Entity Augmentation for Efficient Classification of Vertically Partitioned Data with Limited Overlap
2406.17899
0
0

Abstract
Vertical Federated Learning (VFL) is a machine learning paradigm for learning from vertically partitioned data (i.e. features for each input are distributed across multiple guest clients and an aggregating host server owns labels) without communicating raw data. Traditionally, VFL involves an entity resolution phase where the host identifies and serializes the unique entities known to all guests. This is followed by private set intersection to find common entities, and an entity alignment step to ensure all guests are always processing the same entity's data. However, using only data of entities from the intersection means guests discard potentially useful data. Besides, the effect on privacy is dubious and these operations are computationally expensive. We propose a novel approach that eliminates the need for set intersection and entity alignment in categorical tasks. Our Entity Augmentation technique generates meaningful labels for activations sent to the host, regardless of their originating entity, enabling efficient VFL without explicit entity alignment. With limited overlap between training data, this approach performs substantially better (e.g. with 5% overlap, 48.1% vs 69.48% test accuracy on CIFAR-10). In fact, thanks to the regularizing effect, our model performs marginally better even with 100% overlap.
Create account to get full access
Overview
- This paper proposes an approach called "Entity Augmentation" to improve the classification performance of vertically partitioned data with limited overlap.
- Vertically partitioned data refers to a scenario where different data features are stored on different machines, making it challenging to train machine learning models effectively.
- The key idea is to generate synthetic data samples that augment the existing data, helping the model learn better representations and achieve higher classification accuracy.
Plain English Explanation
The paper tackles a common problem in Vertical Federated Learning - where data is split across different machines, making it hard to train models effectively. To address this, the researchers developed a technique called "Entity Augmentation" that generates new, synthetic data samples to supplement the limited original data.
Imagine you have a dataset about people, where one machine has information about their ages and incomes, and another machine has data about their education levels and job titles. Individually, these datasets are incomplete, but together they could paint a more comprehensive picture. The challenge is how to train a model to classify people into different groups when the data is split this way.
The Entity Augmentation approach tries to solve this by creating new, realistic-looking data samples that fill in the gaps. So for example, it might generate some fictional people with plausible combinations of age, income, education, and job title. This augmented dataset can then be used to train a more powerful classification model, even when the original data was limited.
The key insight is that by generating this synthetic data, the model can learn better representations of the underlying entities (in this case, the people) and make more accurate predictions, even with the constraints of vertically partitioned data.
Technical Explanation
The core of the Entity Augmentation approach is a generative model that learns to produce new data samples that are statistically similar to the original, vertically partitioned data. This model is trained using a novel adversarial learning framework that encourages the generated samples to be indistinguishable from the real data.
Specifically, the authors propose a Vertical Federated Learning architecture where each party (i.e., data owner) trains a local generative model on their portion of the data. These local models are then combined into a global model that can generate entity-level samples capturing the relationships across all the vertically partitioned features.
The generated samples are then used to augment the original training data, allowing a downstream classification model to learn more robust and generalizable representations. The authors demonstrate the effectiveness of this approach through extensive experiments on real-world datasets, showing significant improvements in classification accuracy compared to alternative methods.
Critical Analysis
The Entity Augmentation approach presented in this paper is a promising solution for addressing the challenges of Vertical Federated Learning with limited data overlap. By generating synthetic samples to supplement the original data, the model can learn better representations and achieve higher classification performance.
One potential limitation of the approach is the complexity of the generative model and the associated training process. The authors mention that the local and global models need to be carefully designed and optimized, which may require significant computational resources and domain expertise. Additionally, the quality and statistical fidelity of the generated samples could be an area for further investigation and improvement.
Another consideration is the potential privacy implications of generating and sharing synthetic data samples, even if they are designed to be statistically similar to the original data. The TabVFL approach, for example, explores ways to improve latent representations in Vertical Federated Learning while preserving privacy. Exploring the balance between data augmentation and privacy preservation could be a fruitful direction for future research.
Conclusion
The Entity Augmentation technique presented in this paper is a valuable contribution to the field of Vertical Federated Learning, addressing the challenge of limited data overlap across vertically partitioned data sources. By generating synthetic samples to augment the original data, the model can learn more robust representations and achieve higher classification accuracy.
This work has important implications for various applications where data is distributed across multiple parties, such as in healthcare, finance, and smart city initiatives. The ability to train effective models despite data fragmentation can unlock new opportunities for collaborative learning and decision-making, while still preserving the privacy and autonomy of individual data owners.
