Bounds on Representation-Induced Confounding Bias for Treatment Effect Estimation
2311.11321
0
0
👀
Abstract
State-of-the-art methods for conditional average treatment effect (CATE) estimation make widespread use of representation learning. Here, the idea is to reduce the variance of the low-sample CATE estimation by a (potentially constrained) low-dimensional representation. However, low-dimensional representations can lose information about the observed confounders and thus lead to bias, because of which the validity of representation learning for CATE estimation is typically violated. In this paper, we propose a new, representation-agnostic refutation framework for estimating bounds on the representation-induced confounding bias that comes from dimensionality reduction (or other constraints on the representations) in CATE estimation. First, we establish theoretically under which conditions CATE is non-identifiable given low-dimensional (constrained) representations. Second, as our remedy, we propose a neural refutation framework which performs partial identification of CATE or, equivalently, aims at estimating lower and upper bounds of the representation-induced confounding bias. We demonstrate the effectiveness of our bounds in a series of experiments. In sum, our refutation framework is of direct relevance in practice where the validity of CATE estimation is of importance.
Create account to get full access
Overview
- This paper proposes a new framework for estimating bounds on the bias introduced by using low-dimensional representations in conditional average treatment effect (CATE) estimation.
- CATE estimation is an important task in causal inference, but existing state-of-the-art methods that use representation learning can introduce bias by losing information about observed confounders.
- The paper establishes theoretical conditions under which CATE is non-identifiable given low-dimensional representations, and introduces a neural refutation framework to partially identify CATE and estimate bounds on the representation-induced confounding bias.
Plain English Explanation
When trying to understand the causal effects of an intervention or treatment, researchers often use a statistical measure called the conditional average treatment effect (CATE). This tells us the average effect of the treatment, but only for a specific group or set of characteristics.
A common approach to estimating CATE is to use representation learning - reducing the information about the observed characteristics (confounders) down to a lower-dimensional form. This can help reduce the variance in the CATE estimate, especially when dealing with small datasets.
However, this dimensionality reduction can also lose important information about the confounders, which can then introduce bias into the CATE estimate. This means the CATE estimate may not accurately reflect the true causal effect.
This paper proposes a new refutation framework to address this issue. First, it establishes the theoretical conditions under which CATE estimation becomes non-identifiable when using low-dimensional representations. Then, it introduces a neural network-based method to partially identify the CATE and estimate bounds on the bias introduced by the dimensionality reduction.
Through experiments, the authors demonstrate the effectiveness of their approach in bounding the representation-induced confounding bias. This is an important contribution, as accurately estimating CATE is crucial in many real-world applications where causal inference is needed, such as policy evaluation or dynamic network analysis.
Technical Explanation
The key insight of this paper is that while representation learning can help reduce the variance in CATE estimation, it can also introduce bias by losing information about observed confounders. The authors first establish the theoretical conditions under which CATE becomes non-identifiable given low-dimensional representations.
To address this issue, the authors propose a neural refutation framework that performs partial identification of CATE. This means instead of trying to point-identify the CATE, the framework aims to estimate lower and upper bounds on the CATE to account for the representation-induced confounding bias.
The framework works by training a neural network to generate multiple representations of the confounders, each with different levels of dimensionality reduction. These representations are then used to estimate bounds on the CATE that are valid regardless of the true underlying representation.
The authors demonstrate the effectiveness of their approach through a series of experiments, showing that their bounds successfully capture the true CATE even when representation learning introduces substantial bias. This is an important contribution, as it provides a way to quantify the uncertainty in CATE estimates due to dimensionality reduction, which is crucial for causal sensitivity analysis and maintaining data confidentiality.
Critical Analysis
One potential limitation of this work is that it focuses solely on the bias introduced by dimensionality reduction in representation learning, and does not consider other sources of bias that may arise in CATE estimation, such as model misspecification or violation of the unconfoundedness assumption.
Additionally, the authors' proposed neural refutation framework, while effective, may be computationally intensive, especially for large-scale applications. Further research could explore more efficient or scalable methods for estimating the bounds on representation-induced confounding bias.
That said, the authors do acknowledge these limitations and suggest several directions for future work, such as extending the framework to handle other sources of bias or exploring alternative approaches to partial identification of CATE. Overall, this paper makes an important contribution to the field of causal inference by providing a principled way to quantify and address the bias introduced by representation learning in CATE estimation.
