Open-ended VQA benchmarking of Vision-Language models by exploiting Classification datasets and their semantic hierarchy
2402.07270
0
0
🏷️
Abstract
The evaluation of text-generative vision-language models is a challenging yet crucial endeavor. By addressing the limitations of existing Visual Question Answering (VQA) benchmarks and proposing innovative evaluation methodologies, our research seeks to advance our understanding of these models' capabilities. We propose a novel VQA benchmark based on well-known visual classification datasets which allows a granular evaluation of text-generative vision-language models and their comparison with discriminative vision-language models. To improve the assessment of coarse answers on fine-grained classification tasks, we suggest using the semantic hierarchy of the label space to ask automatically generated follow-up questions about the ground-truth category. Finally, we compare traditional NLP and LLM-based metrics for the problem of evaluating model predictions given ground-truth answers. We perform a human evaluation study upon which we base our decision on the final metric. We apply our benchmark to a suite of vision-language models and show a detailed comparison of their abilities on object, action, and attribute classification. Our contributions aim to lay the foundation for more precise and meaningful assessments, facilitating targeted progress in the exciting field of vision-language modeling.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper explores the challenges and importance of evaluating text-generative vision-language models.
- The researchers propose a novel Visual Question Answering (VQA) benchmark based on existing visual classification datasets to assess these models' capabilities.
- They introduce techniques to improve the evaluation of coarse answers on fine-grained classification tasks and compare traditional NLP and large language model (LLM) metrics for evaluating model predictions.
- The researchers apply their benchmark to a suite of vision-language models and provide a detailed comparison of their performance on object, action, and attribute classification.
Plain English Explanation
The paper focuses on evaluating text-generative vision-language models, which are AI systems that can generate text descriptions based on visual inputs. Evaluating these models is challenging, but crucial for understanding their capabilities.
The researchers propose a new VQA benchmark that uses well-known visual classification datasets. This allows them to assess text-generative models in a more granular way and compare them to discriminative models (which just classify inputs, rather than generating text).
To improve the evaluation of coarse answers on fine-grained tasks, the researchers suggest using the semantic hierarchy of the label space to automatically generate follow-up questions about the ground-truth category. This helps provide a more nuanced assessment.
They also compare traditional NLP metrics and LLM-based metrics for evaluating the model predictions against ground-truth answers. After a human evaluation study, they decide on the final metric to use.
Finally, the researchers apply their benchmark to a variety of vision-language models and provide a detailed comparison of the models' abilities to classify objects, actions, and attributes.
The goal of this work is to lay the foundation for more precise and meaningful assessments of vision-language models, which will facilitate targeted progress in this exciting field.
Technical Explanation
The researchers first address the limitations of existing VQA benchmarks, which they find insufficient for evaluating text-generative vision-language models. To overcome this, they propose a novel VQA benchmark based on well-known visual classification datasets such as ImageNet, COCO, and Visual Genome.
This new benchmark allows for a granular evaluation of text-generative models and their comparison with discriminative vision-language models. To improve the assessment of coarse answers on fine-grained classification tasks, the researchers suggest leveraging the semantic hierarchy of the label space. They automatically generate follow-up questions about the ground-truth category, which helps provide a more nuanced evaluation.
Additionally, the paper compares traditional NLP metrics (e.g., BLEU, METEOR, ROUGE) and LLM-based metrics (e.g., BERTScore, BLEURT) for evaluating model predictions against ground-truth answers. The researchers perform a human evaluation study to determine the most appropriate metric to use.
The researchers then apply their benchmark to a suite of vision-language models, including text-to-image models, and provide a detailed comparison of the models' abilities to classify objects, actions, and attributes.
Critical Analysis
The paper provides a comprehensive and innovative approach to evaluating text-generative vision-language models, addressing the limitations of existing VQA benchmarks. The proposed benchmark offers a more granular and nuanced assessment of these models' capabilities, which is crucial for driving progress in the field.
However, the paper does not explore the potential biases or limitations of the datasets used to construct the benchmark. There may be inherent biases in the visual classification datasets that could influence the evaluation results.
