Estimation of conditional average treatment effects on distributed data: A privacy-preserving approach
2402.02672
0
0
📉
Abstract
Estimation of conditional average treatment effects (CATEs) is an important topic in sciences. CATEs can be estimated with high accuracy if distributed data across multiple parties can be centralized. However, it is difficult to aggregate such data owing to privacy concerns. To address this issue, we proposed data collaboration double machine learning, a method that can estimate CATE models with privacy preservation of distributed data, and evaluated the method through simulations. Our contributions are summarized in the following three points. First, our method enables estimation and testing of semi-parametric CATE models without iterative communication on distributed data. Semi-parametric CATE models enable estimation and testing that is more robust to model mis-specification than parametric models. Second, our method enables collaborative estimation between multiple time points and different parties. Third, our method performed equally or better than other methods in simulations using synthetic, semi-synthetic and real-world datasets.
Create account to get full access
Overview
- Estimating conditional average treatment effects (CATEs) is an important task in various scientific fields
- CATEs can be estimated more accurately when data from multiple parties is centralized, but this is difficult due to privacy concerns
- The researchers propose a method called "data collaboration double machine learning" to estimate CATE models while preserving the privacy of distributed data
Plain English Explanation
The researchers have developed a new way to estimate conditional average treatment effects (CATEs). CATEs are important measurements that help scientists understand the effects of different interventions or treatments on a population.
Typically, estimating CATEs accurately requires combining data from multiple sources. However, this can be challenging because organizations may be unwilling to share their private data. The researchers' new method, called "data collaboration double machine learning", allows CATE models to be built without directly sharing the underlying data.
This approach has several key benefits:
-
It enables the use of more robust semi-parametric CATE models that are less sensitive to model assumptions compared to simpler parametric models.
-
It allows collaboration between multiple parties and across different time periods, further improving the accuracy of the CATE estimates.
-
In simulations using synthetic, semi-synthetic, and real-world datasets, the method performed equally well or better than other approaches for estimating CATEs.
Overall, this new technique helps address the challenge of estimating CATEs accurately while respecting the privacy of distributed data sources. This could lead to better insights and decision-making in a wide range of scientific fields.
Technical Explanation
The researchers propose a method called "data collaboration double machine learning" to estimate conditional average treatment effects (CATEs) from distributed data sources while preserving privacy.
The key innovations of this approach are:
-
Semi-parametric CATE models: The method enables the estimation and testing of semi-parametric CATE models, which are more robust to model mis-specification than simpler parametric models. This is achieved without the need for iterative communication between data parties.
-
Collaborative estimation: The method supports collaborative estimation of CATE models between multiple time points and different parties, further improving the accuracy of the estimates.
-
Performance evaluation: In simulations using synthetic, semi-synthetic, and real-world datasets, the proposed method performed equally or better than other approaches for estimating CATEs, such as conformal convolution Monte Carlo meta-learners and empirical analysis of model selection for heterogeneous causal effects.
The researchers demonstrate through these simulations that their data collaboration double machine learning approach can effectively estimate CATEs while preserving the privacy of the underlying data sources, which is a significant challenge addressed by this work.
Critical Analysis
The researchers acknowledge several caveats and limitations of their approach:
-
The method relies on certain assumptions, such as the availability of valid instrumental variables and the correct specification of the outcome model. Violations of these assumptions could impact the accuracy of the CATE estimates.
-
The performance of the method may be sensitive to the choice of hyperparameters and the complexity of the underlying CATE model. Further research is needed to understand the robustness of the approach to these factors.
-
The paper does not provide a comprehensive analysis of the computational complexity and scalability of the proposed method, which could be important considerations for its practical deployment.
Additionally, one potential concern is the reliance on the availability of valid instrumental variables, which may not always be easy to identify in real-world settings. Bounds on the representation-induced confounding bias in treatment effect estimation could be a valuable area for further research to address this limitation.
Overall, the researchers have presented a novel and promising approach to estimating CATEs from distributed data sources while preserving privacy. However, further investigation into the method's robustness, scalability, and practical applicability would be valuable to fully assess its potential impact.
Conclusion
The researchers have developed a new method called "data collaboration double machine learning" to estimate conditional average treatment effects (CATEs) from distributed data sources while preserving the privacy of the underlying data. This approach offers several key benefits, including the ability to use more robust semi-parametric CATE models, support for collaborative estimation across multiple parties and time periods, and superior performance compared to other methods in simulations.
