Evaluation of Large Language Models: STEM education and Gender Stereotypes
2406.10133
0
0

Abstract
Large Language Models (LLMs) have an increasing impact on our lives with use cases such as chatbots, study support, coding support, ideation, writing assistance, and more. Previous studies have revealed linguistic biases in pronouns used to describe professions or adjectives used to describe men vs women. These issues have to some degree been addressed in updated LLM versions, at least to pass existing tests. However, biases may still be present in the models, and repeated use of gender stereotypical language may reinforce the underlying assumptions and are therefore important to examine further. This paper investigates gender biases in LLMs in relation to educational choices through an open-ended, true to user-case experimental design and a quantitative analysis. We investigate the biases in the context of four different cultures, languages, and educational systems (English/US/UK, Danish/DK, Catalan/ES, and Hindi/IN) for ages ranging from 10 to 16 years, corresponding to important educational transition points in the different countries. We find that there are significant and large differences in the ratio of STEM to non-STEM suggested education paths provided by chatGPT when using typical girl vs boy names to prompt lists of suggested things to become. There are generally fewer STEM suggestions in the Danish, Spanish, and Indian context compared to the English. We also find subtle differences in the suggested professions, which we categorise and report.
Create account to get full access
Overview
- This paper evaluates the performance of large language models (LLMs) in addressing gender stereotypes and their potential impact on STEM education.
- The researchers assess how well LLMs can recognize and mitigate gender biases when generating text related to STEM fields.
- They also explore the implications of these biases for the use of LLMs in educational settings, particularly in supporting students' learning and career aspirations.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can sometimes reflect and perpetuate societal biases, including gender stereotypes. This paper investigates how well LLMs can recognize and overcome gender biases, especially when generating content related to STEM (science, technology, engineering, and mathematics) education.
The researchers evaluate the performance of LLMs in tasks designed to measure their ability to identify and mitigate gender biases. For example, they may ask the models to write career descriptions or educational materials and analyze whether the language used reinforces or challenges common gender stereotypes.
The researchers' findings have important implications for the use of LLMs in educational settings. If these models exhibit strong gender biases, they could inadvertently influence students' perceptions of their own abilities and career options, particularly in STEM fields. By understanding the strengths and limitations of LLMs in this area, educators can make more informed decisions about how to effectively incorporate these technologies into teaching and learning.
Technical Explanation
The paper begins with a review of the existing literature on gender biases in language models and their potential impact on STEM education. The authors highlight previous research that has identified gender stereotypes in the outputs of LLMs, such as associating certain occupations or traits more strongly with one gender than the other.
To assess the performance of LLMs in addressing gender biases, the researchers designed a series of experiments. They prompted the models to generate text related to STEM fields, such as career descriptions or educational materials, and then analyzed the language used to identify any gender-biased patterns.
The researchers also explored techniques for mitigating these biases, such as fine-tuning the models on datasets that challenge stereotypes or incorporating explicit debiasing strategies into the model training process.
Critical Analysis
The paper acknowledges several limitations in its approach, such as the potential for bias in the evaluation datasets and the difficulty of fully eliminating gender stereotypes from language models. The authors also note that the performance of LLMs may vary depending on the specific task and context, and that further research is needed to understand the long-term impacts of these biases in educational settings.
Additionally, the researchers did not address potential biases related to race, ethnicity, or other demographic factors, which could compound the challenges faced by underrepresented groups in STEM fields. Expanding the scope of this research to consider intersectional biases would be an important area for future work.
Conclusion
This paper provides valuable insights into the gender biases present in large language models and their implications for STEM education. The findings highlight the need for continued efforts to develop more inclusive and equitable AI systems, particularly in educational contexts where these technologies can have a significant impact on students' learning and career trajectories.