Conclusion
This paper presents a new refutation framework for estimating bounds on the bias introduced by using low-dimensional representations in conditional average treatment effect (CATE) estimation. The authors establish the theoretical conditions under which CATE becomes non-identifiable given low-dimensional representations, and then propose a neural network-based method to partially identify CATE and estimate bounds on the representation-induced confounding bias.
Through experiments, the authors demonstrate the effectiveness of their approach in bounding the bias, which is an important contribution to the field of causal inference. Accurately estimating CATE is crucial for many real-world applications, such as policy evaluation and dynamic network analysis, where causal inference is needed. The proposed framework provides a way to quantify the uncertainty in CATE estimates due to dimensionality reduction, which can help researchers and practitioners make more informed decisions based on the available data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
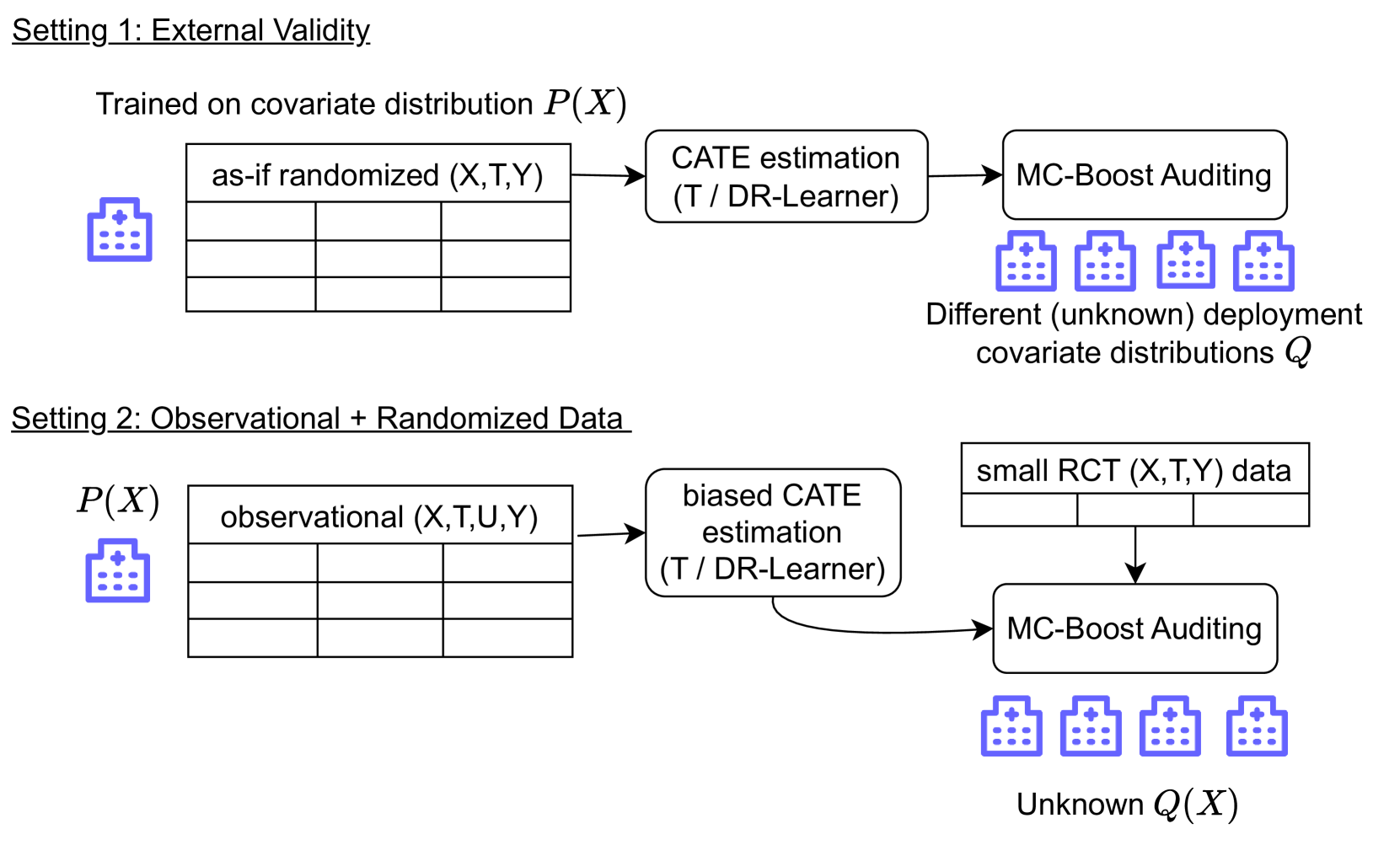
Multi-CATE: Multi-Accurate Conditional Average Treatment Effect Estimation Robust to Unknown Covariate Shifts
Christoph Kern, Michael Kim, Angela Zhou
0
0
Estimating heterogeneous treatment effects is important to tailor treatments to those individuals who would most likely benefit. However, conditional average treatment effect predictors may often be trained on one population but possibly deployed on different, possibly unknown populations. We use methodology for learning multi-accurate predictors to post-process CATE T-learners (differenced regressions) to become robust to unknown covariate shifts at the time of deployment. The method works in general for pseudo-outcome regression, such as the DR-learner. We show how this approach can combine (large) confounded observational and (smaller) randomized datasets by learning a confounded predictor from the observational dataset, and auditing for multi-accuracy on the randomized controlled trial. We show improvements in bias and mean squared error in simulations with increasingly larger covariate shift, and on a semi-synthetic case study of a parallel large observational study and smaller randomized controlled experiment. Overall, we establish a connection between methods developed for multi-distribution learning and achieve appealing desiderata (e.g. external validity) in causal inference and machine learning.
