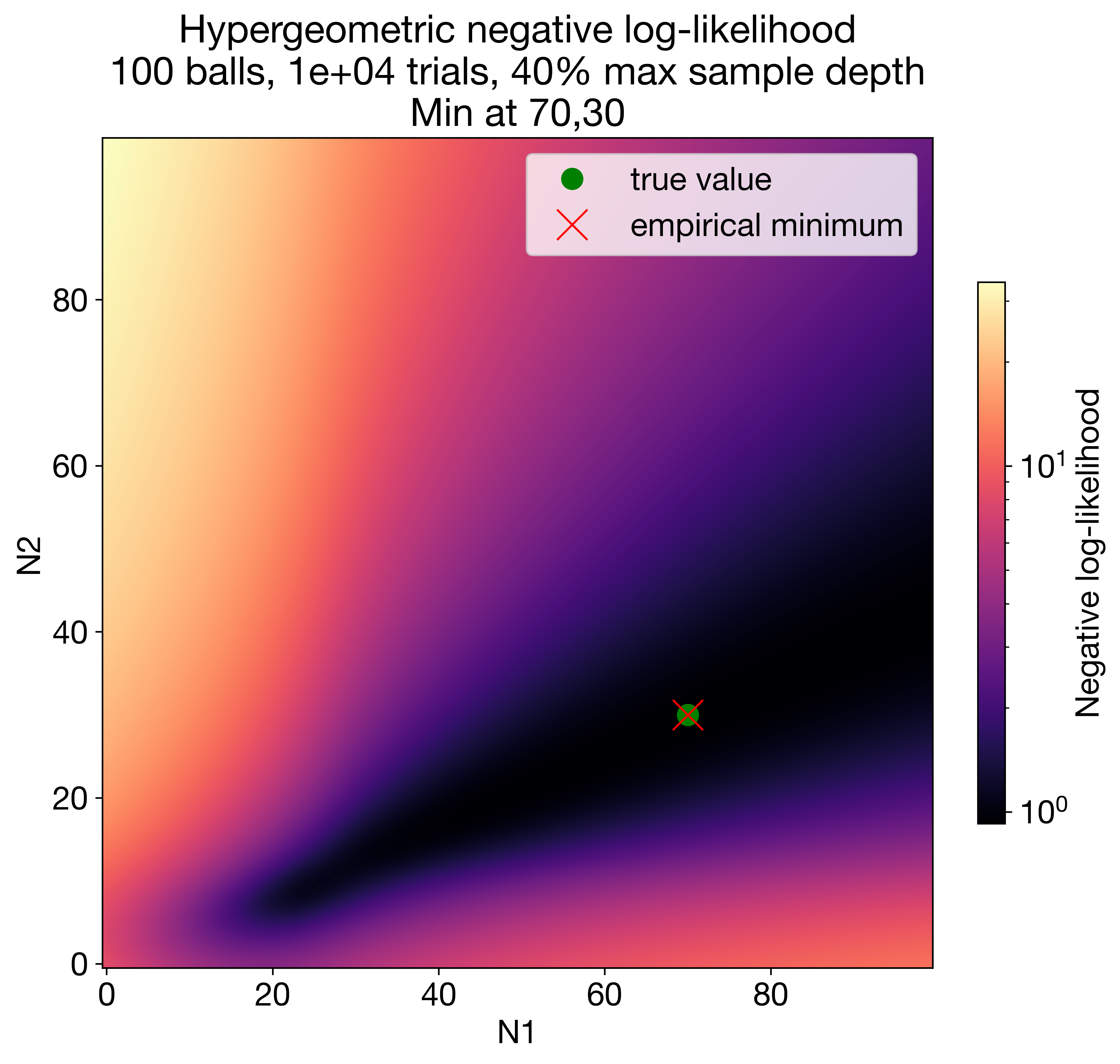
Estimating Unknown Population Sizes Using the Hypergeometric Distribution
2402.14220
0
0
Abstract
The multivariate hypergeometric distribution describes sampling without replacement from a discrete population of elements divided into multiple categories. Addressing a gap in the literature, we tackle the challenge of estimating discrete distributions when both the total population size and the sizes of its constituent categories are unknown. Here, we propose a novel solution using the hypergeometric likelihood to solve this estimation challenge, even in the presence of severe under-sampling. We develop our approach to account for a data generating process where the ground-truth is a mixture of distributions conditional on a continuous latent variable, such as with collaborative filtering, using the variational autoencoder framework. Empirical data simulation demonstrates that our method outperforms other likelihood functions used to model count data, both in terms of accuracy of population size estimate and in its ability to learn an informative latent space. We demonstrate our method's versatility through applications in NLP, by inferring and estimating the complexity of latent vocabularies in text excerpts, and in biology, by accurately recovering the true number of gene transcripts from sparse single-cell genomics data.