Additionally, the human evaluation study for selecting the final metric could be improved by involving a larger and more diverse group of participants to ensure the metric is truly representative of human judgments.
The researchers also do not address the potential ethical implications of developing more advanced text-generative vision-language models, such as the risk of generating biased or harmful content. This is an important consideration that should be addressed in future research.
Conclusion
This research paper presents a significant contribution to the field of vision-language modeling by proposing a novel VQA benchmark and advanced evaluation methodologies. The benchmark and techniques introduced in this work lay the foundation for more precise and meaningful assessments of text-generative vision-language models, which will facilitate targeted progress in this exciting and rapidly evolving field of AI.
The findings and insights from this study can inform the development of more effective and reliable vision-language models that can be deployed in a wide range of applications, from image captioning to visual question answering. The researchers' work highlights the importance of rigorous evaluation in advancing the capabilities of these transformative AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
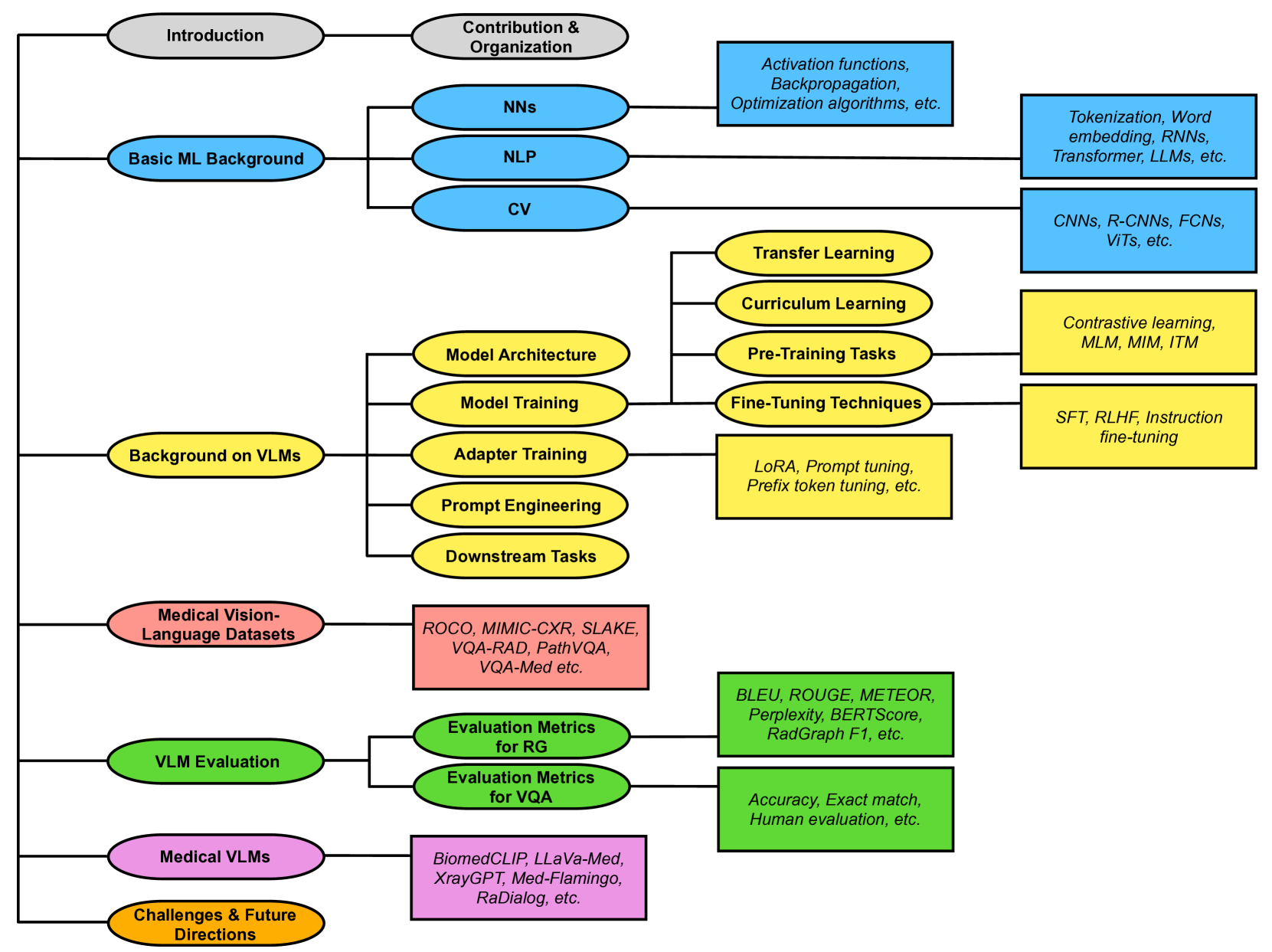
Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review
Iryna Hartsock, Ghulam Rasool
0
0
Medical vision-language models (VLMs) combine computer vision (CV) and natural language processing (NLP) to analyze visual and textual medical data. Our paper reviews recent advancements in developing VLMs specialized for healthcare, focusing on models designed for medical report generation and visual question answering (VQA). We provide background on NLP and CV, explaining how techniques from both fields are integrated into VLMs to enable learning from multimodal data. Key areas we address include the exploration of medical vision-language datasets, in-depth analyses of architectures and pre-training strategies employed in recent noteworthy medical VLMs, and comprehensive discussion on evaluation metrics for assessing VLMs' performance in medical report generation and VQA. We also highlight current challenges and propose future directions, including enhancing clinical validity and addressing patient privacy concerns. Overall, our review summarizes recent progress in developing VLMs to harness multimodal medical data for improved healthcare applications.
4/16/2024
🤔
TableVQA-Bench: A Visual Question Answering Benchmark on Multiple Table Domains
Yoonsik Kim, Moonbin Yim, Ka Yeon Song
0
0
