TabVFL: Improving Latent Representation in Vertical Federated Learning
2404.17990
0
0
Abstract
Autoencoders are popular neural networks that are able to compress high dimensional data to extract relevant latent information. TabNet is a state-of-the-art neural network model designed for tabular data that utilizes an autoencoder architecture for training. Vertical Federated Learning (VFL) is an emerging distributed machine learning paradigm that allows multiple parties to train a model collaboratively on vertically partitioned data while maintaining data privacy. The existing design of training autoencoders in VFL is to train a separate autoencoder in each participant and aggregate the latent representation later. This design could potentially break important correlations between feature data of participating parties, as each autoencoder is trained on locally available features while disregarding the features of others. In addition, traditional autoencoders are not specifically designed for tabular data, which is ubiquitous in VFL settings. Moreover, the impact of client failures during training on the model robustness is under-researched in the VFL scene. In this paper, we propose TabVFL, a distributed framework designed to improve latent representation learning using the joint features of participants. The framework (i) preserves privacy by mitigating potential data leakage with the addition of a fully-connected layer, (ii) conserves feature correlations by learning one latent representation vector, and (iii) provides enhanced robustness against client failures during training phase. Extensive experiments on five classification datasets show that TabVFL can outperform the prior work design, with 26.12% of improvement on f1-score.
Create account to get full access
Overview
- The paper explores a new technique called TabVFL (Tabular Vertical Federated Learning) that aims to improve the latent representation in vertical federated learning.
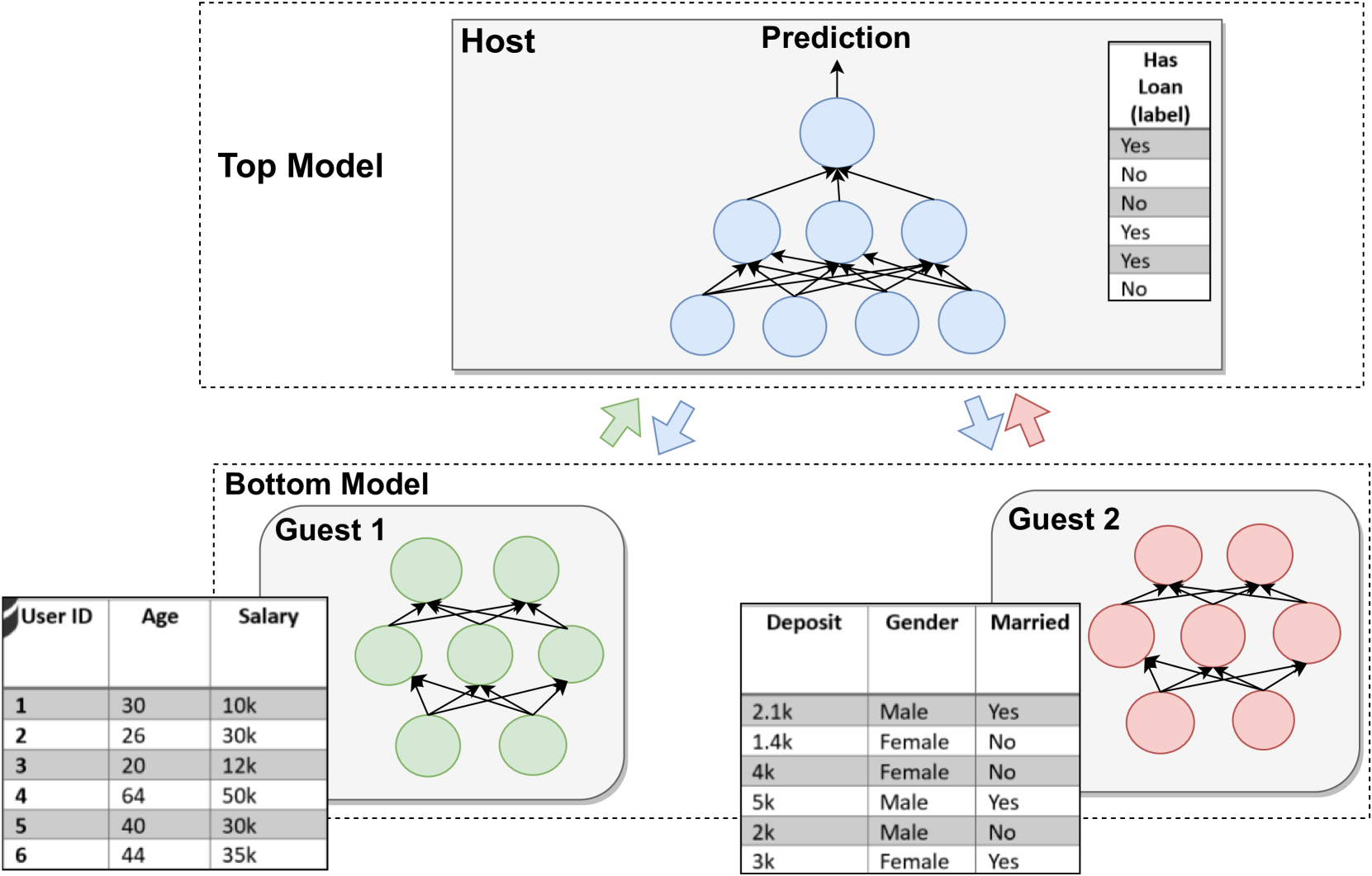
- Vertical federated learning is a type of federated learning where different parties hold different features (columns) of the same set of data instances.
