Envisioning Class Entity Reasoning by Large Language Models for Few-shot Learning

0

Sign in to get full access
Overview
- The paper explores how large language models can be used for few-shot learning by reasoning about class entities.
- It proposes a novel approach to few-shot learning that leverages the knowledge captured in large language models.
- The key idea is to utilize the language model's understanding of class concepts to aid in few-shot classification tasks.
Plain English Explanation
Large language models, like GPT-3, have shown remarkable capabilities in understanding and generating human language. This paper explores how these models can be used to help with few-shot learning tasks, where a model needs to classify new examples based on only a handful of training samples.
The core insight is that language models have acquired a rich understanding of different concepts and entities through their training on vast amounts of text data. This knowledge can be leveraged to aid in few-shot learning, where the model can reason about the similarities and differences between the classes it needs to learn.
For example, if the model needs to learn to classify images of different types of animals, it can draw on its language understanding to reason about the properties and characteristics of each animal class. This can help the model make more informed decisions when presented with new animal images, even if it has only seen a few examples of each class.
The researchers propose a specific approach to achieve this, which involves fine-tuning the language model on the few-shot learning task and using its internal representations to guide the classification process. By tapping into the model's inherent knowledge about concepts and entities, they aim to improve the few-shot learning performance compared to traditional approaches.
Technical Explanation
The paper introduces a novel approach to few-shot learning that leverages the rich conceptual knowledge captured by large language models. The key idea is to utilize the language model's understanding of class entities to aid in few-shot classification tasks.
The proposed method involves fine-tuning a pre-trained language model, such as GPT-3, on the few-shot learning task. During this fine-tuning process, the language model learns to associate its internal representations with the specific classes it needs to recognize. These learned representations can then be used to guide the few-shot classification process.
Specifically, the language model's embeddings are used to compute similarity scores between the input example and the few-shot class prototypes. These similarity scores are then combined with features extracted from the input example to make the final classification decision. This allows the model to draw on its language-based understanding of the class concepts to improve its few-shot learning performance.
The authors evaluate their approach on several few-shot learning benchmarks and demonstrate its effectiveness compared to traditional few-shot learning methods. The results suggest that the language model's knowledge can indeed be beneficial in few-shot scenarios, where limited training data is available.
Critical Analysis
The paper presents a promising approach to leveraging large language models for few-shot learning. By tapping into the rich conceptual knowledge captured by these models, the researchers have shown that it is possible to improve few-shot classification performance.
However, the paper does not address some potential limitations and areas for further exploration. For instance, the paper does not discuss the computational overhead or training time required for the fine-tuning process, which could be an important practical consideration.
Additionally, the paper focuses on a specific architectural design, and it would be valuable to explore other ways of integrating language model knowledge into few-shot learning systems. The authors mention the potential for further investigations into different fine-tuning strategies and the use of prompting techniques, which could lead to additional insights.
Another aspect that could be further examined is the interpretability and transparency of the language model's influence on the few-shot learning decisions. Understanding how the language-based reasoning contributes to the classification process could provide valuable insights and help users trust the model's decisions.
Despite these potential areas for improvement, the paper presents a compelling approach that demonstrates the power of combining large language models with few-shot learning techniques. As the field of few-shot learning continues to evolve, this work highlights the promising role that language-based reasoning can play in advancing the state-of-the-art.
Conclusion
This paper explores a novel approach to few-shot learning that leverages the conceptual knowledge captured by large language models. By fine-tuning the language model on the few-shot learning task and using its internal representations to guide the classification process, the researchers have shown that it is possible to improve few-shot learning performance.
The key insight is that language models have acquired a rich understanding of different concepts and entities through their training on vast amounts of text data. This knowledge can be effectively leveraged to aid in few-shot learning scenarios, where the model can draw on its language-based reasoning to make more informed decisions about new examples.
While the paper presents a promising approach, it also highlights opportunities for further research and refinement. Exploring alternative integration strategies, addressing practical considerations, and enhancing the interpretability of the language model's influence could lead to even more impactful few-shot learning systems.