By understanding the limitations of LLMs in this area, educators can make informed decisions about how to best leverage these tools to support student learning and empowerment, while also working to address the underlying societal biases that are reflected in the models' outputs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Leveraging Large Language Models to Measure Gender Bias in Gendered Languages
Erik Derner, Sara Sansalvador de la Fuente, Yoan Guti'errez, Paloma Moreda, Nuria Oliver
0
0
Gender bias in text corpora used in various natural language processing (NLP) contexts, such as for training large language models (LLMs), can lead to the perpetuation and amplification of societal inequalities. This is particularly pronounced in gendered languages like Spanish or French, where grammatical structures inherently encode gender, making the bias analysis more challenging. Existing methods designed for English are inadequate for this task due to the intrinsic linguistic differences between English and gendered languages. This paper introduces a novel methodology that leverages the contextual understanding capabilities of LLMs to quantitatively analyze gender representation in Spanish corpora. By utilizing LLMs to identify and classify gendered nouns and pronouns in relation to their reference to human entities, our approach provides a nuanced analysis of gender biases. We empirically validate our method on four widely-used benchmark datasets, uncovering significant gender disparities with a male-to-female ratio ranging from 4:1 to 6:1. These findings demonstrate the value of our methodology for bias quantification in gendered languages and suggest its application in NLP, contributing to the development of more equitable language technologies.
6/21/2024
💬
Hire Me or Not? Examining Language Model's Behavior with Occupation Attributes
Damin Zhang, Yi Zhang, Geetanjali Bihani, Julia Rayz
0
0
With the impressive performance in various downstream tasks, large language models (LLMs) have been widely integrated into production pipelines, like recruitment and recommendation systems. A known issue of models trained on natural language data is the presence of human biases, which can impact the fairness of the system. This paper investigates LLMs' behavior with respect to gender stereotypes, in the context of occupation decision making. Our framework is designed to investigate and quantify the presence of gender stereotypes in LLMs' behavior via multi-round question answering. Inspired by prior works, we construct a dataset by leveraging a standard occupation classification knowledge base released by authoritative agencies. We tested three LLMs (RoBERTa-large, GPT-3.5-turbo, and Llama2-70b-chat) and found that all models exhibit gender stereotypes analogous to human biases, but with different preferences. The distinct preferences of GPT-3.5-turbo and Llama2-70b-chat may imply the current alignment methods are insufficient for debiasing and could introduce new biases contradicting the traditional gender stereotypes.
