Evaluation of Language Models in the Medical Context Under Resource-Constrained Settings
2406.16611
0
0

Abstract
Since the emergence of the Transformer architecture, language model development has increased, driven by their promising potential. However, releasing these models into production requires properly understanding their behavior, particularly in sensitive domains such as medicine. Despite this need, the medical literature still lacks technical assessments of pre-trained language models, which are especially valuable in resource-constrained settings in terms of computational power or limited budget. To address this gap, we provide a comprehensive survey of language models in the medical domain. In addition, we selected a subset of these models for thorough evaluation, focusing on classification and text generation tasks. Our subset encompasses 53 models, ranging from 110 million to 13 billion parameters, spanning the three families of Transformer-based models and from diverse knowledge domains. This study employs a series of approaches for text classification together with zero-shot prompting instead of model training or fine-tuning, which closely resembles the limited resource setting in which many users of language models find themselves. Encouragingly, our findings reveal remarkable performance across various tasks and datasets, underscoring the latent potential of certain models to contain medical knowledge, even without domain specialization. Consequently, our study advocates for further exploration of model applications in medical contexts, particularly in resource-constrained settings. The code is available on https://github.com/anpoc/Language-models-in-medicine.
Create account to get full access
Overview
- This paper evaluates the performance of language models in the medical context, with a focus on resource-constrained settings.
- The researchers assess the capabilities of various language models, including state-of-the-art models like BERT and BioBERT, in tasks relevant to the medical domain.
- The study aims to provide insights into the limitations and strengths of these models in real-world, resource-limited scenarios, which is crucial for their effective deployment in healthcare applications.
Plain English Explanation
The paper investigates how well different language models, which are AI systems that can understand and generate human-like text, perform on medical-related tasks. The researchers focus on situations where there are limited resources, such as limited data or computational power, to see how the models hold up in more realistic conditions.
Language models have shown great potential in various applications, including healthcare, where they could assist doctors and nurses with tasks like summarizing patient records or answering medical questions. However, it's important to understand the limitations of these models, especially when the resources available are scarce.
The study evaluates the performance of state-of-the-art models like BERT and BioBERT on various medical-related tasks, such as classifying diseases or extracting relevant information from medical text. By testing the models in resource-constrained settings, the researchers aim to provide insights that can help developers and healthcare providers make informed decisions about how to best use these language models in real-world medical applications.
Technical Explanation
The paper presents a comprehensive evaluation of language models in the medical context, with a focus on resource-constrained settings. The researchers assess the performance of various language models, including BERT and BioBERT, on a range of medical tasks, such as disease classification, named entity recognition, and question answering.
To simulate resource-constrained scenarios, the authors experiment with different data sizes and computational budgets, and they also evaluate the models' ability to adapt to new medical domains. The results show that while state-of-the-art language models like BERT and BioBERT generally perform well on medical tasks, their performance can degrade significantly in resource-limited settings.
The paper provides detailed analyses of the models' strengths and weaknesses, and it offers insights into the design of language models that are better suited for deployment in real-world medical applications, where resources may be scarce. The findings have important implications for the development and use of language models in the healthcare sector, as they highlight the need to consider the practical constraints that may arise in clinical and research settings.
Critical Analysis
The paper provides a valuable and timely assessment of language models in the medical context, particularly in resource-constrained settings. The authors have carefully designed their experiments to simulate realistic conditions that healthcare providers and researchers may face, which is crucial for understanding the practical limitations of these models.
One potential limitation of the study is the scope of the medical tasks evaluated. While the authors cover several key areas, such as disease classification and named entity recognition, there may be other important medical tasks that were not included in the analysis. Additionally, the paper does not delve deeply into the specific reasons why the models' performance degrades in resource-constrained settings, which could be an area for further investigation.
Furthermore, the paper could have benefited from a more thorough discussion of the ethical implications of using language models in healthcare, particularly in terms of data privacy, bias, and the potential for misuse. As these models become more widely adopted, it will be critical to address these concerns and ensure that they are deployed responsibly and with appropriate safeguards.
Overall, this paper makes a significant contribution to the growing body of research on the use of language models in the medical domain. The insights provided can help guide the development of more robust and practical language models that can be effectively deployed in resource-limited healthcare settings, as highlighted in related studies such as Towards Building a Multilingual Language Model for Medicine and A Survey of Large Language Models in Medicine: Progress and Applications.
