Enhancing Visible-Infrared Person Re-identification with Modality- and Instance-aware Visual Prompt Learning

0
Sign in to get full access
Overview
- This paper presents a novel approach for enhancing visible-infrared person re-identification using modality- and instance-aware visual prompt learning.
- The proposed method aims to address the challenge of cross-modality person re-identification, where the goal is to match person images captured in visible and infrared spectrums.
- The key contributions include a modality-aware visual prompt learning module and an instance-aware visual prompt learning module, which work together to enhance the person re-identification performance.
Plain English Explanation
The paper explores a way to improve the process of visible-infrared person re-identification, which is the task of matching a person's image captured in the visible spectrum (like a regular photo) with their image captured in the infrared spectrum (like a thermal image). This is a challenging problem because the two types of images can look quite different.
The researchers developed a new method that uses "visual prompts" - special instructions or cues that help the AI system better understand and process the images. These visual prompts are designed to be aware of the differences between the visible and infrared modalities, as well as the unique characteristics of each individual person's appearance. By incorporating this modality- and instance-specific information, the system can make more accurate matches between visible and infrared person images.
The key ideas are:
- Modality-aware visual prompts: The system learns to recognize the differences between visible and infrared images, and uses this knowledge to guide the matching process.
- Instance-aware visual prompts: The system also learns about the unique visual features of each individual person, allowing it to differentiate between people more effectively.
By combining these two types of visual prompts, the researchers were able to significantly improve the performance of visible-infrared person re-identification compared to previous methods.
Technical Explanation
The paper proposes a novel framework for visible-infrared person re-identification that leverages modality- and instance-aware visual prompt learning.
The key components of the framework are:
-
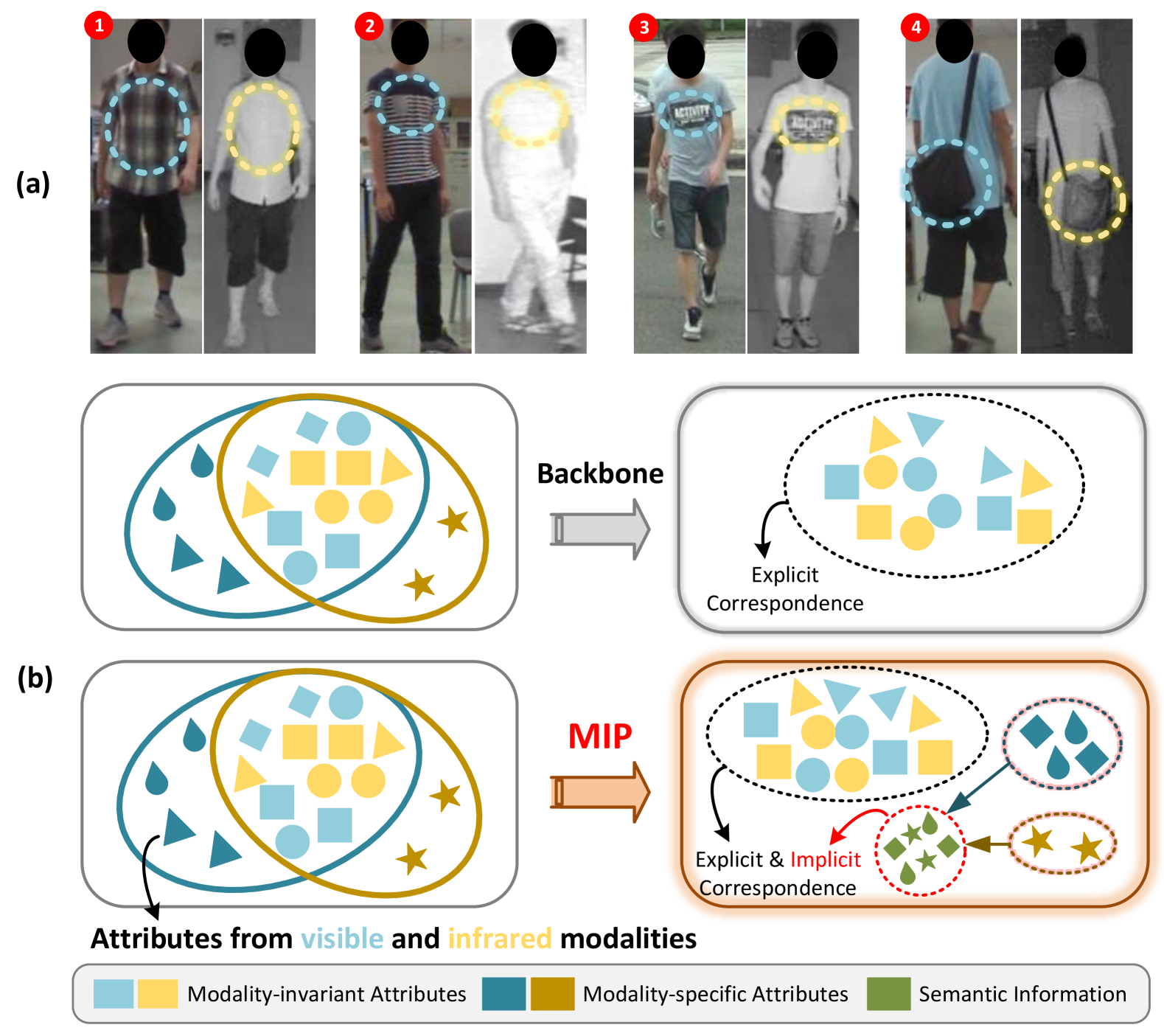
Modality-aware Visual Prompt Learning: This module learns prompts that capture the modality-specific characteristics of visible and infrared person images. By explicitly modeling the differences between the two modalities, the system can better align the feature representations and improve cross-modality matching.