Create account to get full access
Overview
- The paper discusses a method for estimating the size of an unknown population using the hypergeometric distribution.
- The hypergeometric distribution is a probability distribution used to model sampling without replacement from a finite population.
- The authors present a technique for utilizing the hypergeometric distribution to infer the size of a population based on sample data.
Plain English Explanation
Imagine you have a large jar filled with different colored marbles, but you don't know exactly how many marbles are in the jar. This is similar to the "unknown population size" problem described in the paper. To estimate the number of marbles, you could randomly pull out a sample of marbles and look at their colors. Based on the number of each color in your sample, you could use a special mathematical formula called the hypergeometric distribution to calculate a best guess for the total number of marbles in the jar.
The key insight is that the hypergeometric distribution allows you to model the probabilities of different sample outcomes, given an unknown population size. By observing the actual sample you drew and comparing it to the predicted probabilities, you can work backward to infer the most likely population size. This technique can be applied to a wide variety of real-world situations where you need to estimate the size of an unknown population based on limited sample data.
Technical Explanation
The paper presents a method for estimating the size of an unknown population using the hypergeometric distribution. The hypergeometric distribution is a probability distribution that models sampling without replacement from a finite population. It describes the probability of observing a certain number of "successes" (e.g., marbles of a particular color) in a sample, given the total population size, the number of "successes" in the population, and the sample size.
The authors show how to leverage the hypergeometric distribution to infer the most likely population size, given a observed sample. By calculating the probabilities of different population sizes producing the observed sample, they can identify the population size that maximizes the likelihood of the data. This provides an estimate of the unknown population size.
The paper includes a detailed mathematical derivation of the estimation procedure and demonstrates its performance on both simulated and real-world data. The authors compare their approach to alternative methods and show that it can provide accurate and robust population size estimates in a variety of contexts.
Critical Analysis
The paper presents a well-designed and theoretically grounded approach for estimating unknown population sizes using the hypergeometric distribution. The authors provide a clear and rigorous explanation of the underlying mathematical concepts and their practical application.
One potential limitation of the method is that it relies on the assumption that the sample is drawn randomly and without replacement from the population. In some real-world scenarios, this assumption may not hold, and the hypergeometric model may not accurately capture the sampling process. The authors acknowledge this limitation and discuss potential extensions to relax this assumption.
Additionally, the paper does not explore the sensitivity of the population size estimates to factors such as sample size or the degree of imbalance between the "successes" and "failures" in the population. Further investigation into the robustness of the method under varying conditions could provide valuable insights.
Conclusion
This paper offers a principled and versatile technique for estimating the size of an unknown population using the hypergeometric distribution. By leveraging the properties of this probability distribution, the authors demonstrate a practical approach for inferring population sizes from limited sample data. The method has the potential to be useful in a wide range of applications where researchers or practitioners need to make inferences about the scale of a population based on partial observations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multinomial belief networks for healthcare data
H. C. Donker, D. Neijzen, J. de Jong, G. A. Lunter
0
0
Healthcare data from patient or population cohorts are often characterized by sparsity, high missingness and relatively small sample sizes. In addition, being able to quantify uncertainty is often important in a medical context. To address these analytical requirements we propose a deep generative Bayesian model for multinomial count data. We develop a collapsed Gibbs sampling procedure that takes advantage of a series of augmentation relations, inspired by the Zhou$unicode{x2013}$Cong$unicode{x2013}$Chen model. We visualise the model's ability to identify coherent substructures in the data using a dataset of handwritten digits. We then apply it to a large experimental dataset of DNA mutations in cancer and show that we can identify biologically meaningful clusters of mutational signatures in a fully data-driven way.
