EuroCropsML: A Time Series Benchmark Dataset For Few-Shot Crop Type Classification

0
Sign in to get full access
Overview
- EuroCropsML is a new benchmark dataset for few-shot crop type classification
- It provides satellite imagery time series data covering multiple crop types across Europe
- The dataset is intended to enable research on few-shot and transfer learning for remote sensing applications
Plain English Explanation
EuroCropsML is a new dataset that contains satellite imagery of different crop types over time across Europe. The goal of this dataset is to provide a standardized benchmark for testing machine learning models that can quickly learn to identify crop types from limited training data - a task known as "few-shot learning".
The dataset includes time series of satellite images captured throughout growing seasons, along with labels indicating the specific crop type present in each image. By having this consistent data, researchers can more easily compare the performance of different machine learning approaches for quickly recognizing crop types from just a few examples.
This is useful for real-world applications like precision agriculture, where farmers may want to rapidly identify crop types on their land to optimize operations. The EuroCropsML benchmark allows researchers to develop and evaluate models that can perform this crop classification task effectively with minimal training data.
Technical Explanation
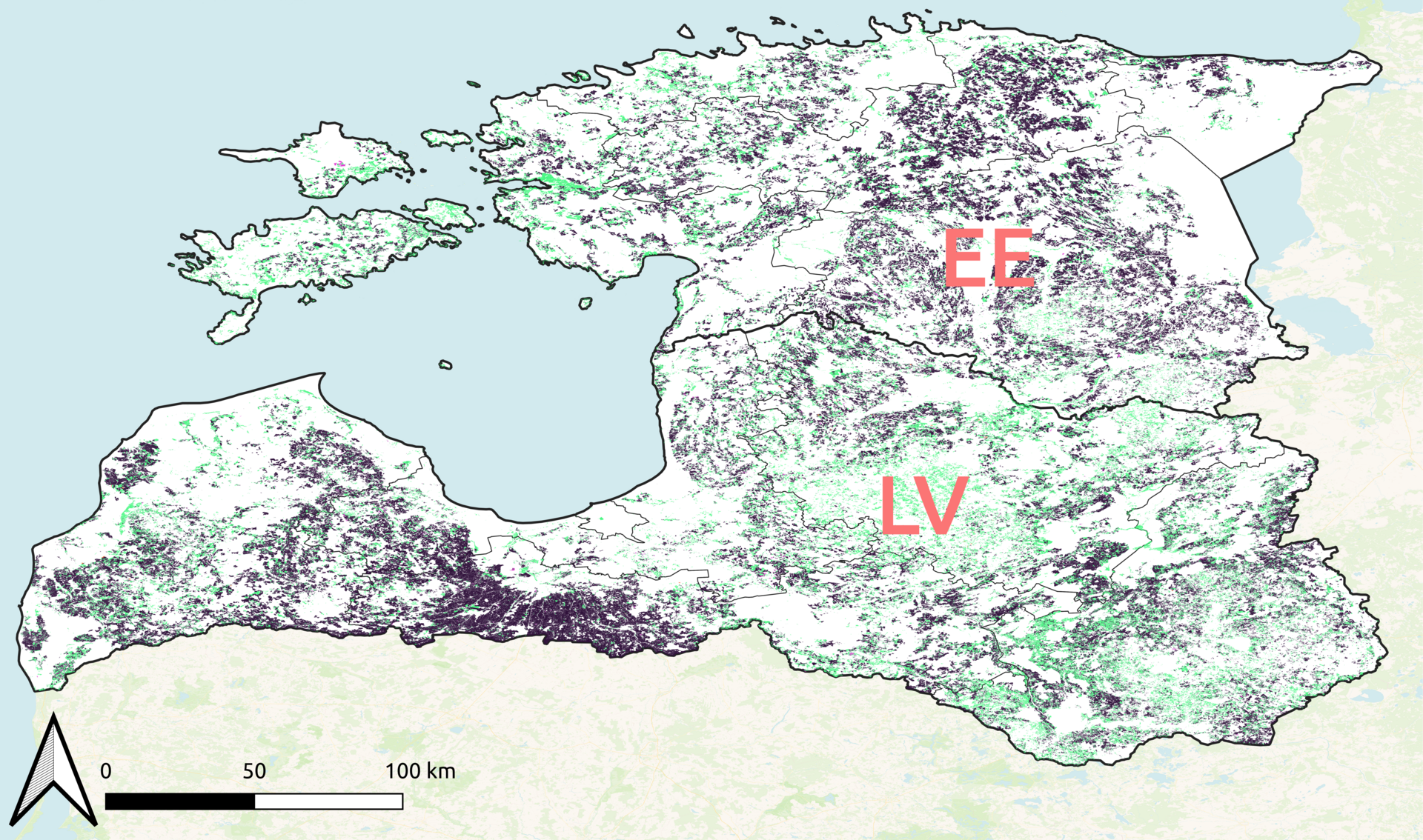
The EuroCropsML dataset consists of satellite image time series covering the growing seasons of 26 different crop types across Europe. The data was collected from the Copernicus Sentinel-2 satellite program and covers 90,000 distinct geographic locations over a 3-year period.
Each data point in the dataset represents a 64x64 pixel image patch extracted from the Sentinel-2 imagery, along with metadata about the specific crop type, location, and time of capture. The dataset is designed to support few-shot learning experiments, with only a small number of labeled examples provided per crop class.
To establish a standardized benchmark, the authors split the dataset into training, validation, and test sets, ensuring that the crop types and geographic regions do not overlap between the splits. This allows for rigorous evaluation of few-shot learning algorithms and their ability to generalize to new crop types and locations.
The authors provide baseline results using several popular few-shot learning techniques, including prototypical networks and metric learning approaches. These results demonstrate the challenges of the EuroCropsML benchmark and highlight opportunities for future research in few-shot crop type classification.
Critical Analysis
The EuroCropsML dataset represents an important contribution to the field of remote sensing and precision agriculture. By providing a standardized benchmark for few-shot crop type classification, the dataset enables more meaningful comparisons between different machine learning approaches and accelerates progress in this area.
