ESE: Espresso Sentence Embeddings

0

Sign in to get full access
Overview
- This paper introduces a novel approach to sentence embeddings called "2D Matryoshka Sentence Embeddings" (2D-MSE).
- 2D-MSE aims to capture both semantic and structural information in text by representing sentences in a 2D grid-like structure.
- The framework extends upon existing sentence embedding techniques like SETCSE and Span-SWELL to enable more expressive and versatile representations.
Plain English Explanation
The paper presents a new way to represent the meaning of sentences called "2D Matryoshka Sentence Embeddings" (2D-MSE). Traditional sentence embeddings capture the overall meaning of a sentence, but 2D-MSE goes further by also capturing the structure and organization of the words.
Imagine a sentence like "The quick brown fox jumps over the lazy dog." Traditional embeddings might capture that this is about an animal jumping over something. But 2D-MSE can also capture how the words are arranged - with "the" and "quick" modifying "fox," for example.
By representing sentences in a 2D grid-like structure, 2D-MSE can model these structural relationships in addition to the semantics. This allows for more expressive and versatile sentence representations that can be useful for tasks like text classification, generation, and understanding.
The framework builds on ideas from prior work like SETCSE and Span-SWELL, but takes them further to create this novel 2D embedding approach.
Technical Explanation
The 2D Matryoshka Sentence Embeddings (2D-MSE) framework represents sentences in a 2D grid-like structure, where each cell encodes both the semantic meaning and structural relationships of the corresponding word or phrase.
This is achieved by first encoding the individual words using a transformer-based language model like BERT. The word embeddings are then organized into a 2D grid, where the rows represent the sequential structure of the sentence and the columns capture different levels of constituent phrases.
The key innovation is the "Matryoshka" aspect, where each cell in the 2D grid contains a nested embedding that captures the meaning of the corresponding word/phrase at multiple granularities. This allows the model to simultaneously model both the local semantics and global syntactic structure of the sentence.
The 2D-MSE framework is trained using a multi-task objective that combines standard sentence-level classification tasks with novel structural prediction tasks. This encourages the model to learn representations that are useful for both semantic and syntactic understanding.
Experiments show that 2D-MSE outperforms previous state-of-the-art sentence embedding methods on a variety of downstream tasks, including text classification, natural language inference, and semantic textual similarity. The authors attribute this to the model's ability to capture richer linguistic information in its sentence representations.
Critical Analysis
The 2D-MSE framework represents an interesting and promising direction for sentence embedding research. By explicitly modeling both semantic and structural aspects of language, it has the potential to enable more flexible and powerful text understanding capabilities.
However, the paper does not provide a thorough analysis of the limitations and potential issues with the approach. For example, it is unclear how well 2D-MSE scales to longer or more complex sentences, or how sensitive the model is to variations in sentence structure or grammatical correctness.
Additionally, the computational cost of the 2D grid-like representation and nested embeddings is not discussed. This could be a significant practical concern, especially for real-world applications that require efficient inference.
Further research is needed to fully understand the tradeoffs and generalization capabilities of the 2D-MSE framework. Comparisons to other recent advancements in sentence embeddings, such as ScalingUPSMS and LCRL, would also help contextualize the contribution of this work.
Conclusion
The 2D Matryoshka Sentence Embeddings (2D-MSE) framework presented in this paper is a novel and promising approach to capturing both semantic and structural information in text representations. By modeling sentences as 2D grids with nested embeddings, the framework can learn more expressive and versatile sentence encodings that outperform existing methods on a variety of downstream tasks.