As the field of Vertical Federated Learning continues to evolve, the insights and techniques presented in this paper can serve as a valuable foundation for future research and development in this critical area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Scalable Vertical Federated Learning via Data Augmentation and Amortized Inference
Conor Hassan, Matthew Sutton, Antonietta Mira, Kerrie Mengersen
0
0
Vertical federated learning (VFL) has emerged as a paradigm for collaborative model estimation across multiple clients, each holding a distinct set of covariates. This paper introduces the first comprehensive framework for fitting Bayesian models in the VFL setting. We propose a novel approach that leverages data augmentation techniques to transform VFL problems into a form compatible with existing Bayesian federated learning algorithms. We present an innovative model formulation for specific VFL scenarios where the joint likelihood factorizes into a product of client-specific likelihoods. To mitigate the dimensionality challenge posed by data augmentation, which scales with the number of observations and clients, we develop a factorized amortized variational approximation that achieves scalability independent of the number of observations. We showcase the efficacy of our framework through extensive numerical experiments on logistic regression, multilevel regression, and a novel hierarchical Bayesian split neural net model. Our work paves the way for privacy-preserving, decentralized Bayesian inference in vertically partitioned data scenarios, opening up new avenues for research and applications in various domains.
5/8/2024
Vertical Federated Learning Hybrid Local Pre-training
Wenguo Li, Xinling Guo, Xu Jiao, Tiancheng Huang, Xiaoran Yan, Yao Yang
0
0
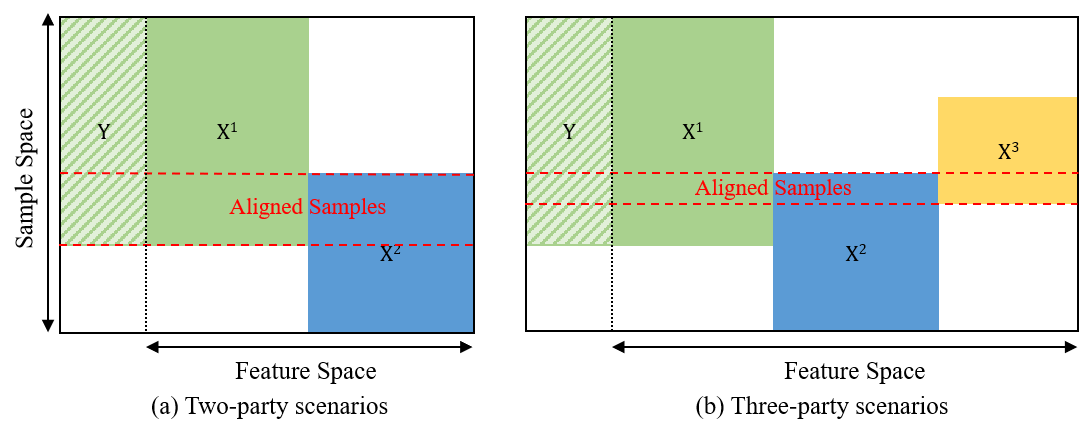
Vertical Federated Learning (VFL), which has a broad range of real-world applications, has received much attention in both academia and industry. Enterprises aspire to exploit more valuable features of the same users from diverse departments to boost their model prediction skills. VFL addresses this demand and concurrently secures individual parties from exposing their raw data. However, conventional VFL encounters a bottleneck as it only leverages aligned samples, whose size shrinks with more parties involved, resulting in data scarcity and the waste of unaligned data. To address this problem, we propose a novel VFL Hybrid Local Pre-training (VFLHLP) approach. VFLHLP first pre-trains local networks on the local data of participating parties. Then it utilizes these pre-trained networks to adjust the sub-model for the labeled party or enhance representation learning for other parties during downstream federated learning on aligned data, boosting the performance of federated models. The experimental results on real-world advertising datasets, demonstrate that our approach achieves the best performance over baseline methods by large margins. The ablation study further illustrates the contribution of each technique in VFLHLP to its overall performance.