-
Instance-aware Visual Prompt Learning: This module learns prompts that capture the unique visual features of each individual person. By modeling the instance-specific information, the system can better differentiate between people and enhance the re-identification performance.
-
Joint Optimization: The modality-aware and instance-aware visual prompt learning modules are jointly optimized to ensure that the learned prompts are effective for cross-modality person re-identification.
The proposed framework is evaluated on several visible-infrared person re-identification benchmarks, including SYSU-MM01, RegDB, and Reg-DBIR. The results demonstrate that the proposed method outperforms state-of-the-art approaches for cross-modality person re-identification.
Critical Analysis
The paper presents a compelling approach for enhancing visible-infrared person re-identification, but there are a few potential limitations and areas for further research:
-
Generalization to other domains: The proposed method is evaluated on a limited set of benchmark datasets, and it would be interesting to see how it performs on a wider range of visible-infrared person re-identification scenarios, such as those with different environmental conditions or camera setups.
-
Interpretability of visual prompts: While the modality- and instance-aware visual prompts are shown to be effective, it may be valuable to provide more insight into what specific visual cues or patterns they are capturing, which could lead to a better understanding of the underlying challenges in cross-modality person re-identification.
-
Computational efficiency: The additional computational overhead introduced by the visual prompt learning modules may be a concern, especially for real-world applications that require fast and efficient person re-identification. Exploring ways to optimize the model's performance without sacrificing accuracy would be a valuable direction for future research.
Overall, the paper presents a well-designed and promising approach for enhancing visible-infrared person re-identification, and the findings could have important implications for a wide range of applications, from surveillance and security to assistive technologies.
Conclusion
This paper introduces a novel framework for improving visible-infrared person re-identification by leveraging modality- and instance-aware visual prompt learning. The proposed approach outperforms state-of-the-art methods on several benchmark datasets, demonstrating the effectiveness of the modality-aware and instance-aware visual prompts in addressing the challenges of cross-modality person matching.
The key innovations of this work are the modality-aware and instance-aware visual prompt learning modules, which enable the system to better align feature representations and differentiate between individuals across the visible and infrared spectrums. This advance could have significant implications for a variety of applications, such as surveillance, security, and assistive technologies, where accurate person re-identification is crucial.
While the paper presents a promising solution, there are still opportunities for further research to address potential limitations, such as exploring the generalization to other domains, providing more interpretability of the visual prompts, and optimizing the computational efficiency. Overall, this work represents an important step forward in the field of cross-modality person re-identification and opens up exciting avenues for future exploration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Visible-Infrared Person Re-identification with Modality- and Instance-aware Visual Prompt Learning
Ruiqi Wu, Bingliang Jiao, Wenxuan Wang, Meng Liu, Peng Wang
The Visible-Infrared Person Re-identification (VI ReID) aims to match visible and infrared images of the same pedestrians across non-overlapped camera views. These two input modalities contain both invariant information, such as shape, and modality-specific details, such as color. An ideal model should utilize valuable information from both modalities during training for enhanced representational capability. However, the gap caused by modality-specific information poses substantial challenges for the VI ReID model to handle distinct modality inputs simultaneously. To address this, we introduce the Modality-aware and Instance-aware Visual Prompts (MIP) network in our work, designed to effectively utilize both invariant and specific information for identification. Specifically, our MIP model is built on the transformer architecture. In this model, we have designed a series of modality-specific prompts, which could enable our model to adapt to and make use of the specific information inherent in different modality inputs, thereby reducing the interference caused by the modality gap and achieving better identification. Besides, we also employ each pedestrian feature to construct a group of instance-specific prompts. These customized prompts are responsible for guiding our model to adapt to each pedestrian instance dynamically, thereby capturing identity-level discriminative clues for identification. Through extensive experiments on SYSU-MM01 and RegDB datasets, the effectiveness of both our designed modules is evaluated. Additionally, our proposed MIP performs better than most state-of-the-art methods.