However, the authors acknowledge several limitations of the dataset. First, the dataset is limited to a relatively small number of crop types, and the geographic coverage is restricted to Europe. Expanding the dataset to include a wider variety of crop types and regions would further enhance its utility.
Additionally, the authors note that the dataset may not fully capture the real-world variability in crop growing conditions, such as weather patterns or soil characteristics. Incorporating such contextual information could lead to more robust and generalizable models.
Finally, while the few-shot learning setting is a valuable focus, there may be value in also exploring the performance of models trained on larger datasets, as they could provide valuable insights or serve as strong baselines for the few-shot task.
Overall, the EuroCropsML dataset represents a significant step forward in the development of benchmarks for remote sensing applications, and the authors have laid the groundwork for exciting future research in this area.
Conclusion
The EuroCropsML dataset provides a valuable new benchmark for few-shot crop type classification using satellite imagery time series data. By standardizing the data and evaluation protocol, the dataset enables more rigorous and comparable research in this important domain.
The dataset's focus on few-shot learning is particularly promising, as it aligns with real-world precision agriculture applications where farmers may need to quickly identify crop types with limited training data. The baseline results presented by the authors highlight the challenges of this task and point to exciting avenues for future research.
As the field of remote sensing and earth observation continues to evolve, benchmarks like EuroCropsML will play a crucial role in driving innovation and ensuring that new machine learning techniques can be effectively applied to real-world problems. The dataset's open-source nature and clear documentation make it an accessible resource for the broader research community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EuroCropsML: A Time Series Benchmark Dataset For Few-Shot Crop Type Classification
Joana Reuss, Jan Macdonald, Simon Becker, Lorenz Richter, Marco Korner
We introduce EuroCropsML, an analysis-ready remote sensing machine learning dataset for time series crop type classification of agricultural parcels in Europe. It is the first dataset designed to benchmark transnational few-shot crop type classification algorithms that supports advancements in algorithmic development and research comparability. It comprises 706 683 multi-class labeled data points across 176 classes, featuring annual time series of per-parcel median pixel values from Sentinel-2 L1C data for 2021, along with crop type labels and spatial coordinates. Based on the open-source EuroCrops collection, EuroCropsML is publicly available on Zenodo.