Conclusion
This paper presents a comprehensive evaluation of language models in the medical context, with a particular focus on resource-constrained settings. The researchers assess the performance of state-of-the-art models like BERT and BioBERT on a range of medical tasks, and their findings suggest that while these models can be effective in certain scenarios, their performance can degrade significantly when resources are limited.
The insights provided in this study are crucial for the development and deployment of language models in real-world healthcare applications, where resources may be scarce. The paper highlights the need for language models that are specifically designed for medical use cases and can adapt to the constraints of clinical and research settings.
Overall, this research contributes to the ongoing efforts to harness the power of language models in the medical domain, while also addressing the practical challenges that must be overcome to ensure their effective and responsible use in the healthcare sector.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
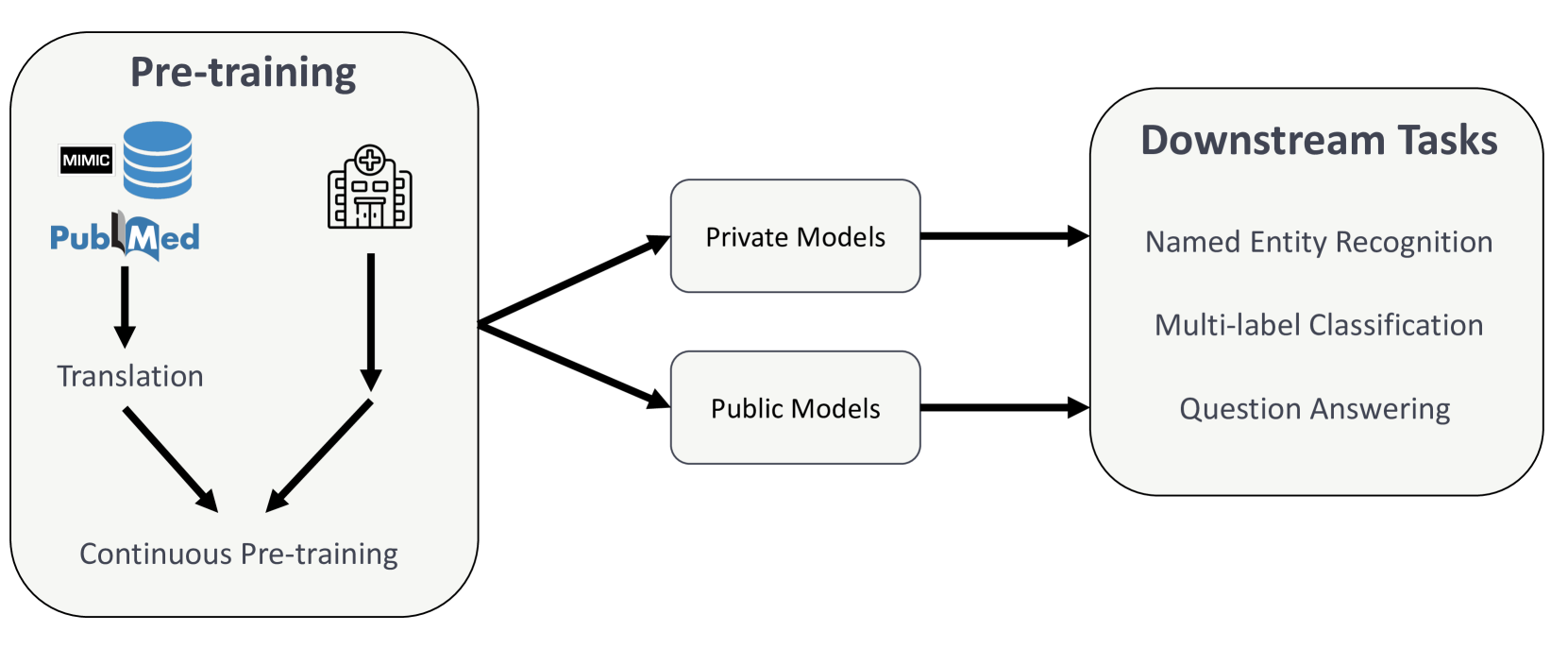
Comprehensive Study on German Language Models for Clinical and Biomedical Text Understanding
Ahmad Idrissi-Yaghir, Amin Dada, Henning Schafer, Kamyar Arzideh, Giulia Baldini, Jan Trienes, Max Hasin, Jeanette Bewersdorff, Cynthia S. Schmidt, Marie Bauer, Kaleb E. Smith, Jiang Bian, Yonghui Wu, Jorg Schlotterer, Torsten Zesch, Peter A. Horn, Christin Seifert, Felix Nensa, Jens Kleesiek, Christoph M. Friedrich
0
0
Recent advances in natural language processing (NLP) can be largely attributed to the advent of pre-trained language models such as BERT and RoBERTa. While these models demonstrate remarkable performance on general datasets, they can struggle in specialized domains such as medicine, where unique domain-specific terminologies, domain-specific abbreviations, and varying document structures are common. This paper explores strategies for adapting these models to domain-specific requirements, primarily through continuous pre-training on domain-specific data. We pre-trained several German medical language models on 2.4B tokens derived from translated public English medical data and 3B tokens of German clinical data. The resulting models were evaluated on various German downstream tasks, including named entity recognition (NER), multi-label classification, and extractive question answering. Our results suggest that models augmented by clinical and translation-based pre-training typically outperform general domain models in medical contexts. We conclude that continuous pre-training has demonstrated the ability to match or even exceed the performance of clinical models trained from scratch. Furthermore, pre-training on clinical data or leveraging translated texts have proven to be reliable methods for domain adaptation in medical NLP tasks.
5/9/2024
💬
Evaluating large language models in medical applications: a survey
Xiaolan Chen, Jiayang Xiang, Shanfu Lu, Yexin Liu, Mingguang He, Danli Shi
0
0
