Evaluating Text-to-Visual Generation with Image-to-Text Generation
2404.01291
0
0
🛸
Abstract
Despite significant progress in generative AI, comprehensive evaluation remains challenging because of the lack of effective metrics and standardized benchmarks. For instance, the widely-used CLIPScore measures the alignment between a (generated) image and text prompt, but it fails to produce reliable scores for complex prompts involving compositions of objects, attributes, and relations. One reason is that text encoders of CLIP can notoriously act as a bag of words, conflating prompts such as the horse is eating the grass with the grass is eating the horse. To address this, we introduce the VQAScore, which uses a visual-question-answering (VQA) model to produce an alignment score by computing the probability of a Yes answer to a simple Does this figure show '{text}'? question. Though simpler than prior art, VQAScore computed with off-the-shelf models produces state-of-the-art results across many (8) image-text alignment benchmarks. We also compute VQAScore with an in-house model that follows best practices in the literature. For example, we use a bidirectional image-question encoder that allows image embeddings to depend on the question being asked (and vice versa). Our in-house model, CLIP-FlanT5, outperforms even the strongest baselines that make use of the proprietary GPT-4V. Interestingly, although we train with only images, VQAScore can also align text with video and 3D models. VQAScore allows researchers to benchmark text-to-visual generation using complex texts that capture the compositional structure of real-world prompts. We introduce GenAI-Bench, a more challenging benchmark with 1,600 compositional text prompts that require parsing scenes, objects, attributes, relationships, and high-order reasoning like comparison and logic. GenAI-Bench also offers over 15,000 human ratings for leading image and video generation models such as Stable Diffusion, DALL-E 3, and Gen2.
Create account to get full access
Overview
- Generative AI has made significant progress, but evaluating these models remains challenging due to a lack of effective metrics and standardized benchmarks.
- The widely-used CLIPScore measures alignment between a generated image and text prompt, but struggles with complex prompts involving compositions of objects, attributes, and relations.
- To address this, the researchers introduce the VQAScore, which uses a visual-question-answering (VQA) model to compute the probability of a "Yes" answer to a simple "Does this figure show '{text}'?" question.
- The VQAScore outperforms strong baselines, even when using off-the-shelf models, and can be applied to align text with images, video, and 3D models.
- The researchers also introduce GenAI-Bench, a more challenging benchmark with 1,600 compositional text prompts that require parsing scenes, objects, attributes, relationships, and high-order reasoning.
Plain English Explanation
Evaluating the performance of generative AI models, like those used to create images or videos from text prompts, is a significant challenge. The current standard metric, called CLIPScore, has trouble handling complex prompts that involve multiple objects, their attributes, and the relationships between them.
To address this, the researchers created a new metric called VQAScore. Instead of looking at the overall alignment between the prompt and the generated image, VQAScore uses a visual question-answering (VQA) model to determine how well the generated image answers the simple question "Does this figure show '{text}'?" This approach is more robust to the nuances of the prompt, as the VQA model can better understand the meaning and composition of the scene.
Interestingly, the researchers found that VQAScore works not only for images, but also for video and 3D models. This means it can be used to evaluate a wide range of generative AI outputs, not just static images.
To further test the capabilities of these models, the researchers also introduced a new benchmark called GenAI-Bench. This benchmark includes 1,600 complex text prompts that require the models to understand and parse scenes, objects, their attributes, the relationships between them, and even higher-order reasoning like comparison and logic.
By developing these more robust evaluation metrics and benchmarks, the researchers hope to drive progress in the field of generative AI, ensuring that these models can reliably create outputs that align with complex real-world prompts and scenarios.
Technical Explanation
The paper introduces the VQAScore, a new metric for evaluating the alignment between text prompts and the corresponding generated images, videos, or 3D models. Unlike the widely-used CLIPScore, which struggles with complex prompts, VQAScore uses a visual question-answering (VQA) model to determine the probability of a "Yes" answer to the question "Does this figure show '{text}'?"
The researchers experiment with both off-the-shelf and in-house VQA models. The in-house model, called CLIP-FlanT5, follows best practices from the literature, such as using a bidirectional image-question encoder that allows the image embeddings to depend on the question being asked (and vice versa). This model outperforms even the strongest baselines that use the proprietary GPT-4V.
To further challenge these generative AI models, the researchers introduce GenAI-Bench, a benchmark with 1,600 compositional text prompts that require parsing scenes, objects, attributes, relationships, and high-order reasoning like comparison and logic. This benchmark also includes over 15,000 human ratings for leading image and video generation models, such as Stable Diffusion, DALL-E 3, and Gen2.
Critical Analysis
The researchers acknowledge that while the VQAScore provides a more robust and reliable metric for evaluating generative AI, it still has limitations. The VQA model, even when trained on a large and diverse dataset, may struggle with certain types of prompts or edge cases that require more advanced reasoning or understanding of the world.