Read more7/25/2024
0
An Open and Large-Scale Dataset for Multi-Modal Climate Change-aware Crop Yield Predictions
Fudong Lin, Kaleb Guillot, Summer Crawford, Yihe Zhang, Xu Yuan, Nian-Feng Tzeng
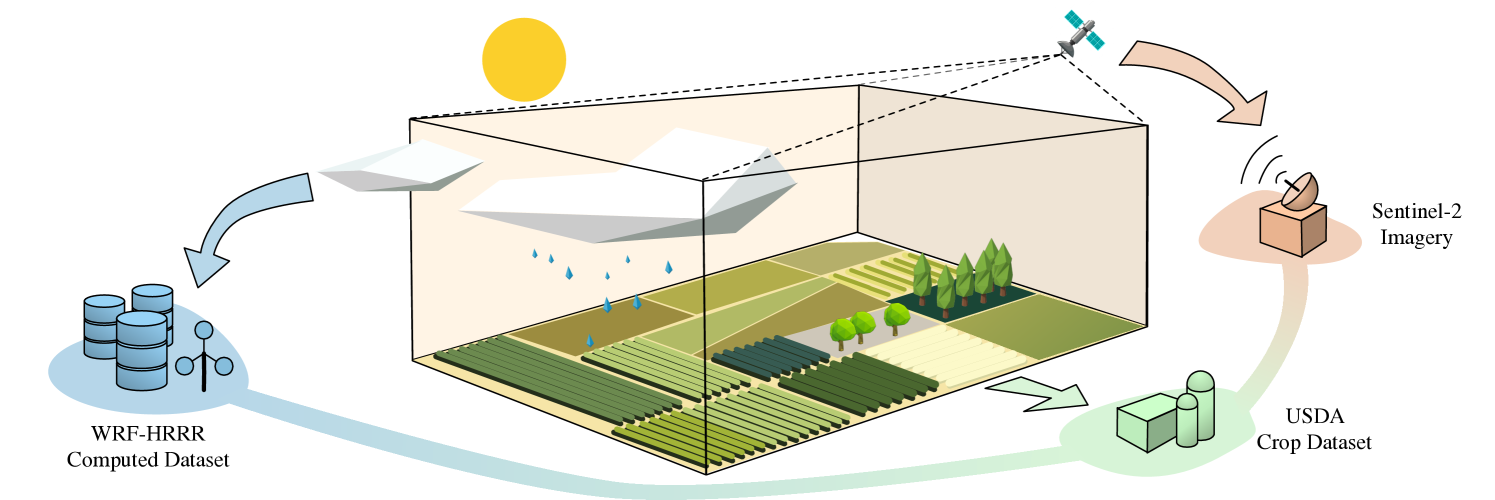
Precise crop yield predictions are of national importance for ensuring food security and sustainable agricultural practices. While AI-for-science approaches have exhibited promising achievements in solving many scientific problems such as drug discovery, precipitation nowcasting, etc., the development of deep learning models for predicting crop yields is constantly hindered by the lack of an open and large-scale deep learning-ready dataset with multiple modalities to accommodate sufficient information. To remedy this, we introduce the CropNet dataset, the first terabyte-sized, publicly available, and multi-modal dataset specifically targeting climate change-aware crop yield predictions for the contiguous United States (U.S.) continent at the county level. Our CropNet dataset is composed of three modalities of data, i.e., Sentinel-2 Imagery, WRF-HRRR Computed Dataset, and USDA Crop Dataset, for over 2200 U.S. counties spanning 6 years (2017-2022), expected to facilitate researchers in developing versatile deep learning models for timely and precisely predicting crop yields at the county-level, by accounting for the effects of both short-term growing season weather variations and long-term climate change on crop yields. Besides, we develop the CropNet package, offering three types of APIs, for facilitating researchers in downloading the CropNet data on the fly over the time and region of interest, and flexibly building their deep learning models for accurate crop yield predictions. Extensive experiments have been conducted on our CropNet dataset via employing various types of deep learning solutions, with the results validating the general applicability and the efficacy of the CropNet dataset in climate change-aware crop yield predictions.
