Epidemic Information Extraction for Event-Based Surveillance using Large Language Models

0

Sign in to get full access
Overview
- This paper explores using large language models (LLMs) for extracting epidemic information from text for event-based disease surveillance.
- The researchers developed a system to automatically identify disease outbreaks, locations, and other key details from online news and social media.
- They evaluated their approach on a dataset of epidemic-related articles, demonstrating its effectiveness compared to previous methods.
Plain English Explanation
The researchers in this study wanted to develop a way to automatically detect and gather information about disease outbreaks from online sources like news articles and social media posts. This is important for epidemic surveillance, which is the process of closely monitoring for signs of disease spreading in a population.
To do this, they used large language models - powerful AI systems trained on massive amounts of text data. These models can understand the meaning and context of words, which allows them to identify relevant information about disease outbreaks, such as the location, the disease type, and details about the outbreak.
The researchers tested their system on a dataset of articles related to epidemic events. They found that it was able to accurately extract key details about the outbreaks, outperforming previous methods for public health classification and temporal event extraction. This suggests that large language models could be a powerful tool for monitoring critical infrastructure during disasters and improving real-time disease surveillance.
Technical Explanation
The researchers developed a system that uses LLMs to extract epidemic-related information from text for event-based disease surveillance. They evaluated their approach on a dataset of news articles and social media posts about epidemic events.
The system first uses an LLM-based classifier to identify relevant epidemic-related articles from the input text corpus. It then applies a series of IE models (also based on LLMs) to extract key details such as:
- The type of disease or pathogen involved
- The location of the outbreak
- Temporal information about the start and end of the event
- Details about the affected populations and scale of the outbreak
The researchers trained and evaluated these IE models on a curated dataset of epidemic-related articles, comparing their performance to previous state-of-the-art IE methods. They found that the LLM-based models significantly outperformed the baselines, demonstrating the power of these large-scale language models for accurately extracting epidemiological information from text.
Critical Analysis
The researchers acknowledge several limitations of their work. First, the dataset used for training and evaluation, while comprehensive, may not fully capture the diversity of epidemic reporting in real-world settings. The performance of the system on more heterogeneous data sources remains an open question.
Additionally, the models rely on the availability of high-quality training data, which can be challenging to obtain, especially for rare or emerging disease events. Further research is needed to explore few-shot or zero-shot learning techniques to improve the generalizability of the models.
Finally, the study does not address potential biases or ethical concerns that may arise from deploying such AI systems for disease surveillance. Careful consideration must be given to issues of privacy, fairness, and the responsible use of these technologies, especially in the sensitive domain of public health.
Conclusion
This research demonstrates the promising potential of large language models for automating the extraction of epidemic-related information from text data. By accurately identifying disease outbreaks, locations, and other key details, such systems could significantly enhance real-time disease surveillance and event-based early warning systems.
However, further work is needed to address the limitations and ensure the responsible development and deployment of these technologies. Ongoing collaboration between researchers, public health experts, and policymakers will be crucial to unlocking the full potential of AI-powered epidemic information extraction while mitigating potential risks and ethical concerns.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Epidemic Information Extraction for Event-Based Surveillance using Large Language Models
Sergio Consoli, Peter Markov, Nikolaos I. Stilianakis, Lorenzo Bertolini, Antonio Puertas Gallardo, Mario Ceresa
This paper presents a novel approach to epidemic surveillance, leveraging the power of Artificial Intelligence and Large Language Models (LLMs) for effective interpretation of unstructured big data sources, like the popular ProMED and WHO Disease Outbreak News. We explore several LLMs, evaluating their capabilities in extracting valuable epidemic information. We further enhance the capabilities of the LLMs using in-context learning, and test the performance of an ensemble model incorporating multiple open-source LLMs. The findings indicate that LLMs can significantly enhance the accuracy and timeliness of epidemic modelling and forecasting, offering a promising tool for managing future pandemic events.