Overall, this work demonstrates the potential of combining large language models with few-shot learning techniques, opening up new avenues for advancing the field of machine learning and its applications in real-world scenarios with limited training data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Envisioning Class Entity Reasoning by Large Language Models for Few-shot Learning
Mushui Liu, Fangtai Wu, Bozheng Li, Ziqian Lu, Yunlong Yu, Xi Li
Few-shot learning (FSL) aims to recognize new concepts using a limited number of visual samples. Existing approaches attempt to incorporate semantic information into the limited visual data for category understanding. However, these methods often enrich class-level feature representations with abstract category names, failing to capture the nuanced features essential for effective generalization. To address this issue, we propose a novel framework for FSL, which incorporates both the abstract class semantics and the concrete class entities extracted from Large Language Models (LLMs), to enhance the representation of the class prototypes. Specifically, our framework composes a Semantic-guided Visual Pattern Extraction (SVPE) module and a Prototype-Calibration (PC) module, where the SVPE meticulously extracts semantic-aware visual patterns across diverse scales, while the PC module seamlessly integrates these patterns to refine the visual prototype, enhancing its representativeness. Extensive experiments on four few-shot classification benchmarks and the BSCD-FSL cross-domain benchmarks showcase remarkable advancements over the current state-of-the-art methods. Notably, for the challenging one-shot setting, our approach, utilizing the ResNet-12 backbone, achieves an impressive average improvement of 1.95% over the second-best competitor.
Read more8/23/2024
0
Few Shot Class Incremental Learning using Vision-Language models
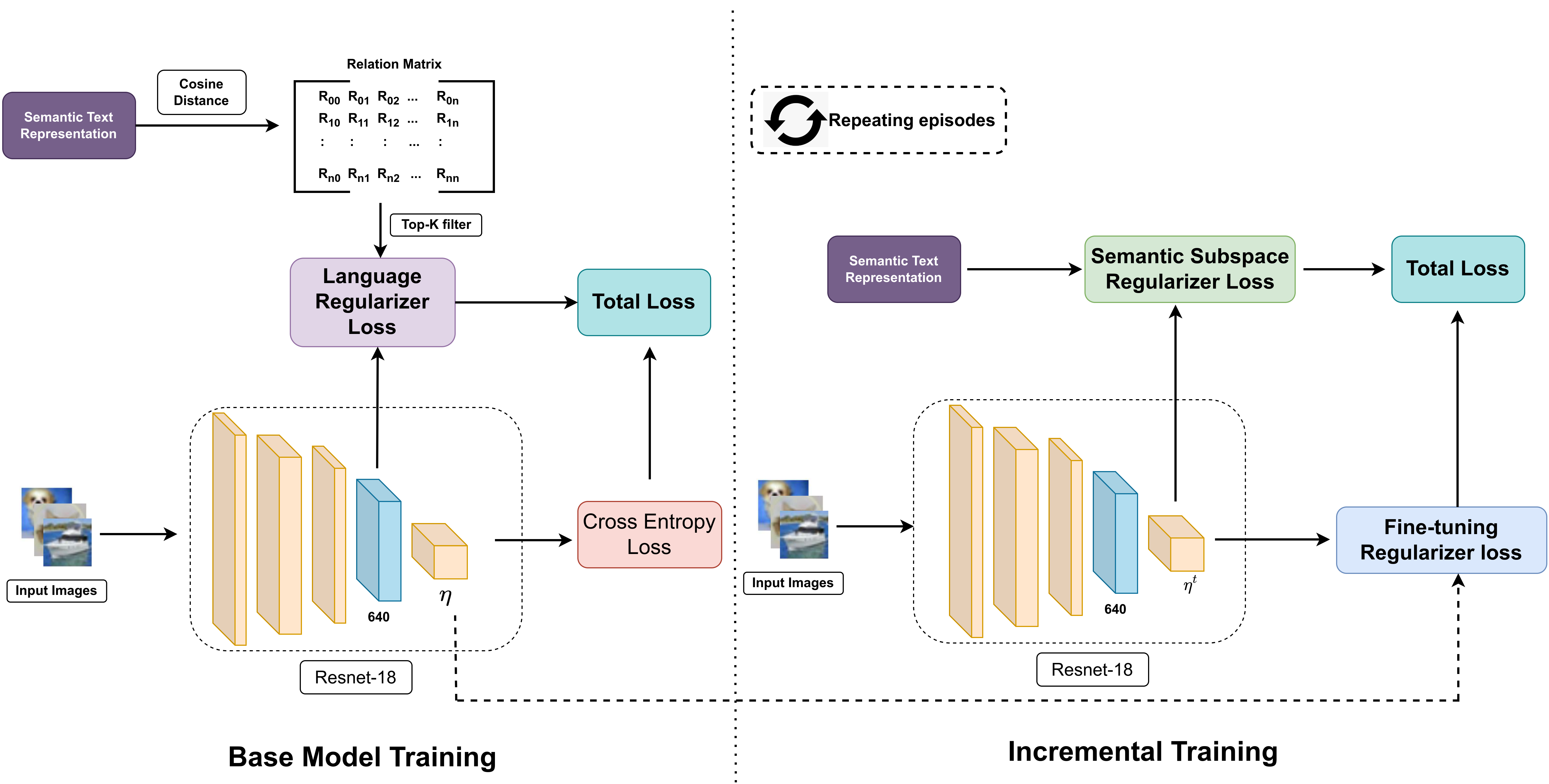
Anurag Kumar, Chinmay Bharti, Saikat Dutta, Srikrishna Karanam, Biplab Banerjee