While the method has some limitations and caveats, it represents a significant advancement in addressing the challenge of estimating CATEs accurately when data cannot be centralized due to privacy concerns. This work could have important implications for a wide range of scientific fields that rely on understanding the heterogeneous effects of interventions or treatments on a population.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
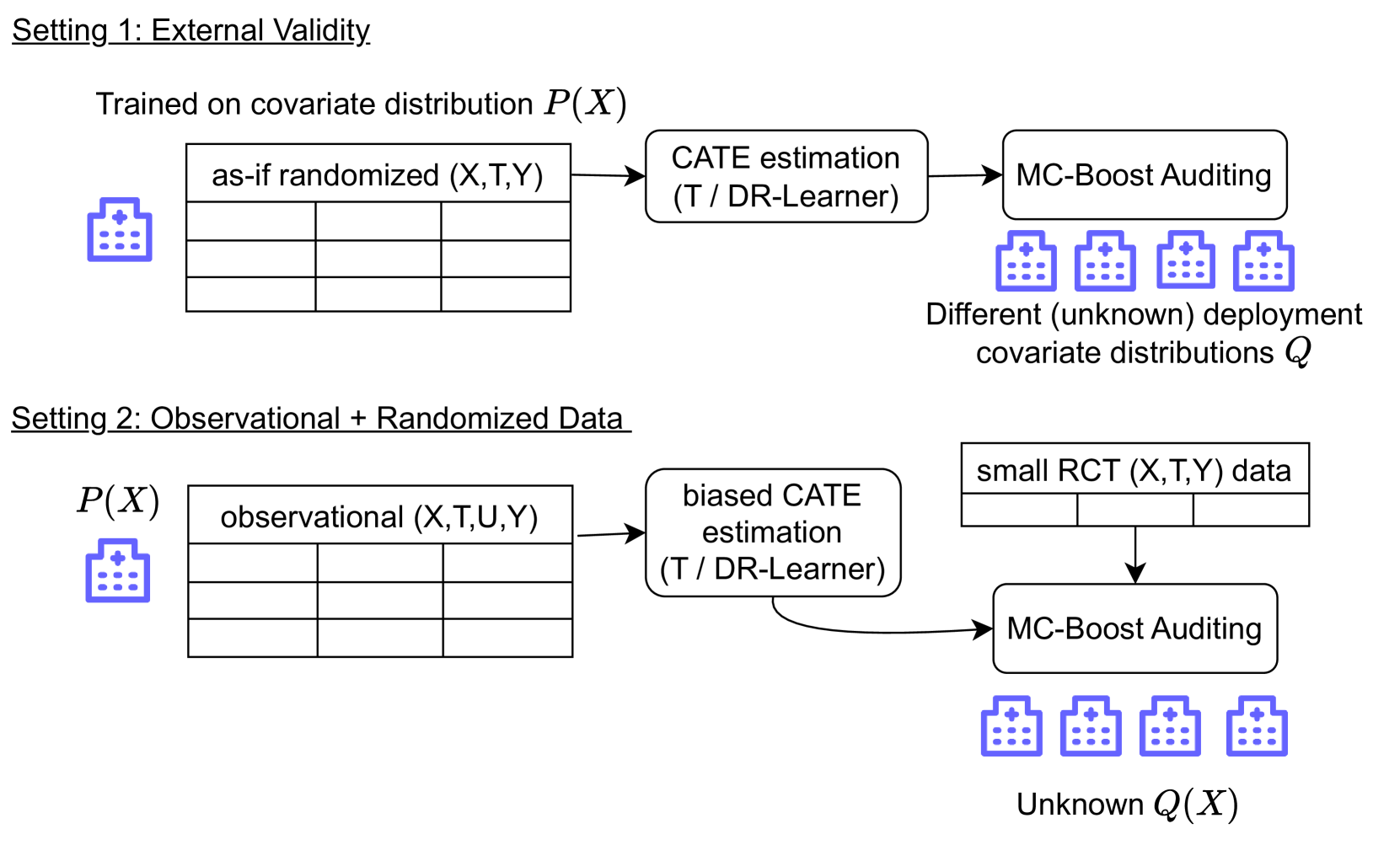
Multi-CATE: Multi-Accurate Conditional Average Treatment Effect Estimation Robust to Unknown Covariate Shifts
Christoph Kern, Michael Kim, Angela Zhou
0
0
Estimating heterogeneous treatment effects is important to tailor treatments to those individuals who would most likely benefit. However, conditional average treatment effect predictors may often be trained on one population but possibly deployed on different, possibly unknown populations. We use methodology for learning multi-accurate predictors to post-process CATE T-learners (differenced regressions) to become robust to unknown covariate shifts at the time of deployment. The method works in general for pseudo-outcome regression, such as the DR-learner. We show how this approach can combine (large) confounded observational and (smaller) randomized datasets by learning a confounded predictor from the observational dataset, and auditing for multi-accuracy on the randomized controlled trial. We show improvements in bias and mean squared error in simulations with increasingly larger covariate shift, and on a semi-synthetic case study of a parallel large observational study and smaller randomized controlled experiment. Overall, we establish a connection between methods developed for multi-distribution learning and achieve appealing desiderata (e.g. external validity) in causal inference and machine learning.