4/9/2024

Sample-efficient neural likelihood-free Bayesian inference of implicit HMMs
Sanmitra Ghosh, Paul J. Birrell, Daniela De Angelis
0
0
Likelihood-free inference methods based on neural conditional density estimation were shown to drastically reduce the simulation burden in comparison to classical methods such as ABC. When applied in the context of any latent variable model, such as a Hidden Markov model (HMM), these methods are designed to only estimate the parameters, rather than the joint distribution of the parameters and the hidden states. Naive application of these methods to a HMM, ignoring the inference of this joint posterior distribution, will thus produce an inaccurate estimate of the posterior predictive distribution, in turn hampering the assessment of goodness-of-fit. To rectify this problem, we propose a novel, sample-efficient likelihood-free method for estimating the high-dimensional hidden states of an implicit HMM. Our approach relies on learning directly the intractable posterior distribution of the hidden states, using an autoregressive-flow, by exploiting the Markov property. Upon evaluating our approach on some implicit HMMs, we found that the quality of the estimates retrieved using our method is comparable to what can be achieved using a much more computationally expensive SMC algorithm.
5/6/2024

Adaptive Online Bayesian Estimation of Frequency Distributions with Local Differential Privacy
Soner Aydin, Sinan Yildirim
0
0
We propose a novel Bayesian approach for the adaptive and online estimation of the frequency distribution of a finite number of categories under the local differential privacy (LDP) framework. The proposed algorithm performs Bayesian parameter estimation via posterior sampling and adapts the randomization mechanism for LDP based on the obtained posterior samples. We propose a randomized mechanism for LDP which uses a subset of categories as an input and whose performance depends on the selected subset and the true frequency distribution. By using the posterior sample as an estimate of the frequency distribution, the algorithm performs a computationally tractable subset selection step to maximize the utility of the privatized response of the next user. We propose several utility functions related to well-known information metrics, such as (but not limited to) Fisher information matrix, total variation distance, and information entropy. We compare each of these utility metrics in terms of their computational complexity. We employ stochastic gradient Langevin dynamics for posterior sampling, a computationally efficient approximate Markov chain Monte Carlo method. We provide a theoretical analysis showing that (i) the posterior distribution targeted by the algorithm converges to the true parameter even for approximate posterior sampling, and (ii) the algorithm selects the optimal subset with high probability if posterior sampling is performed exactly. We also provide numerical results that empirically demonstrate the estimation accuracy of our algorithm where we compare it with nonadaptive and semi-adaptive approaches under experimental settings with various combinations of privacy parameters and population distribution parameters.
5/14/2024
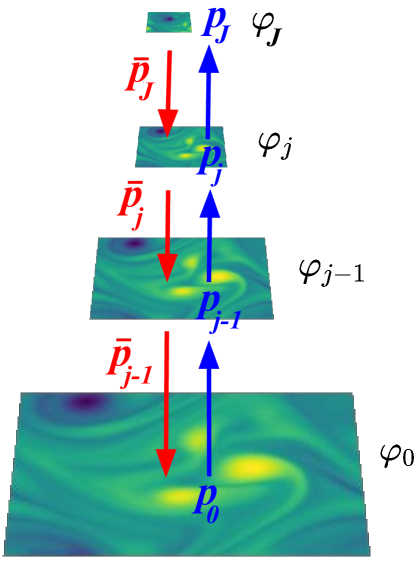
Hierarchic Flows to Estimate and Sample High-dimensional Probabilities
Etienne Lempereur, St'ephane Mallat
0
0
Finding low-dimensional interpretable models of complex physical fields such as turbulence remains an open question, 80 years after the pioneer work of Kolmogorov. Estimating high-dimensional probability distributions from data samples suffers from an optimization and an approximation curse of dimensionality. It may be avoided by following a hierarchic probability flow from coarse to fine scales. This inverse renormalization group is defined by conditional probabilities across scales, renormalized in a wavelet basis. For a $varphi^4$ scalar potential, sampling these hierarchic models avoids the critical slowing down at the phase transition. An outstanding issue is to also approximate non-Gaussian fields having long-range interactions in space and across scales. We introduce low-dimensional models with robust multiscale approximations of high order polynomial energies. They are calculated with a second wavelet transform, which defines interactions over two hierarchies of scales. We estimate and sample these wavelet scattering models to generate 2D vorticity fields of turbulence, and images of dark matter densities.
5/7/2024