Recent advancements in deep learning have demonstrated remarkable performance comparable to human capabilities across various supervised computer vision tasks. However, the prevalent assumption of having an extensive pool of training data encompassing all classes prior to model training often diverges from real-world scenarios, where limited data availability for novel classes is the norm. The challenge emerges in seamlessly integrating new classes with few samples into the training data, demanding the model to adeptly accommodate these additions without compromising its performance on base classes. To address this exigency, the research community has introduced several solutions under the realm of few-shot class incremental learning (FSCIL). In this study, we introduce an innovative FSCIL framework that utilizes language regularizer and subspace regularizer. During base training, the language regularizer helps incorporate semantic information extracted from a Vision-Language model. The subspace regularizer helps in facilitating the model's acquisition of nuanced connections between image and text semantics inherent to base classes during incremental training. Our proposed framework not only empowers the model to embrace novel classes with limited data, but also ensures the preservation of performance on base classes. To substantiate the efficacy of our approach, we conduct comprehensive experiments on three distinct FSCIL benchmarks, where our framework attains state-of-the-art performance.
Read more8/16/2024

0
Making Large Vision Language Models to be Good Few-shot Learners
Fan Liu, Wenwen Cai, Jian Huo, Chuanyi Zhang, Delong Chen, Jun Zhou
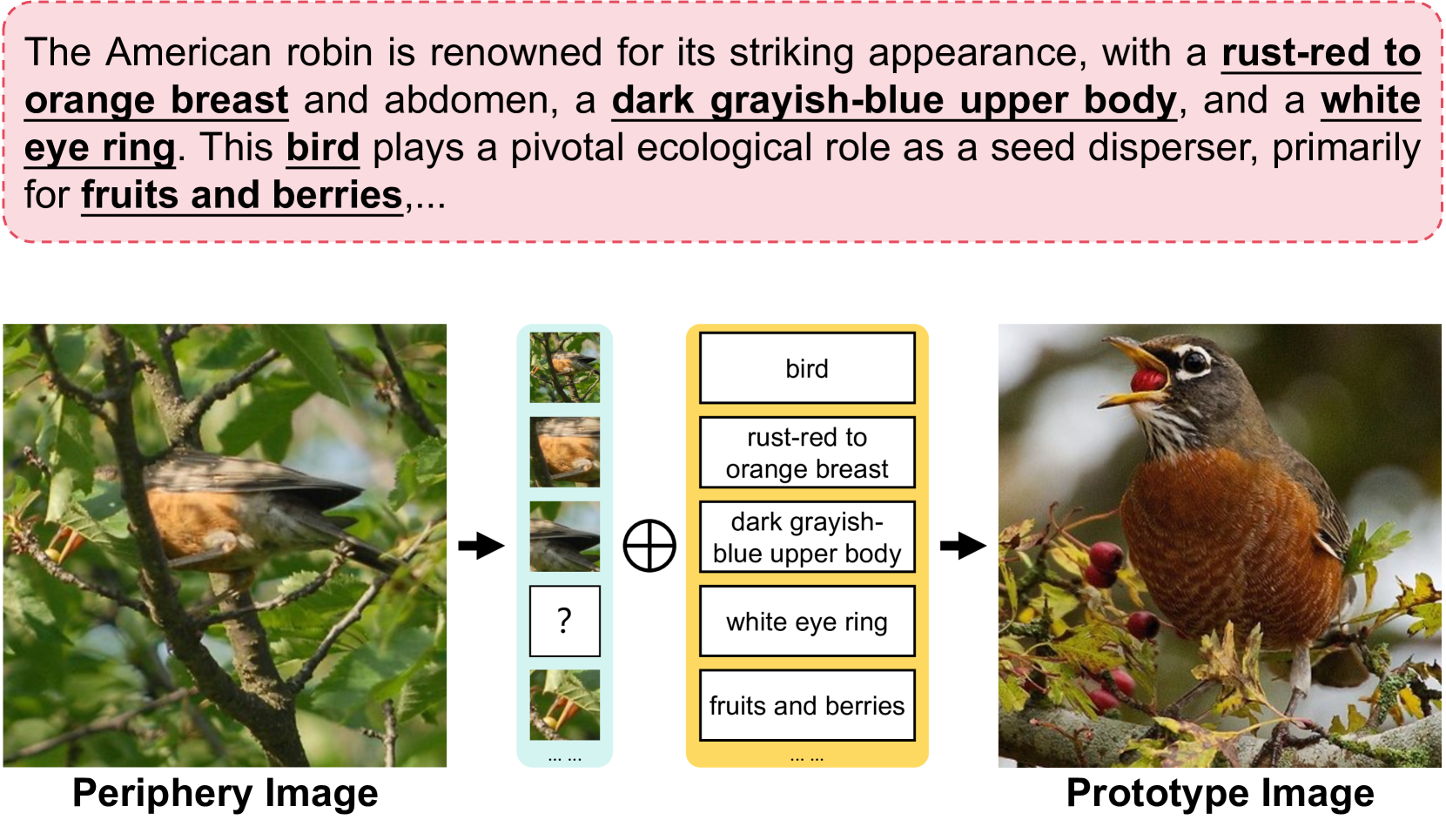
Few-shot classification (FSC) is a fundamental yet challenging task in computer vision that involves recognizing novel classes from limited data. While previous methods have focused on enhancing visual features or incorporating additional modalities, Large Vision Language Models (LVLMs) offer a promising alternative due to their rich knowledge and strong visual perception. However, LVLMs risk learning specific response formats rather than effectively extracting useful information from support data in FSC tasks. In this paper, we investigate LVLMs' performance in FSC and identify key issues such as insufficient learning and the presence of severe positional biases. To tackle the above challenges, we adopt the meta-learning strategy to teach