Read more8/27/2024
0
Advancing Real-time Pandemic Forecasting Using Large Language Models: A COVID-19 Case Study
Hongru Du (Frank), Jianan Zhao (Frank), Yang Zhao (Frank), Shaochong Xu (Frank), Xihong Lin (Frank), Yiran Chen (Frank), Lauren M. Gardner (Frank), Hao (Frank), Yang
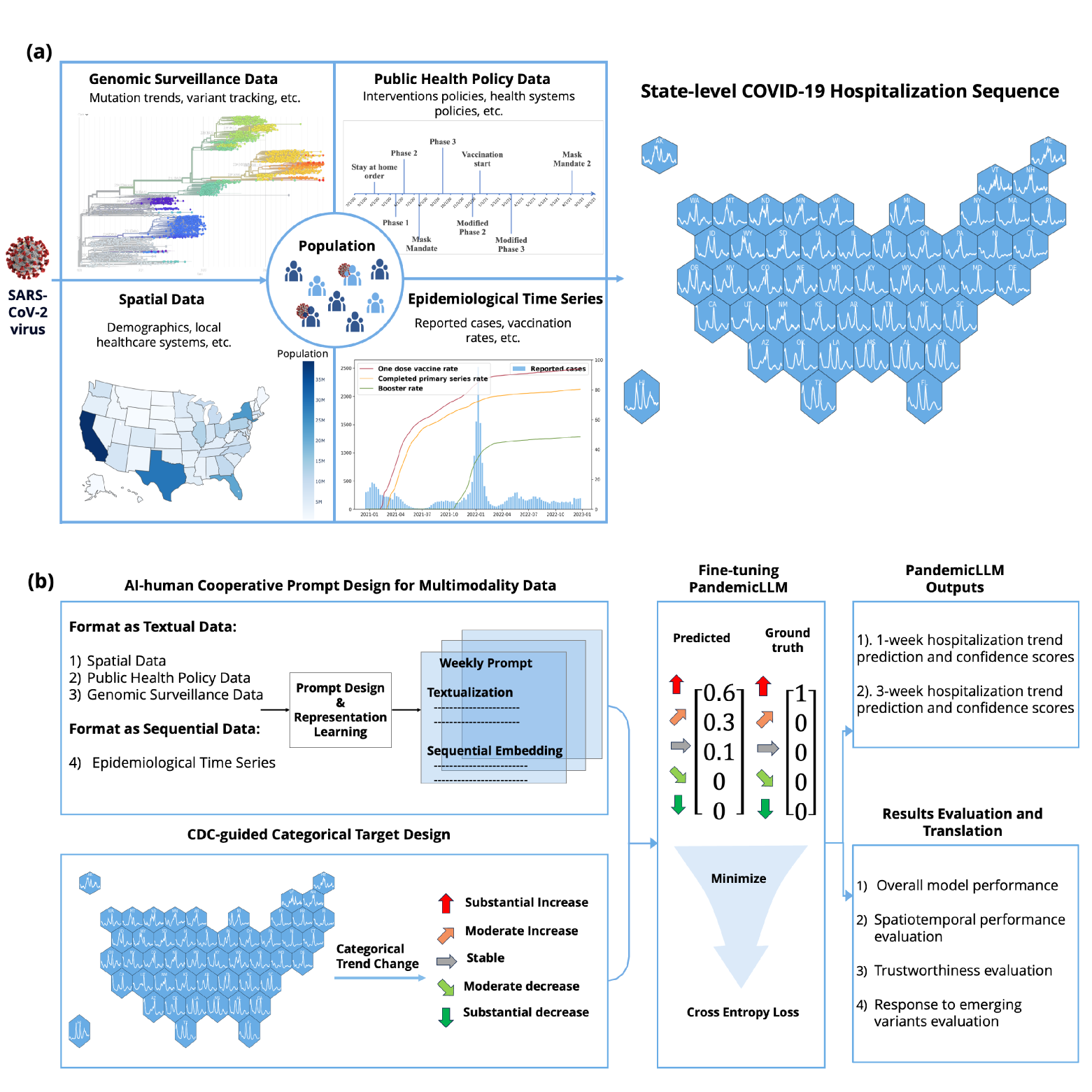
Forecasting the short-term spread of an ongoing disease outbreak is a formidable challenge due to the complexity of contributing factors, some of which can be characterized through interlinked, multi-modality variables such as epidemiological time series data, viral biology, population demographics, and the intersection of public policy and human behavior. Existing forecasting model frameworks struggle with the multifaceted nature of relevant data and robust results translation, which hinders their performances and the provision of actionable insights for public health decision-makers. Our work introduces PandemicLLM, a novel framework with multi-modal Large Language Models (LLMs) that reformulates real-time forecasting of disease spread as a text reasoning problem, with the ability to incorporate real-time, complex, non-numerical information that previously unattainable in traditional forecasting models. This approach, through a unique AI-human cooperative prompt design and time series representation learning, encodes multi-modal data for LLMs. The model is applied to the COVID-19 pandemic, and trained to utilize textual public health policies, genomic surveillance, spatial, and epidemiological time series data, and is subsequently tested across all 50 states of the U.S. Empirically, PandemicLLM is shown to be a high-performing pandemic forecasting framework that effectively captures the impact of emerging variants and can provide timely and accurate predictions. The proposed PandemicLLM opens avenues for incorporating various pandemic-related data in heterogeneous formats and exhibits performance benefits over existing models. This study illuminates the potential of adapting LLMs and representation learning to enhance pandemic forecasting, illustrating how AI innovations can strengthen pandemic responses and crisis management in the future.