Additionally, the GenAI-Bench benchmark, while more challenging than previous benchmarks, may still not fully capture the complexity and nuance of real-world prompts and scenarios. There may be additional factors, such as cultural context or emotional impact, that are not accounted for in the current evaluation framework.
Further research is needed to explore more comprehensive and holistic approaches to evaluating generative AI, potentially incorporating insights from other fields, such as cognitive science and human-computer interaction. Ongoing collaboration between researchers, model developers, and end-users will be crucial in shaping the future of this rapidly evolving field.
Conclusion
The paper introduces two key advancements in the evaluation of generative AI: the VQAScore and the GenAI-Bench benchmark. The VQAScore provides a more robust and reliable metric for assessing the alignment between text prompts and the corresponding generated outputs, while the GenAI-Bench benchmark challenges these models with highly compositional and complex prompts.
By developing these tools, the researchers aim to drive progress in the field of generative AI, ensuring that these models can reliably create outputs that align with the nuanced and diverse prompts encountered in real-world scenarios. As the field continues to evolve, ongoing efforts to refine evaluation frameworks and expand the boundaries of what these models can achieve will be crucial in unlocking their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
GenAI-Bench: Evaluating and Improving Compositional Text-to-Visual Generation
Baiqi Li, Zhiqiu Lin, Deepak Pathak, Jiayao Li, Yixin Fei, Kewen Wu, Tiffany Ling, Xide Xia, Pengchuan Zhang, Graham Neubig, Deva Ramanan
0
0
While text-to-visual models now produce photo-realistic images and videos, they struggle with compositional text prompts involving attributes, relationships, and higher-order reasoning such as logic and comparison. In this work, we conduct an extensive human study on GenAI-Bench to evaluate the performance of leading image and video generation models in various aspects of compositional text-to-visual generation. We also compare automated evaluation metrics against our collected human ratings and find that VQAScore -- a metric measuring the likelihood that a VQA model views an image as accurately depicting the prompt -- significantly outperforms previous metrics such as CLIPScore. In addition, VQAScore can improve generation in a black-box manner (without finetuning) via simply ranking a few (3 to 9) candidate images. Ranking by VQAScore is 2x to 3x more effective than other scoring methods like PickScore, HPSv2, and ImageReward at improving human alignment ratings for DALL-E 3 and Stable Diffusion, especially on compositional prompts that require advanced visio-linguistic reasoning. We will release a new GenAI-Rank benchmark with over 40,000 human ratings to evaluate scoring metrics on ranking images generated from the same prompt. Lastly, we discuss promising areas for improvement in VQAScore, such as addressing fine-grained visual details. We will release all human ratings (over 80,000) to facilitate scientific benchmarking of both generative models and automated metrics.
6/26/2024
🏷️
Open-ended VQA benchmarking of Vision-Language models by exploiting Classification datasets and their semantic hierarchy
Simon Ging, Mar'ia A. Bravo, Thomas Brox
0
0
The evaluation of text-generative vision-language models is a challenging yet crucial endeavor. By addressing the limitations of existing Visual Question Answering (VQA) benchmarks and proposing innovative evaluation methodologies, our research seeks to advance our understanding of these models' capabilities. We propose a novel VQA benchmark based on well-known visual classification datasets which allows a granular evaluation of text-generative vision-language models and their comparison with discriminative vision-language models. To improve the assessment of coarse answers on fine-grained classification tasks, we suggest using the semantic hierarchy of the label space to ask automatically generated follow-up questions about the ground-truth category. Finally, we compare traditional NLP and LLM-based metrics for the problem of evaluating model predictions given ground-truth answers. We perform a human evaluation study upon which we base our decision on the final metric. We apply our benchmark to a suite of vision-language models and show a detailed comparison of their abilities on object, action, and attribute classification. Our contributions aim to lay the foundation for more precise and meaningful assessments, facilitating targeted progress in the exciting field of vision-language modeling.
5/7/2024
Bringing Textual Prompt to AI-Generated Image Quality Assessment
Bowen Qu, Haohui Li, Wei Gao
0
0
AI-Generated Images (AGIs) have inherent multimodal nature. Unlike traditional image quality assessment (IQA) on natural scenarios, AGIs quality assessment (AGIQA) takes the correspondence of image and its textual prompt into consideration. This is coupled in the ground truth score, which confuses the unimodal IQA methods. To solve this problem, we introduce IP-IQA (AGIs Quality Assessment via Image and Prompt), a multimodal framework for AGIQA via corresponding image and prompt incorporation. Specifically, we propose a novel incremental pretraining task named Image2Prompt for better understanding of AGIs and their corresponding textual prompts. An effective and efficient image-prompt fusion module, along with a novel special [QA] token, are also applied. Both are plug-and-play and beneficial for the cooperation of image and its corresponding prompt. Experiments demonstrate that our IP-IQA achieves the state-of-the-art on AGIQA-1k and AGIQA-3k datasets. Code will be available at https://github.com/Coobiw/IP-IQA.