- The paper proposes several key innovations to enhance the latent representation in vertical federated learning, leading to improved model performance.
Plain English Explanation
TabVFL: Improving Latent Representation in Vertical Federated Learning presents a new approach to address challenges in vertical federated learning. In vertical federated learning, different organizations or parties hold different pieces of information about the same set of people or entities. For example, one party might have a person's address, while another has their income information. The goal is to build a shared machine learning model without sharing the sensitive data directly.
The key innovation in this paper is a technique called TabVFL that improves the quality of the "hidden" or "latent" representations learned by the model. These latent representations capture important patterns in the data that allow the model to make accurate predictions. By enhancing the latent representations, the model can perform better on the overall task, whether it's predicting someone's credit risk or identifying fraudulent transactions.
The paper demonstrates through experiments that TabVFL outperforms existing vertical federated learning approaches in terms of model accuracy and other important metrics. This could lead to better real-world applications of federated learning, where sensitive data needs to be protected while still deriving valuable insights.
Technical Explanation
TabVFL: Improving Latent Representation in Vertical Federated Learning introduces a new technique called TabVFL that aims to enhance the latent representation learning in vertical federated learning (VFL) settings.
In a VFL scenario, different parties hold different feature columns (attributes) of the same set of data instances. The key challenge is to learn a shared model without directly sharing the raw data, which could compromise privacy and security. Prior work has focused on improving privacy-preserving in VFL and enabling GAN-based data generation to address this challenge.
The authors of this paper argue that a critical factor in VFL performance is the quality of the learned latent representations. They propose several key innovations in TabVFL to enhance the latent representation learning:
- A novel cross-silo loss function that aligns the latent representations across different parties.
- A tailored architecture that incorporates TabNet, a state-of-the-art tabular feature extractor, to capture complex feature interactions.
- A knowledge distillation mechanism that transfers knowledge from a centralized model to the distributed VFL model.
Through extensive experiments on real-world datasets, the authors demonstrate that TabVFL outperforms existing VFL methods in terms of predictive performance, feature importance interpretability, and robustness to label inference attacks like KDK Defense.
Critical Analysis
The paper presents a compelling approach to improving latent representation learning in vertical federated learning. The innovations in TabVFL, such as the cross-silo loss function and the integration of TabNet, appear well-designed and backed by sound theoretical reasoning.
However, the paper could have delved deeper into the potential limitations and areas for further research. For example, the authors mention the need for efficient communication protocols and the potential impact of data heterogeneity across parties, but do not provide a thorough discussion of these factors.
Additionally, the paper could have addressed the computational and storage overhead associated with the proposed techniques, as well as how TabVFL might scale to scenarios with a large number of participating parties. These considerations would be important for real-world deployment and adoption of the method.
Furthermore, the authors could have explored the generalizability of TabVFL beyond the specific use cases presented in the paper. Investigating its performance on a wider range of datasets and tasks would strengthen the claim that this approach is a significant advancement in the field of vertical federated learning.
Overall, the paper presents a valuable contribution to the field of vertical federated learning, and the TabVFL method shows promise for improving model performance and interpretability in privacy-preserving settings. However, further research and analysis of the potential limitations and broader applicability of the approach would strengthen the impact of this work.
Conclusion
TabVFL: Improving Latent Representation in Vertical Federated Learning introduces a novel technique called TabVFL that enhances latent representation learning in vertical federated learning. By incorporating innovations such as a cross-silo loss function and the integration of TabNet, the authors demonstrate significant improvements in model performance, feature importance interpretability, and robustness to label inference attacks.