Read more6/18/2024
📊
0
A Novel Fusion of Optical and Radar Satellite Data for Crop Phenology Estimation using Machine Learning and Cloud Computing
Shahab Aldin Shojaeezadeh, Abdelrazek Elnashar, Tobias Karl David Weber
Crop phenology determines crop growth stages and is valuable information for decision makers to plant and adapt agricultural management strategies to enhance food security. In the era of big Earth observation data ubiquity, attempts have been made to accurately predict crop phenology based on Remote Sensing (RS) data. However, most studies either focused on large scale interpretations of phenology or developed methods which are not adequate to help crop modeler communities on leveraging the value of RS data evaluated using more accurate and confident methods. Here, we estimate phenological developments for eight major crops and 13 phenological stages across Germany at 30m scale using a novel framework which fuses Landsat and Sentinel 2 (Harmonized Landsat and Sentinel data base; HLS) and radar of Sentinel 1 with a Machine Learning (ML) model. We proposed a thorough feature fusion analysis to find the best combinations of RS data on detecting phenological developments based on the national phenology network of Germany (German Meteorological Service; DWD) between 2017 and 2021. The nation-wide predicted crop phenology at 30 m resolution showed a very high precision of R2 > 0.9 and a very low Mean Absolute Error (MAE) < 2 (days). These results indicate that our fusing strategy of optical and radar datasets is highly performant with an accuracy highly relevant for practical applications, too. The subsequent uncertainty analysis indicated that fusing optical and radar data increases the reliability of the RS predicted crop growth stages. These improvements are expected to be useful for crop model calibrations and evaluations, facilitate informed agricultural decisions, and contribute to sustainable food production to address the increasing global food demand.
Read more9/4/2024

0
GeoPlant: Spatial Plant Species Prediction Dataset
Lukas Picek, Christophe Botella, Maximilien Servajean, C'esar Leblanc, R'emi Palard, Th'eo Larcher, Benjamin Deneu, Diego Marcos, Pierre Bonnet, Alexis Joly
The difficulty of monitoring biodiversity at fine scales and over large areas limits ecological knowledge and conservation efforts. To fill this gap, Species Distribution Models (SDMs) predict species across space from spatially explicit features. Yet, they face the challenge of integrating the rich but heterogeneous data made available over the past decade, notably millions of opportunistic species observations and standardized surveys, as well as multi-modal remote sensing data. In light of that, we have designed and developed a new European-scale dataset for SDMs at high spatial resolution (10-50 m), including more than 10k species (i.e., most of the European flora). The dataset comprises 5M heterogeneous Presence-Only records and 90k exhaustive Presence-Absence survey records, all accompanied by diverse environmental rasters (e.g., elevation, human footprint, and soil) that are traditionally used in SDMs. In addition, it provides Sentinel-2 RGB and NIR satellite images with 10 m resolution, a 20-year time-series of climatic variables, and satellite time-series from the Landsat program. In addition to the data, we provide an openly accessible SDM benchmark (hosted on Kaggle), which has already attracted an active community and a set of strong baselines for single predictor/modality and multimodal approaches. All resources, e.g., the dataset, pre-trained models, and baseline methods (in the form of notebooks), are available on Kaggle, allowing one to start with our dataset literally with two mouse clicks.
Read more8/27/2024