5/22/2024
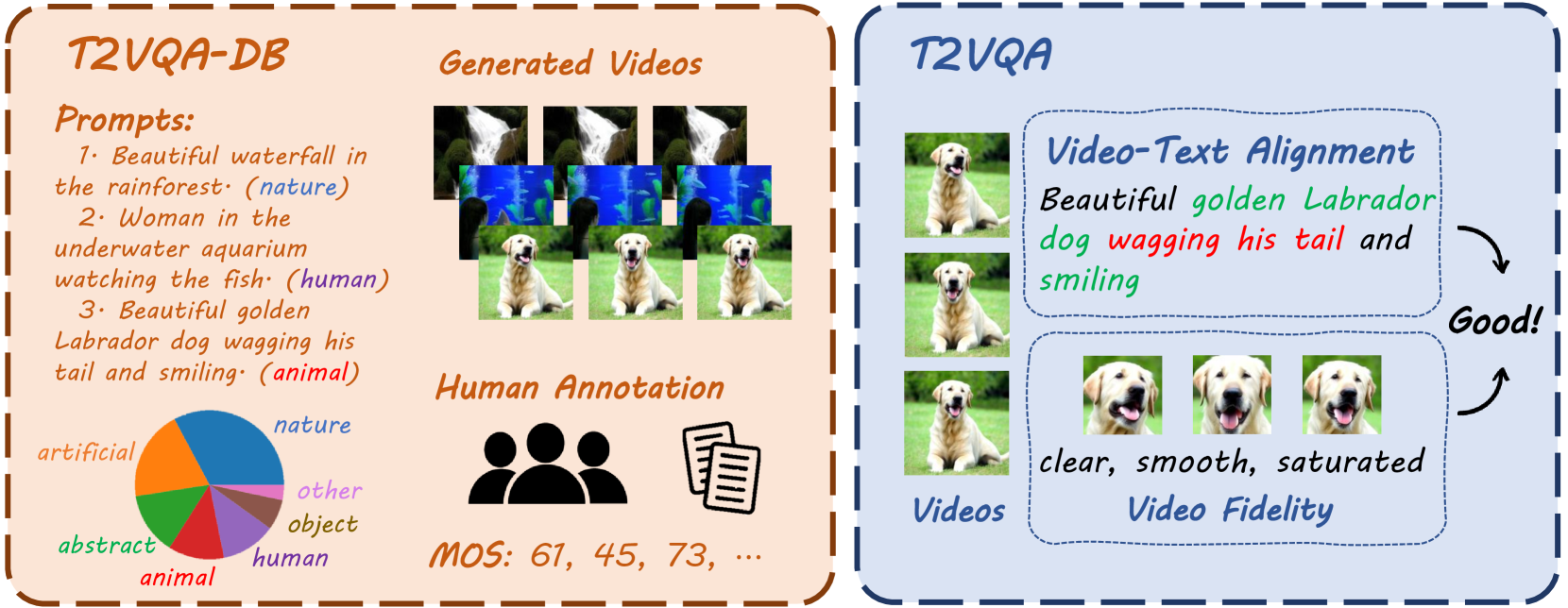
Subjective-Aligned Dataset and Metric for Text-to-Video Quality Assessment
Tengchuan Kou, Xiaohong Liu, Zicheng Zhang, Chunyi Li, Haoning Wu, Xiongkuo Min, Guangtao Zhai, Ning Liu
0
0
With the rapid development of generative models, Artificial Intelligence-Generated Contents (AIGC) have exponentially increased in daily lives. Among them, Text-to-Video (T2V) generation has received widespread attention. Though many T2V models have been released for generating high perceptual quality videos, there is still lack of a method to evaluate the quality of these videos quantitatively. To solve this issue, we establish the largest-scale Text-to-Video Quality Assessment DataBase (T2VQA-DB) to date. The dataset is composed of 10,000 videos generated by 9 different T2V models. We also conduct a subjective study to obtain each video's corresponding mean opinion score. Based on T2VQA-DB, we propose a novel transformer-based model for subjective-aligned Text-to-Video Quality Assessment (T2VQA). The model extracts features from text-video alignment and video fidelity perspectives, then it leverages the ability of a large language model to give the prediction score. Experimental results show that T2VQA outperforms existing T2V metrics and SOTA video quality assessment models. Quantitative analysis indicates that T2VQA is capable of giving subjective-align predictions, validating its effectiveness. The dataset and code will be released at https://github.com/QMME/T2VQA.
5/21/2024