemble learning and Monte Carlo simulations, our proposed method generates additional input samples to enhance the robustness of the model in small training datasets. We evaluate the efficacy of our approach through two case studies: predicting antibody concentrations in advance and real-time monitoring of glucose concentrations during bioreactor runs using Raman spectra data. Our findings demonstrate the effectiveness of the proposed method in estimating the uncertainty levels associated with process performance predictions and facilitating real-time decision-making in biopharmaceutical manufacturing. This contribution not only introduces a novel approach for uncertainty quantification but also provides insights into overcoming challenges posed by small training datasets in bioprocess development. The evaluation demonstrates the effectiveness of our method in addressing key challenges related to uncertainty estimation within upstream cell cultivation, illustrating its potential impact on enhancing process control and product quality in the dynamic field of biopharmaceuticals.
Read more9/5/2024