Read more6/19/2024
🏷️
0
Visible-Infrared Person Re-Identification via Patch-Mixed Cross-Modality Learning
Zhihao Qian, Yutian Lin, Bo Du
Visible-infrared person re-identification (VI-ReID) aims to retrieve images of the same pedestrian from different modalities, where the challenges lie in the significant modality discrepancy. To alleviate the modality gap, recent methods generate intermediate images by GANs, grayscaling, or mixup strategies. However, these methods could introduce extra data distribution, and the semantic correspondence between the two modalities is not well learned. In this paper, we propose a Patch-Mixed Cross-Modality framework (PMCM), where two images of the same person from two modalities are split into patches and stitched into a new one for model learning. A part-alignment loss is introduced to regularize representation learning, and a patch-mixed modality learning loss is proposed to align between the modalities. In this way, the model learns to recognize a person through patches of different styles, thereby the modality semantic correspondence can be inferred. In addition, with the flexible image generation strategy, the patch-mixed images freely adjust the ratio of different modality patches, which could further alleviate the modality imbalance problem. On two VI-ReID datasets, we report new state-of-the-art performance with the proposed method.
Read more5/1/2024
🌐
0
Dynamic Identity-Guided Attention Network for Visible-Infrared Person Re-identification
Peng Gao, Yujian Lee, Hui Zhang, Xubo Liu, Yiyang Hu, Guquan Jing
Visible-infrared person re-identification (VI-ReID) aims to match people with the same identity between visible and infrared modalities. VI-ReID is a challenging task due to the large differences in individual appearance under different modalities. Existing methods generally try to bridge the cross-modal differences at image or feature level, which lacks exploring the discriminative embeddings. Effectively minimizing these cross-modal discrepancies relies on obtaining representations that are guided by identity and consistent across modalities, while also filtering out representations that are irrelevant to identity. To address these challenges, we introduce a dynamic identity-guided attention network (DIAN) to mine identity-guided and modality-consistent embeddings, facilitating effective bridging the gap between different modalities. Specifically, in DIAN, to pursue a semantically richer representation, we first use orthogonal projection to fuse the features from two connected coarse and fine layers. Furthermore, we first use dynamic convolution kernels to mine identity-guided and modality-consistent representations. More notably, a cross embedding balancing loss is introduced to effectively bridge cross-modal discrepancies by above embeddings. Experimental results on SYSU-MM01 and RegDB datasets show that DIAN achieves state-of-the-art performance. Specifically, for indoor search on SYSU-MM01, our method achieves 86.28% rank-1 accuracy and 87.41% mAP, respectively. Our code will be available soon.
Read more7/23/2024

0
Unsupervised Visible-Infrared ReID via Pseudo-label Correction and Modality-level Alignment
Yexin Liu, Weiming Zhang, Athanasios V. Vasilakos, Lin Wang
Unsupervised visible-infrared person re-identification (UVI-ReID) has recently gained great attention due to its potential for enhancing human detection in diverse environments without labeling. Previous methods utilize intra-modality clustering and cross-modality feature matching to achieve UVI-ReID. However, there exist two challenges: 1) noisy pseudo labels might be generated in the clustering process, and 2) the cross-modality feature alignment via matching the marginal distribution of visible and infrared modalities may misalign the different identities from two modalities. In this paper, we first conduct a theoretic analysis where an interpretable generalization upper bound is introduced. Based on the analysis, we then propose a novel unsupervised cross-modality person re-identification framework (PRAISE). Specifically, to address the first challenge, we propose a pseudo-label correction strategy that utilizes a Beta Mixture Model to predict the probability of mis-clustering based network's memory effect and rectifies the correspondence by adding a perceptual term to contrastive learning. Next, we introduce a modality-level alignment strategy that generates paired visible-infrared latent features and reduces the modality gap by aligning the labeling function of visible and infrared features to learn identity discriminative and modality-invariant features. Experimental results on two benchmark datasets demonstrate that our method achieves state-of-the-art performance than the unsupervised visible-ReID methods.
Read more4/11/2024