In this paper, we establish a benchmark for table visual question answering, referred to as the TableVQA-Bench, derived from pre-existing table question-answering (QA) and table structure recognition datasets. It is important to note that existing datasets have not incorporated images or QA pairs, which are two crucial components of TableVQA. As such, the primary objective of this paper is to obtain these necessary components. Specifically, images are sourced either through the application of a textit{stylesheet} or by employing the proposed table rendering system. QA pairs are generated by exploiting the large language model (LLM) where the input is a text-formatted table. Ultimately, the completed TableVQA-Bench comprises 1,500 QA pairs. We comprehensively compare the performance of various multi-modal large language models (MLLMs) on TableVQA-Bench. GPT-4V achieves the highest accuracy among commercial and open-sourced MLLMs from our experiments. Moreover, we discover that the number of vision queries plays a significant role in TableVQA performance. To further analyze the capabilities of MLLMs in comparison to their LLM backbones, we investigate by presenting image-formatted tables to MLLMs and text-formatted tables to LLMs, respectively. Our findings suggest that processing visual inputs is more challenging than text inputs, as evidenced by the lower performance of MLLMs, despite generally requiring higher computational costs than LLMs. The proposed TableVQA-Bench and evaluation codes are available at href{https://github.com/naver-ai/tablevqabench}{https://github.com/naver-ai/tablevqabench}.
5/1/2024

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024
👀
Fusion of Domain-Adapted Vision and Language Models for Medical Visual Question Answering
Cuong Nhat Ha, Shima Asaadi, Sanjeev Kumar Karn, Oladimeji Farri, Tobias Heimann, Thomas Runkler
0
0
Vision-language models, while effective in general domains and showing strong performance in diverse multi-modal applications like visual question-answering (VQA), struggle to maintain the same level of effectiveness in more specialized domains, e.g., medical. We propose a medical vision-language model that integrates large vision and language models adapted for the medical domain. This model goes through three stages of parameter-efficient training using three separate biomedical and radiology multi-modal visual and text datasets. The proposed model achieves state-of-the-art performance on the SLAKE 1.0 medical VQA (MedVQA) dataset with an overall accuracy of 87.5% and demonstrates strong performance on another MedVQA dataset, VQA-RAD, achieving an overall accuracy of 73.2%.
4/26/2024