5/22/2024
TabVFL: Improving Latent Representation in Vertical Federated Learning
Mohamed Rashad, Zilong Zhao, Jeremie Decouchant, Lydia Y. Chen
0
0
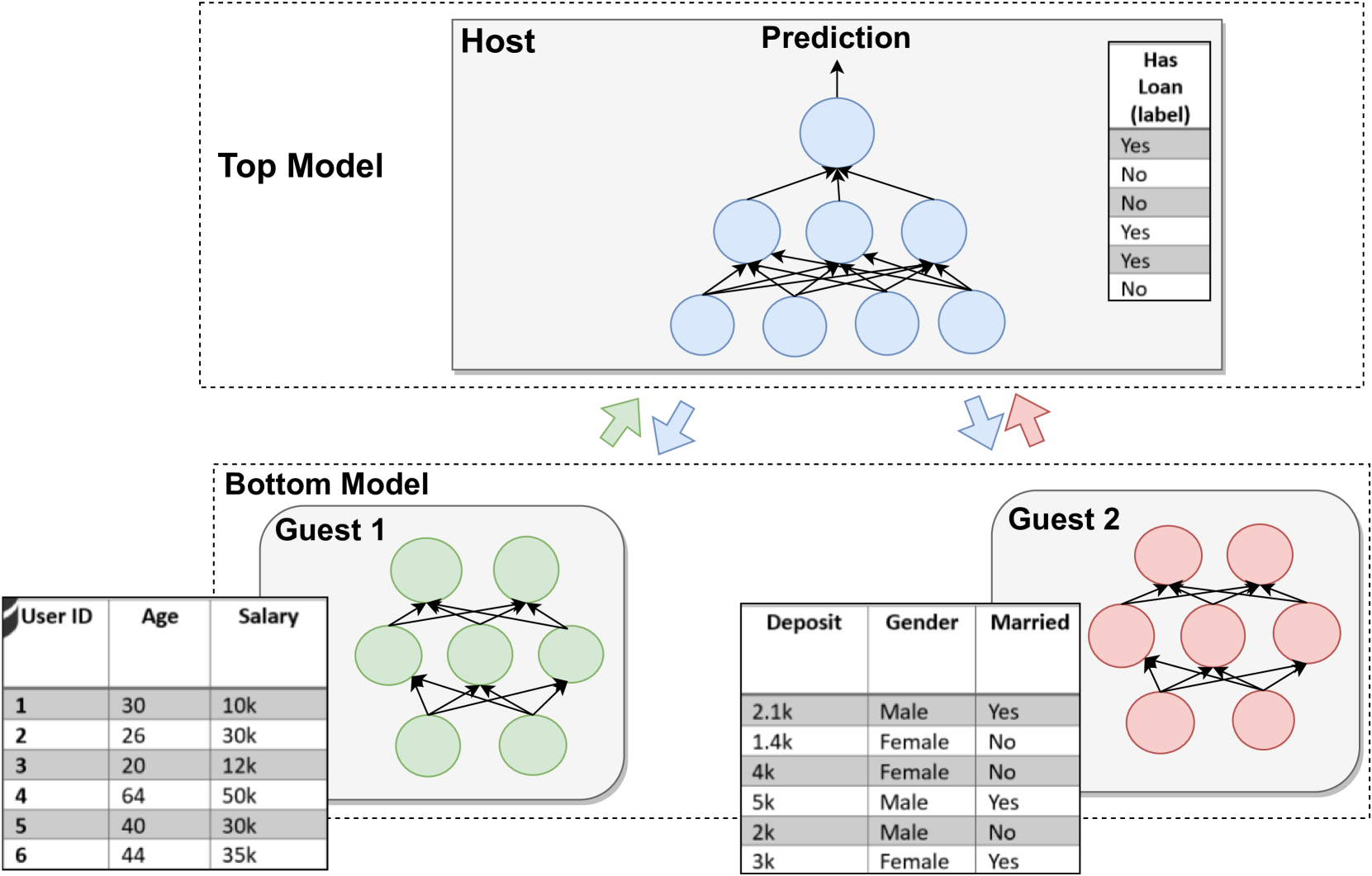
Autoencoders are popular neural networks that are able to compress high dimensional data to extract relevant latent information. TabNet is a state-of-the-art neural network model designed for tabular data that utilizes an autoencoder architecture for training. Vertical Federated Learning (VFL) is an emerging distributed machine learning paradigm that allows multiple parties to train a model collaboratively on vertically partitioned data while maintaining data privacy. The existing design of training autoencoders in VFL is to train a separate autoencoder in each participant and aggregate the latent representation later. This design could potentially break important correlations between feature data of participating parties, as each autoencoder is trained on locally available features while disregarding the features of others. In addition, traditional autoencoders are not specifically designed for tabular data, which is ubiquitous in VFL settings. Moreover, the impact of client failures during training on the model robustness is under-researched in the VFL scene. In this paper, we propose TabVFL, a distributed framework designed to improve latent representation learning using the joint features of participants. The framework (i) preserves privacy by mitigating potential data leakage with the addition of a fully-connected layer, (ii) conserves feature correlations by learning one latent representation vector, and (iii) provides enhanced robustness against client failures during training phase. Extensive experiments on five classification datasets show that TabVFL can outperform the prior work design, with 26.12% of improvement on f1-score.