5/29/2024
📉
Estimation of conditional average treatment effects on distributed data: A privacy-preserving approach
Yuji Kawamata, Ryoki Motai, Yukihiko Okada, Akira Imakura, Tetsuya Sakurai
0
0
Estimation of conditional average treatment effects (CATEs) is an important topic in sciences. CATEs can be estimated with high accuracy if distributed data across multiple parties can be centralized. However, it is difficult to aggregate such data owing to privacy concerns. To address this issue, we proposed data collaboration double machine learning, a method that can estimate CATE models with privacy preservation of distributed data, and evaluated the method through simulations. Our contributions are summarized in the following three points. First, our method enables estimation and testing of semi-parametric CATE models without iterative communication on distributed data. Semi-parametric CATE models enable estimation and testing that is more robust to model mis-specification than parametric models. Second, our method enables collaborative estimation between multiple time points and different parties. Third, our method performed equally or better than other methods in simulations using synthetic, semi-synthetic and real-world datasets.
5/28/2024
📈
Empirical Analysis of Model Selection for Heterogeneous Causal Effect Estimation
Divyat Mahajan, Ioannis Mitliagkas, Brady Neal, Vasilis Syrgkanis
0
0
We study the problem of model selection in causal inference, specifically for conditional average treatment effect (CATE) estimation. Unlike machine learning, there is no perfect analogue of cross-validation for model selection as we do not observe the counterfactual potential outcomes. Towards this, a variety of surrogate metrics have been proposed for CATE model selection that use only observed data. However, we do not have a good understanding regarding their effectiveness due to limited comparisons in prior studies. We conduct an extensive empirical analysis to benchmark the surrogate model selection metrics introduced in the literature, as well as the novel ones introduced in this work. We ensure a fair comparison by tuning the hyperparameters associated with these metrics via AutoML, and provide more detailed trends by incorporating realistic datasets via generative modeling. Our analysis suggests novel model selection strategies based on careful hyperparameter selection of CATE estimators and causal ensembling.
4/30/2024

Meta-Learners for Partially-Identified Treatment Effects Across Multiple Environments
Jonas Schweisthal, Dennis Frauen, Mihaela van der Schaar, Stefan Feuerriegel
0
0
Estimating the conditional average treatment effect (CATE) from observational data is relevant for many applications such as personalized medicine. Here, we focus on the widespread setting where the observational data come from multiple environments, such as different hospitals, physicians, or countries. Furthermore, we allow for violations of standard causal assumptions, namely, overlap within the environments and unconfoundedness. To this end, we move away from point identification and focus on partial identification. Specifically, we show that current assumptions from the literature on multiple environments allow us to interpret the environment as an instrumental variable (IV). This allows us to adapt bounds from the IV literature for partial identification of CATE by leveraging treatment assignment mechanisms across environments. Then, we propose different model-agnostic learners (so-called meta-learners) to estimate the bounds that can be used in combination with arbitrary machine learning models. We further demonstrate the effectiveness of our meta-learners across various experiments using both simulated and real-world data. Finally, we discuss the applicability of our meta-learners to partial identification in instrumental variable settings, such as randomized controlled trials with non-compliance.
6/5/2024