While further research is needed to fully understand the limitations and practical implications of this approach, the core ideas behind 2D-MSE represent an exciting advancement in the field of sentence embeddings. If successfully developed and deployed, this technology could lead to significant improvements in natural language processing applications that require a deeper understanding of language structure and meaning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ESE: Espresso Sentence Embeddings
Xianming Li, Zongxi Li, Jing Li, Haoran Xie, Qing Li
High-quality sentence embeddings are fundamental in many natural language processing (NLP) tasks, such as semantic textual similarity (STS) and retrieval-augmented generation (RAG). Nevertheless, most existing methods leverage fixed-length embeddings from full-layer language models, which lack the scalability to accommodate the diverse available resources across various applications. Viewing this gap, we propose a novel sentence embedding model $mathrm{Espresso}$ $mathrm{Sentence}$ $mathrm{Embeddings}$ (ESE) with two learning processes. First, the learn-to-express process encodes more salient representations to lower layers. Second, the learn-to-compress process compacts essential features into the initial dimensions using Principal Component Analysis (PCA). This way, ESE can scale model depth via the former process and embedding size via the latter. Extensive experiments on STS and RAG suggest that ESE can effectively produce high-quality embeddings with less model depth and embedding size, enhancing embedding inference efficiency.
Read more5/22/2024
0
Simple Techniques for Enhancing Sentence Embeddings in Generative Language Models
Bowen Zhang, Kehua Chang, Chunping Li
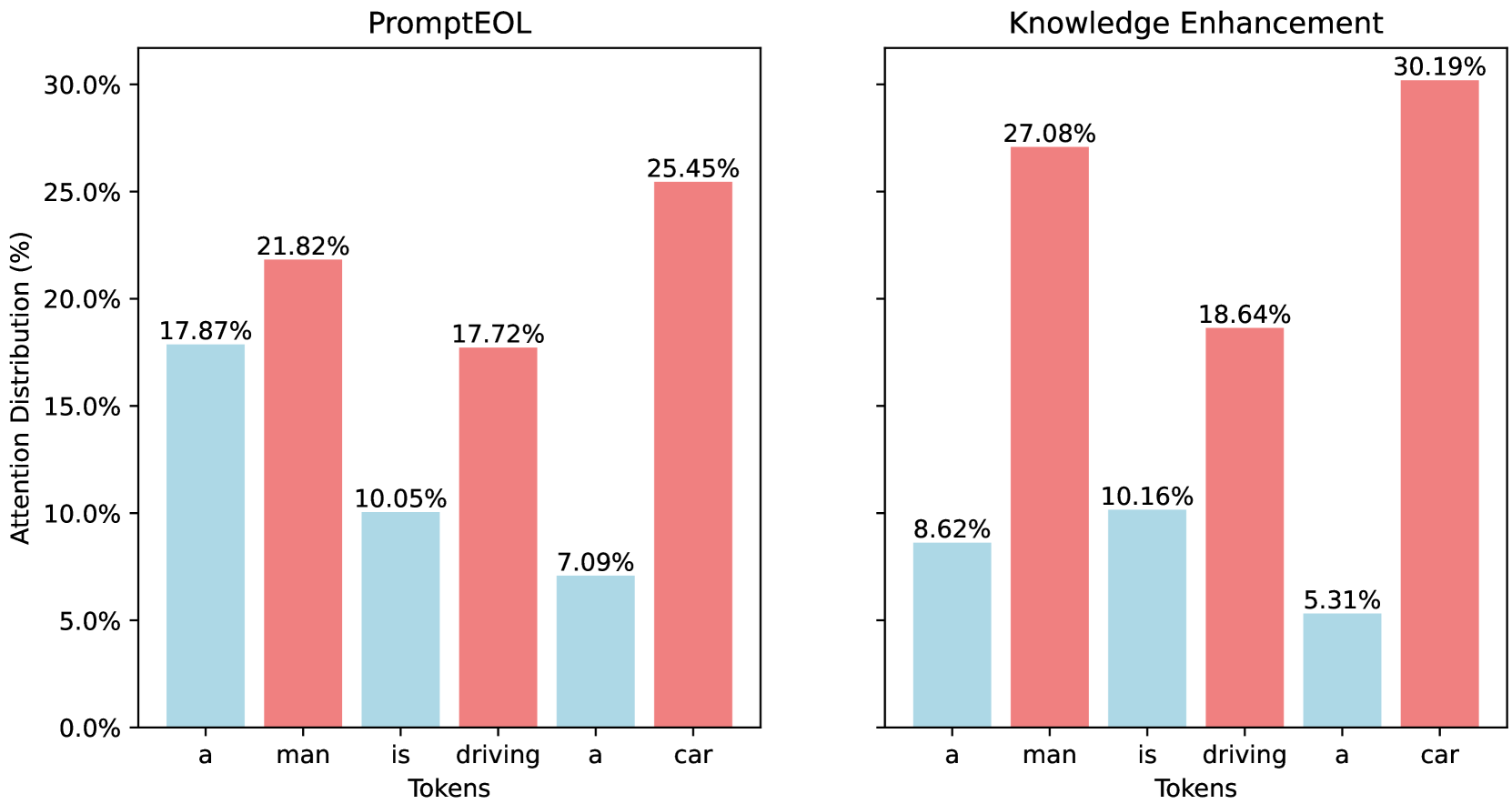
Sentence Embedding stands as a fundamental task within the realm of Natural Language Processing, finding extensive application in search engines, expert systems, and question-and-answer platforms. With the continuous evolution of large language models such as LLaMA and Mistral, research on sentence embedding has recently achieved notable breakthroughs. However, these advancements mainly pertain to fine-tuning scenarios, leaving explorations into computationally efficient direct inference methods for sentence representation in a nascent stage. This paper endeavors to bridge this research gap. Through comprehensive experimentation, we challenge the widely held belief in the necessity of an Explicit One-word Limitation for deriving sentence embeddings from Pre-trained Language Models (PLMs). We demonstrate that this approach, while beneficial for generative models under direct inference scenario, is not imperative for discriminative models or the fine-tuning of generative PLMs. This discovery