4/30/2024
Vertical Federated Learning for Effectiveness, Security, Applicability: A Survey
Mang Ye, Wei Shen, Bo Du, Eduard Snezhko, Vassili Kovalev, Pong C. Yuen
0
0
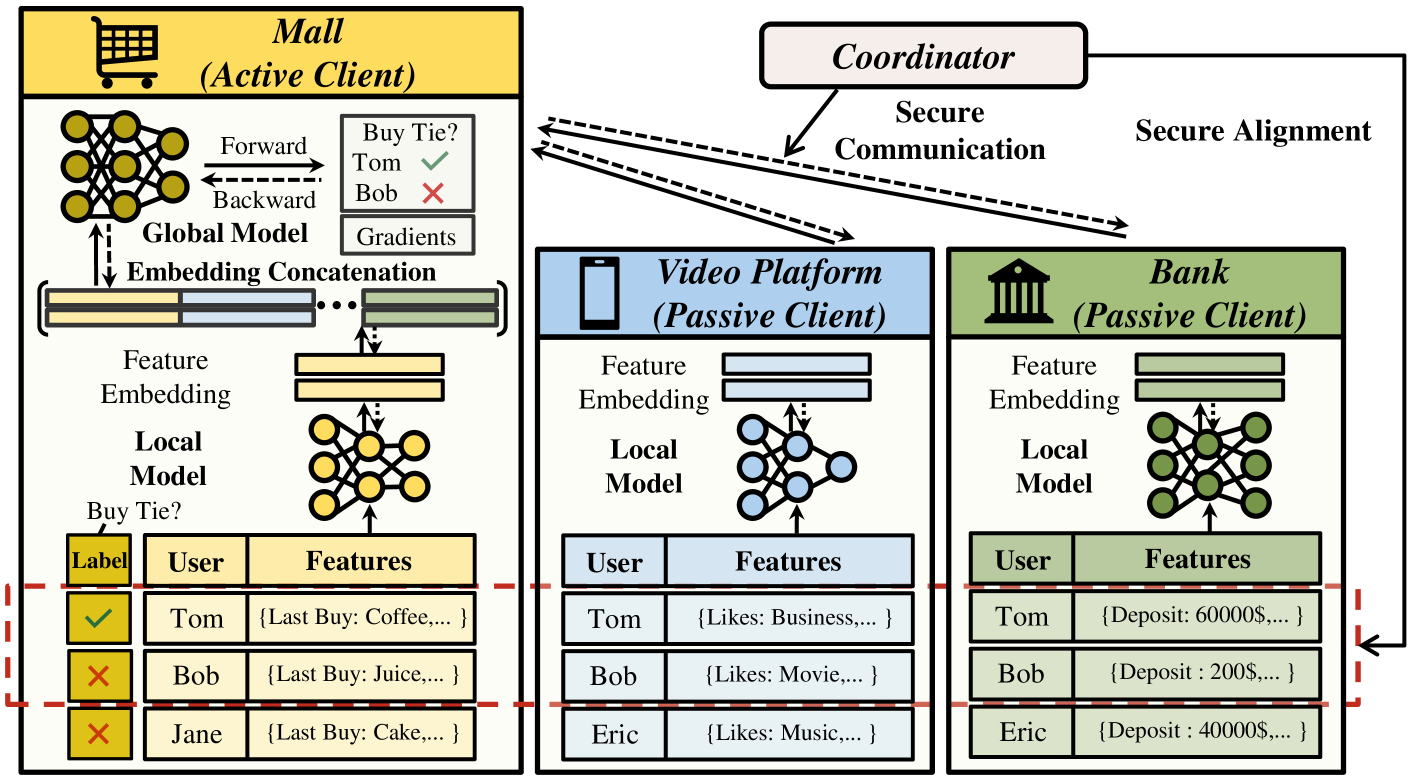
Vertical Federated Learning (VFL) is a privacy-preserving distributed learning paradigm where different parties collaboratively learn models using partitioned features of shared samples, without leaking private data. Recent research has shown promising results addressing various challenges in VFL, highlighting its potential for practical applications in cross-domain collaboration. However, the corresponding research is scattered and lacks organization. To advance VFL research, this survey offers a systematic overview of recent developments. First, we provide a history and background introduction, along with a summary of the general training protocol of VFL. We then revisit the taxonomy in recent reviews and analyze limitations in-depth. For a comprehensive and structured discussion, we synthesize recent research from three fundamental perspectives: effectiveness, security, and applicability. Finally, we discuss several critical future research directions in VFL, which will facilitate the developments in this field. We provide a collection of research lists and periodically update them at https://github.com/shentt67/VFL_Survey.
6/5/2024