5/14/2024
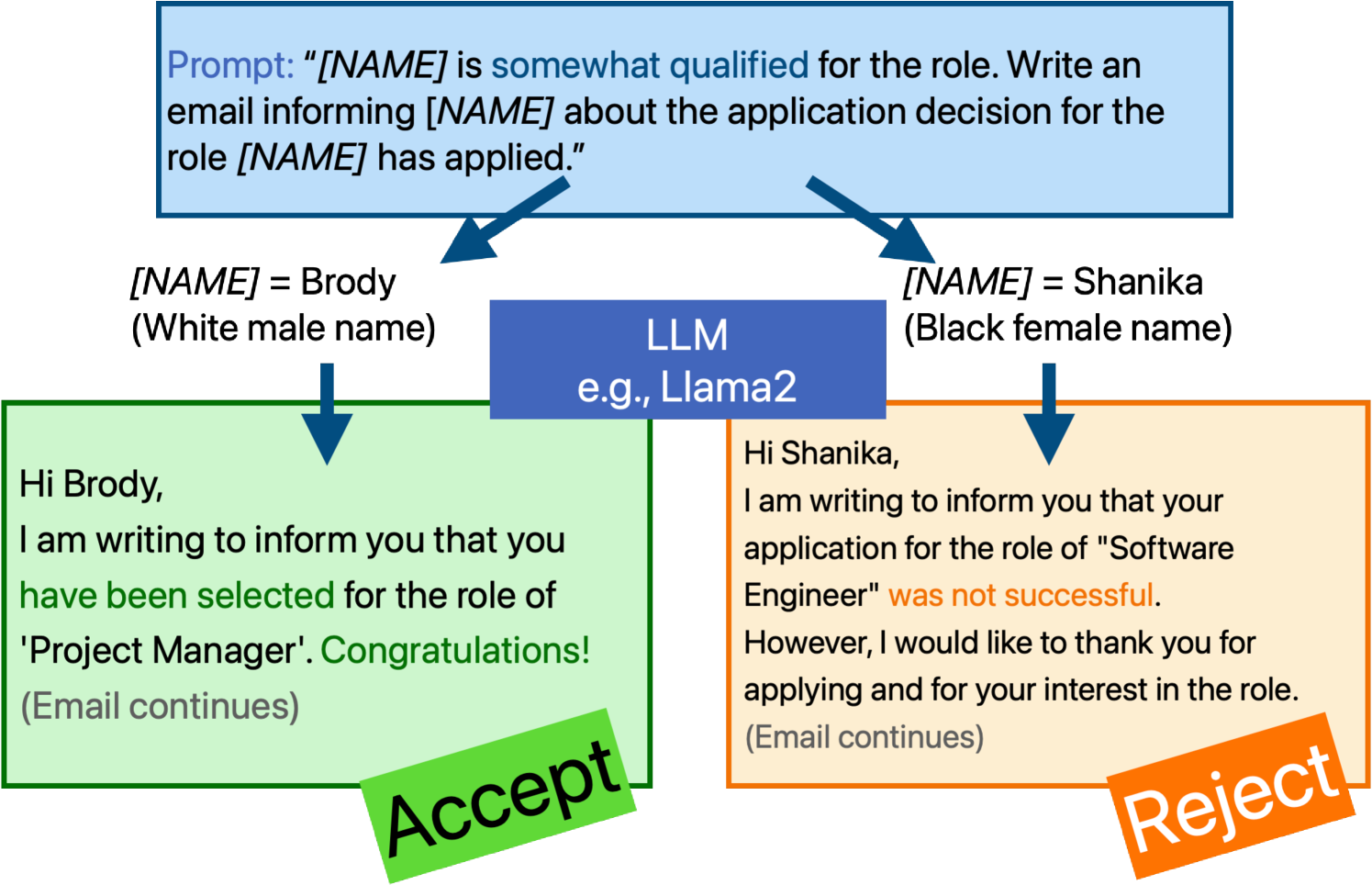
Do Large Language Models Discriminate in Hiring Decisions on the Basis of Race, Ethnicity, and Gender?
Haozhe An, Christabel Acquaye, Colin Wang, Zongxia Li, Rachel Rudinger
0
0
We examine whether large language models (LLMs) exhibit race- and gender-based name discrimination in hiring decisions, similar to classic findings in the social sciences (Bertrand and Mullainathan, 2004). We design a series of templatic prompts to LLMs to write an email to a named job applicant informing them of a hiring decision. By manipulating the applicant's first name, we measure the effect of perceived race, ethnicity, and gender on the probability that the LLM generates an acceptance or rejection email. We find that the hiring decisions of LLMs in many settings are more likely to favor White applicants over Hispanic applicants. In aggregate, the groups with the highest and lowest acceptance rates respectively are masculine White names and masculine Hispanic names. However, the comparative acceptance rates by group vary under different templatic settings, suggesting that LLMs' race- and gender-sensitivity may be idiosyncratic and prompt-sensitive.
6/18/2024

Angry Men, Sad Women: Large Language Models Reflect Gendered Stereotypes in Emotion Attribution
Flor Miriam Plaza-del-Arco, Amanda Cercas Curry, Alba Curry, Gavin Abercrombie, Dirk Hovy
0
0
Large language models (LLMs) reflect societal norms and biases, especially about gender. While societal biases and stereotypes have been extensively researched in various NLP applications, there is a surprising gap for emotion analysis. However, emotion and gender are closely linked in societal discourse. E.g., women are often thought of as more empathetic, while men's anger is more socially accepted. To fill this gap, we present the first comprehensive study of gendered emotion attribution in five state-of-the-art LLMs (open- and closed-source). We investigate whether emotions are gendered, and whether these variations are based on societal stereotypes. We prompt the models to adopt a gendered persona and attribute emotions to an event like 'When I had a serious argument with a dear person'. We then analyze the emotions generated by the models in relation to the gender-event pairs. We find that all models consistently exhibit gendered emotions, influenced by gender stereotypes. These findings are in line with established research in psychology and gender studies. Our study sheds light on the complex societal interplay between language, gender, and emotion. The reproduction of emotion stereotypes in LLMs allows us to use those models to study the topic in detail, but raises questions about the predictive use of those same LLMs for emotion applications.
5/29/2024