Large language models (LLMs) have emerged as powerful tools with transformative potential across numerous domains, including healthcare and medicine. In the medical domain, LLMs hold promise for tasks ranging from clinical decision support to patient education. However, evaluating the performance of LLMs in medical contexts presents unique challenges due to the complex and critical nature of medical information. This paper provides a comprehensive overview of the landscape of medical LLM evaluation, synthesizing insights from existing studies and highlighting evaluation data sources, task scenarios, and evaluation methods. Additionally, it identifies key challenges and opportunities in medical LLM evaluation, emphasizing the need for continued research and innovation to ensure the responsible integration of LLMs into clinical practice.
5/14/2024

A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
0
0
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
6/18/2024
💬
A Survey of Large Language Models in Medicine: Progress, Application, and Challenge
Hongjian Zhou, Fenglin Liu, Boyang Gu, Xinyu Zou, Jinfa Huang, Jinge Wu, Yiru Li, Sam S. Chen, Peilin Zhou, Junling Liu, Yining Hua, Chengfeng Mao, Chenyu You, Xian Wu, Yefeng Zheng, Lei Clifton, Zheng Li, Jiebo Luo, David A. Clifton
0
0
Large language models (LLMs), such as ChatGPT, have received substantial attention due to their capabilities for understanding and generating human language. While there has been a burgeoning trend in research focusing on the employment of LLMs in supporting different medical tasks (e.g., enhancing clinical diagnostics and providing medical education), a review of these efforts, particularly their development, practical applications, and outcomes in medicine, remains scarce. Therefore, this review aims to provide a detailed overview of the development and deployment of LLMs in medicine, including the challenges and opportunities they face. In terms of development, we provide a detailed introduction to the principles of existing medical LLMs, including their basic model structures, number of parameters, and sources and scales of data used for model development. It serves as a guide for practitioners in developing medical LLMs tailored to their specific needs. In terms of deployment, we offer a comparison of the performance of different LLMs across various medical tasks, and further compare them with state-of-the-art lightweight models, aiming to provide an understanding of the advantages and limitations of LLMs in medicine. Overall, in this review, we address the following questions: 1) What are the practices for developing medical LLMs 2) How to measure the medical task performance of LLMs in a medical setting? 3) How have medical LLMs been employed in real-world practice? 4) What challenges arise from the use of medical LLMs? and 5) How to more effectively develop and deploy medical LLMs? By answering these questions, this review aims to provide insights into the opportunities for LLMs in medicine and serve as a practical resource. We also maintain a regularly updated list of practical guides on medical LLMs at: https://github.com/AI-in-Health/MedLLMsPracticalGuide.
5/16/2024