The potential impact of this work lies in its ability to unlock the full potential of vertical federated learning, where sensitive data needs to be protected while still deriving valuable insights. As organizations and industries increasingly embrace federated learning, techniques like TabVFL could play a crucial role in enabling privacy-preserving, high-performing machine learning models that benefit society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Vertical Federated Learning for Effectiveness, Security, Applicability: A Survey
Mang Ye, Wei Shen, Bo Du, Eduard Snezhko, Vassili Kovalev, Pong C. Yuen
0
0
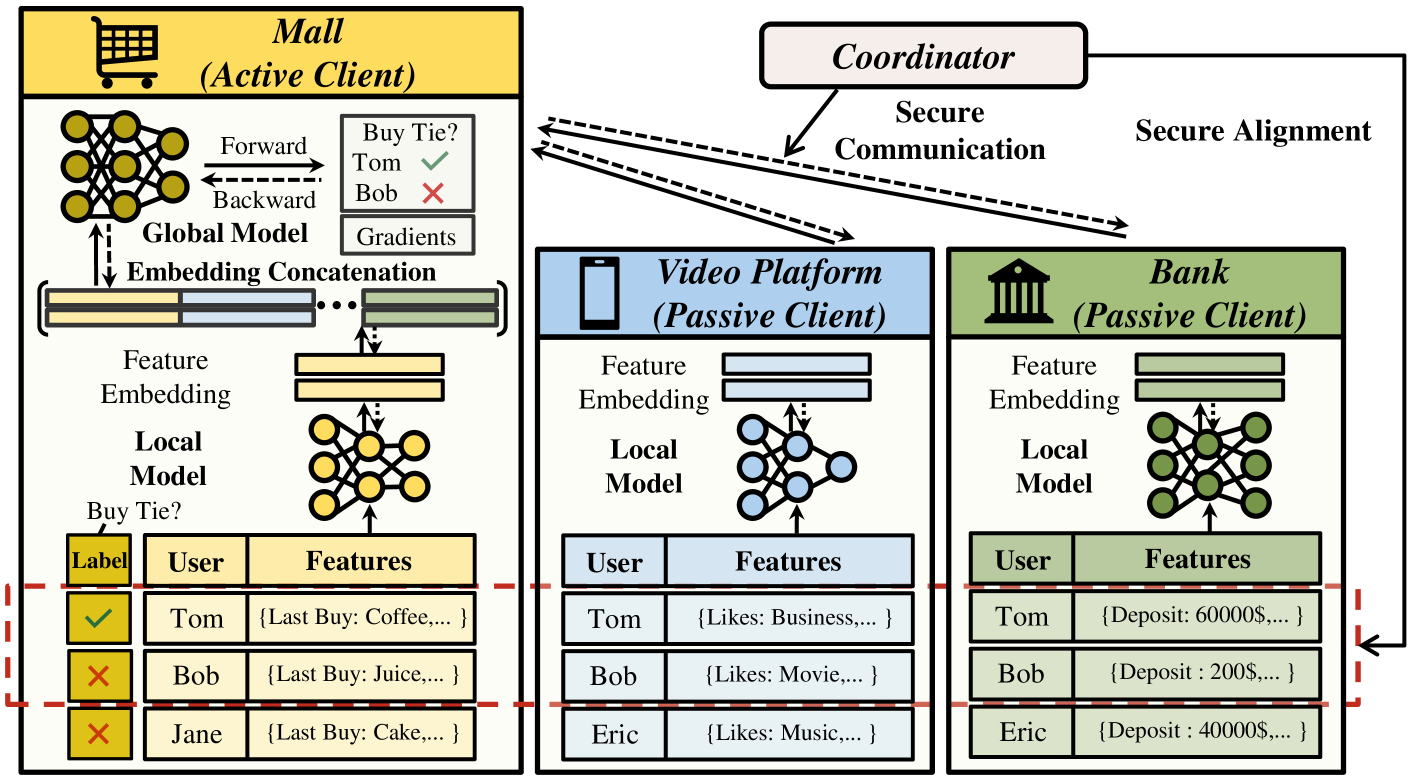
Vertical Federated Learning (VFL) is a privacy-preserving distributed learning paradigm where different parties collaboratively learn models using partitioned features of shared samples, without leaking private data. Recent research has shown promising results addressing various challenges in VFL, highlighting its potential for practical applications in cross-domain collaboration. However, the corresponding research is scattered and lacks organization. To advance VFL research, this survey offers a systematic overview of recent developments. First, we provide a history and background introduction, along with a summary of the general training protocol of VFL. We then revisit the taxonomy in recent reviews and analyze limitations in-depth. For a comprehensive and structured discussion, we synthesize recent research from three fundamental perspectives: effectiveness, security, and applicability. Finally, we discuss several critical future research directions in VFL, which will facilitate the developments in this field. We provide a collection of research lists and periodically update them at https://github.com/shentt67/VFL_Survey.