sheds new light on the design of manual templates in future studies. Building upon this insight, we propose two innovative prompt engineering techniques capable of further enhancing the expressive power of PLMs' raw embeddings: Pretended Chain of Thought and Knowledge Enhancement. We confirm their effectiveness across various PLM types and provide a detailed exploration of the underlying factors contributing to their success.
Read more5/16/2024
🎲
0
EMS: Efficient and Effective Massively Multilingual Sentence Embedding Learning
Zhuoyuan Mao, Chenhui Chu, Sadao Kurohashi
Massively multilingual sentence representation models, e.g., LASER, SBERT-distill, and LaBSE, help significantly improve cross-lingual downstream tasks. However, the use of a large amount of data or inefficient model architectures results in heavy computation to train a new model according to our preferred languages and domains. To resolve this issue, we introduce efficient and effective massively multilingual sentence embedding (EMS), using cross-lingual token-level reconstruction (XTR) and sentence-level contrastive learning as training objectives. Compared with related studies, the proposed model can be efficiently trained using significantly fewer parallel sentences and GPU computation resources. Empirical results showed that the proposed model significantly yields better or comparable results with regard to cross-lingual sentence retrieval, zero-shot cross-lingual genre classification, and sentiment classification. Ablative analyses demonstrated the efficiency and effectiveness of each component of the proposed model. We release the codes for model training and the EMS pre-trained sentence embedding model, which supports 62 languages ( https://github.com/Mao-KU/EMS ).
Read more5/31/2024

0
DENSE: Dynamic Embedding Causal Target Speech Extraction
Yiwen Wang, Zeyu Yuan, Xihong Wu
Target speech extraction (TSE) focuses on extracting the speech of a specific target speaker from a mixture of signals. Existing TSE models typically utilize static embeddings as conditions for extracting the target speaker's voice. However, the static embeddings often fail to capture the contextual information of the extracted speech signal, which may limit the model's performance. We propose a novel dynamic embedding causal target speech extraction model to address this limitation. Our approach incorporates an autoregressive mechanism to generate context-dependent embeddings based on the extracted speech, enabling real-time, frame-level extraction. Experimental results demonstrate that the proposed model enhances short-time objective intelligibility (STOI) and signal-to-distortion ratio (SDR), offering a promising solution for target speech extraction in challenging scenarios.
Read more9/11/2024