Comprehensive Study on German Language Models for Clinical and Biomedical Text Understanding
2404.05694
0
0
Abstract
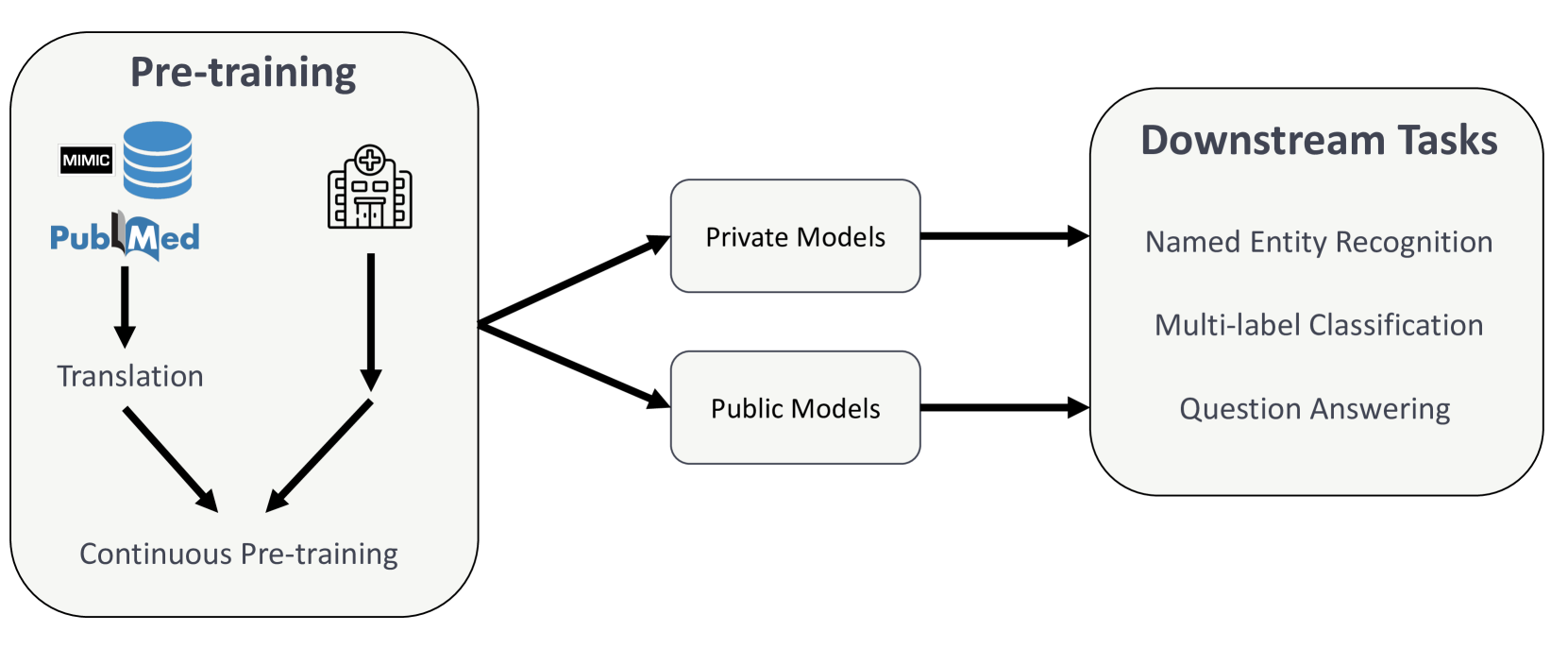
Recent advances in natural language processing (NLP) can be largely attributed to the advent of pre-trained language models such as BERT and RoBERTa. While these models demonstrate remarkable performance on general datasets, they can struggle in specialized domains such as medicine, where unique domain-specific terminologies, domain-specific abbreviations, and varying document structures are common. This paper explores strategies for adapting these models to domain-specific requirements, primarily through continuous pre-training on domain-specific data. We pre-trained several German medical language models on 2.4B tokens derived from translated public English medical data and 3B tokens of German clinical data. The resulting models were evaluated on various German downstream tasks, including named entity recognition (NER), multi-label classification, and extractive question answering. Our results suggest that models augmented by clinical and translation-based pre-training typically outperform general domain models in medical contexts. We conclude that continuous pre-training has demonstrated the ability to match or even exceed the performance of clinical models trained from scratch. Furthermore, pre-training on clinical data or leveraging translated texts have proven to be reliable methods for domain adaptation in medical NLP tasks.
Create account to get full access
Overview
- This paper presents a comprehensive study on German language models for clinical and biomedical text understanding.