Read more4/11/2024
💬
0
Large Language Model Enhanced Clustering for News Event Detection
Adane Nega Tarekegn
The news landscape is continuously evolving, with an ever-increasing volume of information from around the world. Automated event detection within this vast data repository is essential for monitoring, identifying, and categorizing significant news occurrences across diverse platforms. This paper presents an event detection framework that leverages Large Language Models (LLMs) combined with clustering analysis to detect news events from the Global Database of Events, Language, and Tone (GDELT). The framework enhances event clustering through both pre-event detection tasks (keyword extraction and text embedding) and post-event detection tasks (event summarization and topic labelling). We also evaluate the impact of various textual embeddings on the quality of clustering outcomes, ensuring robust news categorization. Additionally, we introduce a novel Cluster Stability Assessment Index (CSAI) to assess the validity and robustness of clustering results. CSAI utilizes multiple feature vectors to provide a new way of measuring clustering quality. Our experiments indicate that the use of LLM embedding in the event detection framework has significantly improved the results, demonstrating greater robustness in terms of CSAI scores. Moreover, post-event detection tasks generate meaningful insights, facilitating effective interpretation of event clustering results. Overall, our experimental results indicate that the proposed framework offers valuable insights and could enhance the accuracy in news analysis and reporting.
Read more7/9/2024
💬
0
Evaluating Large Language Models for Public Health Classification and Extraction Tasks
Joshua Harris, Timothy Laurence, Leo Loman, Fan Grayson, Toby Nonnenmacher, Harry Long, Loes WalsGriffith, Amy Douglas, Holly Fountain, Stelios Georgiou, Jo Hardstaff, Kathryn Hopkins, Y-Ling Chi, Galena Kuyumdzhieva, Lesley Larkin, Samuel Collins, Hamish Mohammed, Thomas Finnie, Luke Hounsome, Steven Riley
Advances in Large Language Models (LLMs) have led to significant interest in their potential to support human experts across a range of domains, including public health. In this work we present automated evaluations of LLMs for public health tasks involving the classification and extraction of free text. We combine six externally annotated datasets with seven new internally annotated datasets to evaluate LLMs for processing text related to: health burden, epidemiological risk factors, and public health interventions. We initially evaluate five open-weight LLMs (7-70 billion parameters) across all tasks using zero-shot in-context learning. We find that Llama-3-70B-Instruct is the highest performing model, achieving the best results on 15/17 tasks (using micro-F1 scores). We see significant variation across tasks with all open-weight LLMs scoring below 60% micro-F1 on some challenging tasks, such as Contact Classification, while all LLMs achieve greater than 80% micro-F1 on others, such as GI Illness Classification. For a subset of 12 tasks, we also evaluate GPT-4 and find comparable results to Llama-3-70B-Instruct, which scores equally or outperforms GPT-4 on 6 of the 12 tasks. Overall, based on these initial results we find promising signs that LLMs may be useful tools for public health experts to extract information from a wide variety of free text sources, and support public health surveillance, research, and interventions.
Read more5/24/2024