6/5/2024
Vertical Federated Learning Hybrid Local Pre-training
Wenguo Li, Xinling Guo, Xu Jiao, Tiancheng Huang, Xiaoran Yan, Yao Yang
0
0
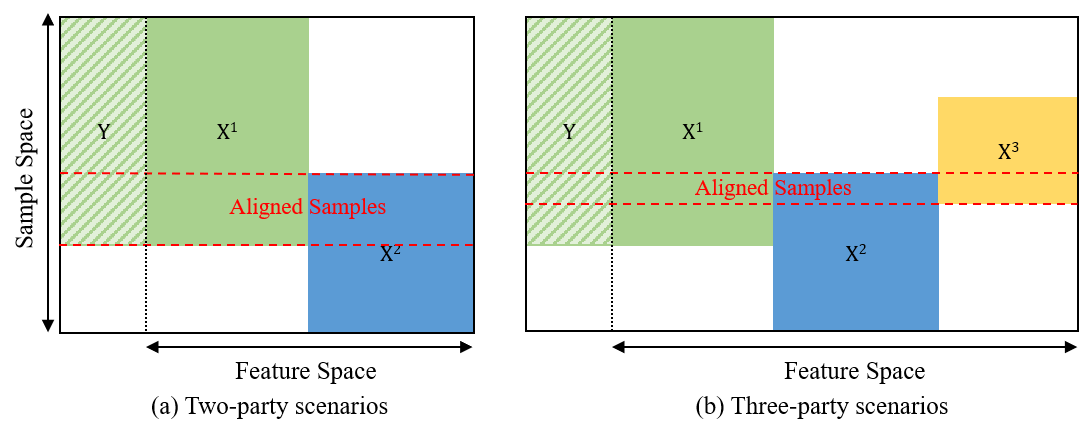
Vertical Federated Learning (VFL), which has a broad range of real-world applications, has received much attention in both academia and industry. Enterprises aspire to exploit more valuable features of the same users from diverse departments to boost their model prediction skills. VFL addresses this demand and concurrently secures individual parties from exposing their raw data. However, conventional VFL encounters a bottleneck as it only leverages aligned samples, whose size shrinks with more parties involved, resulting in data scarcity and the waste of unaligned data. To address this problem, we propose a novel VFL Hybrid Local Pre-training (VFLHLP) approach. VFLHLP first pre-trains local networks on the local data of participating parties. Then it utilizes these pre-trained networks to adjust the sub-model for the labeled party or enhance representation learning for other parties during downstream federated learning on aligned data, boosting the performance of federated models. The experimental results on real-world advertising datasets, demonstrate that our approach achieves the best performance over baseline methods by large margins. The ablation study further illustrates the contribution of each technique in VFLHLP to its overall performance.
5/22/2024
📊
Scalable Vertical Federated Learning via Data Augmentation and Amortized Inference
Conor Hassan, Matthew Sutton, Antonietta Mira, Kerrie Mengersen
0
0
Vertical federated learning (VFL) has emerged as a paradigm for collaborative model estimation across multiple clients, each holding a distinct set of covariates. This paper introduces the first comprehensive framework for fitting Bayesian models in the VFL setting. We propose a novel approach that leverages data augmentation techniques to transform VFL problems into a form compatible with existing Bayesian federated learning algorithms. We present an innovative model formulation for specific VFL scenarios where the joint likelihood factorizes into a product of client-specific likelihoods. To mitigate the dimensionality challenge posed by data augmentation, which scales with the number of observations and clients, we develop a factorized amortized variational approximation that achieves scalability independent of the number of observations. We showcase the efficacy of our framework through extensive numerical experiments on logistic regression, multilevel regression, and a novel hierarchical Bayesian split neural net model. Our work paves the way for privacy-preserving, decentralized Bayesian inference in vertically partitioned data scenarios, opening up new avenues for research and applications in various domains.
5/8/2024

Entity Augmentation for Efficient Classification of Vertically Partitioned Data with Limited Overlap
Avi Amalanshu, Viswesh Nagaswamy, G. V. S. S. Prudhvi, Yash Sirvi, Debashish Chakravarty
0
0
Vertical Federated Learning (VFL) is a machine learning paradigm for learning from vertically partitioned data (i.e. features for each input are distributed across multiple guest clients and an aggregating host server owns labels) without communicating raw data. Traditionally, VFL involves an entity resolution phase where the host identifies and serializes the unique entities known to all guests. This is followed by private set intersection to find common entities, and an entity alignment step to ensure all guests are always processing the same entity's data. However, using only data of entities from the intersection means guests discard potentially useful data. Besides, the effect on privacy is dubious and these operations are computationally expensive. We propose a novel approach that eliminates the need for set intersection and entity alignment in categorical tasks. Our Entity Augmentation technique generates meaningful labels for activations sent to the host, regardless of their originating entity, enabling efficient VFL without explicit entity alignment. With limited overlap between training data, this approach performs substantially better (e.g. with 5% overlap, 48.1% vs 69.48% test accuracy on CIFAR-10). In fact, thanks to the regularizing effect, our model performs marginally better even with 100% overlap.
6/27/2024