- The authors investigate the performance of various pre-trained German language models on a range of downstream tasks in the healthcare and biomedical domains.
- The study provides valuable insights into the strengths and limitations of different language models and their applicability to specialized medical and scientific text.
Plain English Explanation
The paper focuses on evaluating how well different language models trained on German text can understand and process clinical and biomedical information in German. Language models are AI systems that have been trained on large amounts of text data to learn the patterns and structure of a language. The researchers tested several of these German language models on a variety of tasks related to medical and scientific text, such as identifying key entities, classifying the intent of text, and extracting relevant information.
By comparing the performance of the different models, the researchers were able to identify which ones work best for understanding specialized healthcare and biomedical text in German. This is important because being able to accurately process and extract information from medical and scientific documents can have significant real-world implications, such as improving clinical decision-making, enhancing research efforts, and developing more effective AI-powered healthcare applications.
The findings of this study provide guidance on which German language models are most suitable for tackling tasks in the medical and biomedical domains, and where there is room for further improvement in the development of language models tailored to these specialized fields.
Technical Explanation
The paper evaluates the performance of several pre-trained German language models, including CAMEMBERT-BIO, HealthBERT, and GermanBERT, on a range of clinical and biomedical text understanding tasks. These tasks include named entity recognition, intent detection, and relation extraction.
The authors first describe the various pre-training datasets used to develop the language models, including general German corpora as well as specialized medical and scientific literature. They then detail the experimental setup, including the downstream tasks, evaluation metrics, and fine-tuning procedures.
The results show that the language models exhibit varying performance across the different tasks, with some models, like CAMEMBERT-BIO, demonstrating stronger capabilities in clinical and biomedical text understanding compared to more general-purpose models. The paper also identifies areas where further improvements are needed, such as enhancing the models' ability to handle domain-specific terminology and complex clinical reasoning.
Critical Analysis
The paper provides a comprehensive and rigorous evaluation of German language models for healthcare and biomedical applications, which is a valuable contribution to the field. The authors have carefully designed their experiments and leveraged relevant datasets to assess the models' performance.
However, the paper could have delved deeper into some of the limitations and potential biases of the language models. For example, the authors do not discuss how the models might handle rare or uncommon medical terms, or how they perform on tasks that require deeper medical reasoning or understanding of complex clinical concepts.
Additionally, the paper could have explored the potential ethical and privacy implications of deploying these language models in real-world healthcare settings, where the handling of sensitive patient data is of utmost importance.
Further research could also investigate the transferability of these language models to other languages or healthcare systems, as well as the potential for continued pre-training or fine-tuning to improve their performance on specialized medical and scientific tasks.
Conclusion
This study offers a valuable contribution to the research on language models for clinical and biomedical text understanding in the German language. The findings provide important insights into the strengths and weaknesses of various pre-trained German language models, which can inform the development of more specialized and effective natural language processing tools for the healthcare and biomedical domains.
The authors' thorough evaluation and analysis of the language models' performance on a range of tasks serve as a useful reference for researchers and practitioners working on adapting language technology to the unique requirements of medical and scientific text processing. This work represents a significant step forward in advancing the state of the art in German-language AI for healthcare and biomedical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Evaluation of Language Models in the Medical Context Under Resource-Constrained Settings
Andrea Posada, Daniel Rueckert, Felix Meissen, Philip Muller
0
0
Since the emergence of the Transformer architecture, language model development has increased, driven by their promising potential. However, releasing these models into production requires properly understanding their behavior, particularly in sensitive domains such as medicine. Despite this need, the medical literature still lacks technical assessments of pre-trained language models, which are especially valuable in resource-constrained settings in terms of computational power or limited budget. To address this gap, we provide a comprehensive survey of language models in the medical domain. In addition, we selected a subset of these models for thorough evaluation, focusing on classification and text generation tasks. Our subset encompasses 53 models, ranging from 110 million to 13 billion parameters, spanning the three families of Transformer-based models and from diverse knowledge domains. This study employs a series of approaches for text classification together with zero-shot prompting instead of model training or fine-tuning, which closely resembles the limited resource setting in which many users of language models find themselves. Encouragingly, our findings reveal remarkable performance across various tasks and datasets, underscoring the latent potential of certain models to contain medical knowledge, even without domain specialization. Consequently, our study advocates for further exploration of model applications in medical contexts, particularly in resource-constrained settings. The code is available on https://github.com/anpoc/Language-models-in-medicine.