models learn to learn. By constructing a rich set of meta-tasks for instruction fine-tuning, LVLMs enhance the ability to extract information from few-shot support data for classification. Additionally, we further boost LVLM's few-shot learning capabilities through label augmentation and candidate selection in the fine-tuning and inference stage, respectively. Label augmentation is implemented via a character perturbation strategy to ensure the model focuses on support information. Candidate selection leverages attribute descriptions to filter out unreliable candidates and simplify the task. Extensive experiments demonstrate that our approach achieves superior performance on both general and fine-grained datasets. Furthermore, our candidate selection strategy has been proven beneficial for training-free LVLMs.
Read more8/22/2024
0
Simple Semantic-Aided Few-Shot Learning
Hai Zhang, Junzhe Xu, Shanlin Jiang, Zhenan He
Learning from a limited amount of data, namely Few-Shot Learning, stands out as a challenging computer vision task. Several works exploit semantics and design complicated semantic fusion mechanisms to compensate for rare representative features within restricted data. However, relying on naive semantics such as class names introduces biases due to their brevity, while acquiring extensive semantics from external knowledge takes a huge time and effort. This limitation severely constrains the potential of semantics in Few-Shot Learning. In this paper, we design an automatic way called Semantic Evolution to generate high-quality semantics. The incorporation of high-quality semantics alleviates the need for complex network structures and learning algorithms used in previous works. Hence, we employ a simple two-layer network termed Semantic Alignment Network to transform semantics and visual features into robust class prototypes with rich discriminative features for few-shot classification. The experimental results show our framework outperforms all previous methods on six benchmarks, demonstrating a simple network with high-quality semantics can beat intricate multi-modal modules on few-shot classification tasks. Code is available at https://github.com/zhangdoudou123/SemFew.
Read more4/10/2024