5/29/2024

Meta-Learners for Partially-Identified Treatment Effects Across Multiple Environments
Jonas Schweisthal, Dennis Frauen, Mihaela van der Schaar, Stefan Feuerriegel
0
0
Estimating the conditional average treatment effect (CATE) from observational data is relevant for many applications such as personalized medicine. Here, we focus on the widespread setting where the observational data come from multiple environments, such as different hospitals, physicians, or countries. Furthermore, we allow for violations of standard causal assumptions, namely, overlap within the environments and unconfoundedness. To this end, we move away from point identification and focus on partial identification. Specifically, we show that current assumptions from the literature on multiple environments allow us to interpret the environment as an instrumental variable (IV). This allows us to adapt bounds from the IV literature for partial identification of CATE by leveraging treatment assignment mechanisms across environments. Then, we propose different model-agnostic learners (so-called meta-learners) to estimate the bounds that can be used in combination with arbitrary machine learning models. We further demonstrate the effectiveness of our meta-learners across various experiments using both simulated and real-world data. Finally, we discuss the applicability of our meta-learners to partial identification in instrumental variable settings, such as randomized controlled trials with non-compliance.
6/5/2024
📈
Empirical Analysis of Model Selection for Heterogeneous Causal Effect Estimation
Divyat Mahajan, Ioannis Mitliagkas, Brady Neal, Vasilis Syrgkanis
0
0
We study the problem of model selection in causal inference, specifically for conditional average treatment effect (CATE) estimation. Unlike machine learning, there is no perfect analogue of cross-validation for model selection as we do not observe the counterfactual potential outcomes. Towards this, a variety of surrogate metrics have been proposed for CATE model selection that use only observed data. However, we do not have a good understanding regarding their effectiveness due to limited comparisons in prior studies. We conduct an extensive empirical analysis to benchmark the surrogate model selection metrics introduced in the literature, as well as the novel ones introduced in this work. We ensure a fair comparison by tuning the hyperparameters associated with these metrics via AutoML, and provide more detailed trends by incorporating realistic datasets via generative modeling. Our analysis suggests novel model selection strategies based on careful hyperparameter selection of CATE estimators and causal ensembling.
4/30/2024
🤯
Conformal Convolution and Monte Carlo Meta-learners for Predictive Inference of Individual Treatment Effects
Jef Jonkers, Jarne Verhaeghe, Glenn Van Wallendael, Luc Duchateau, Sofie Van Hoecke
0
0
Knowledge of the effect of interventions, known as the treatment effect, is paramount for decision-making. Approaches to estimating this treatment effect using conditional average treatment effect (CATE) meta-learners often provide only a point estimate of this treatment effect, while additional uncertainty quantification is frequently desired to enhance decision-making confidence. To address this, we introduce two novel approaches: the conformal convolution T-learner (CCT-learner) and conformal Monte Carlo (CMC) meta-learners. The approaches leverage weighted conformal predictive systems (WCPS), Monte Carlo sampling, and CATE meta-learners to generate predictive distributions of individual treatment effect (ITE) that could enhance individualized decision-making. Although we show how assumptions about the noise distribution of the outcome influence the uncertainty predictions, our experiments demonstrate that the CCT- and CMC meta-learners achieve strong coverage while maintaining narrow interval widths. They also generate probabilistically calibrated predictive distributions, providing reliable ranges of ITEs across various synthetic and semi-synthetic datasets. Code: https://github.com/predict-idlab/cct-cmc
6/13/2024