6/26/2024
Developing Healthcare Language Model Embedding Spaces
Niall Taylor, Dan Schofield, Andrey Kormilitzin, Dan W Joyce, Alejo Nevado-Holgado
0
0
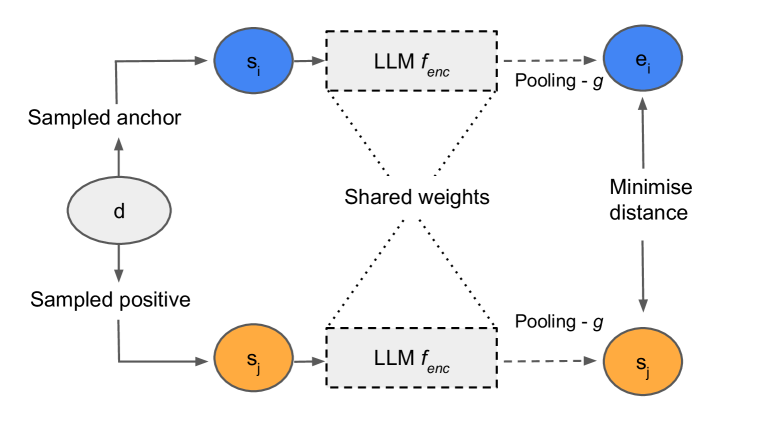
Pre-trained Large Language Models (LLMs) often struggle on out-of-domain datasets like healthcare focused text. We explore specialized pre-training to adapt smaller LLMs to different healthcare datasets. Three methods are assessed: traditional masked language modeling, Deep Contrastive Learning for Unsupervised Textual Representations (DeCLUTR), and a novel pre-training objective utilizing metadata categories from the healthcare settings. These schemes are evaluated on downstream document classification tasks for each dataset, with additional analysis of the resultant embedding spaces. Contrastively trained models outperform other approaches on the classification tasks, delivering strong performance from limited labeled data and with fewer model parameter updates required. While metadata-based pre-training does not further improve classifications across the datasets, it yields interesting embedding cluster separability. All domain adapted LLMs outperform their publicly available general base LLM, validating the importance of domain-specialization. This research illustrates efficient approaches to instill healthcare competency in compact LLMs even under tight computational budgets, an essential capability for responsible and sustainable deployment in local healthcare settings. We provide pre-training guidelines for specialized healthcare LLMs, motivate continued inquiry into contrastive objectives, and demonstrates adaptation techniques to align small LLMs with privacy-sensitive medical tasks.
4/1/2024

A Survey on Large Language Models from General Purpose to Medical Applications: Datasets, Methodologies, and Evaluations
Jinqiang Wang, Huansheng Ning, Yi Peng, Qikai Wei, Daniel Tesfai, Wenwei Mao, Tao Zhu, Runhe Huang
0
0
Large Language Models (LLMs) have demonstrated surprising performance across various natural language processing tasks. Recently, medical LLMs enhanced with domain-specific knowledge have exhibited excellent capabilities in medical consultation and diagnosis. These models can smoothly simulate doctor-patient dialogues and provide professional medical advice. Most medical LLMs are developed through continued training of open-source general LLMs, which require significantly fewer computational resources than training LLMs from scratch. Additionally, this approach offers better protection of patient privacy compared to API-based solutions. This survey systematically explores how to train medical LLMs based on general LLMs. It covers: (a) how to acquire training corpus and construct customized medical training sets, (b) how to choose a appropriate training paradigm, (c) how to choose a suitable evaluation benchmark, and (d) existing challenges and promising future research directions are discussed. This survey can provide guidance for the development of LLMs focused on various medical applications, such as medical education, diagnostic planning, and clinical assistants.
6/18/2024
📊
CamemBERT-bio: Leveraging Continual Pre-training for Cost-Effective Models on French Biomedical Data
Rian Touchent, Laurent Romary, Eric de la Clergerie
0
0
Clinical data in hospitals are increasingly accessible for research through clinical data warehouses. However these documents are unstructured and it is therefore necessary to extract information from medical reports to conduct clinical studies. Transfer learning with BERT-like models such as CamemBERT has allowed major advances for French, especially for named entity recognition. However, these models are trained for plain language and are less efficient on biomedical data. Addressing this gap, we introduce CamemBERT-bio, a dedicated French biomedical model derived from a new public French biomedical dataset. Through continual pre-training of the original CamemBERT, CamemBERT-bio achieves an improvement of 2.54 points of F1-score on average across various biomedical named entity recognition tasks, reinforcing the potential of continual pre-training as an equally proficient yet less computationally intensive alternative to training from scratch. Additionally, we highlight the importance of using a standard evaluation protocol that provides a clear view of the current state-of-the-art for French biomedical models.
4/4/2024