Leveraging Large Language Models to Measure Gender Bias in Gendered Languages
2406.13677
0
0

Abstract
Gender bias in text corpora used in various natural language processing (NLP) contexts, such as for training large language models (LLMs), can lead to the perpetuation and amplification of societal inequalities. This is particularly pronounced in gendered languages like Spanish or French, where grammatical structures inherently encode gender, making the bias analysis more challenging. Existing methods designed for English are inadequate for this task due to the intrinsic linguistic differences between English and gendered languages. This paper introduces a novel methodology that leverages the contextual understanding capabilities of LLMs to quantitatively analyze gender representation in Spanish corpora. By utilizing LLMs to identify and classify gendered nouns and pronouns in relation to their reference to human entities, our approach provides a nuanced analysis of gender biases. We empirically validate our method on four widely-used benchmark datasets, uncovering significant gender disparities with a male-to-female ratio ranging from 4:1 to 6:1. These findings demonstrate the value of our methodology for bias quantification in gendered languages and suggest its application in NLP, contributing to the development of more equitable language technologies.
Create account to get full access
Overview
- This paper explores how large language models (LLMs) can be leveraged to measure gender bias in gendered languages.
- The researchers investigate bias in the use of masculine and feminine forms of words in several languages, including Spanish, French, and German.
- They use LLMs to generate text and analyze the frequency of masculine and feminine forms to quantify gender bias.
- The findings provide insights into how LLMs may perpetuate or amplify existing societal gender biases, which is an important consideration as these models become more widely adopted.
Plain English Explanation
The paper looks at how powerful AI language models, known as large language models (LLMs), can be used to measure gender bias in languages that have grammatical gender (like Spanish, French, and German). In these languages, many words come in both masculine and feminine forms.
The researchers used LLMs to generate text in these languages and then analyzed how often the models used the masculine versus feminine forms of words. This allowed them to quantify the gender biases present in the language models. Evaluating Gender Bias in Pre-Trained Language Models
For example, if an LLM consistently used the masculine form of a word when both masculine and feminine forms were possible, that would suggest the model has learned and perpetuates a masculine bias from the data it was trained on. Investigating Gender Bias in Turkish Language Models
This is an important issue as LLMs become more widely used, since they could end up amplifying existing societal biases if not carefully designed. The findings from this research can help us understand where these biases exist and work to address them. What is Your Favorite Gender: MLM Gender
Technical Explanation
The paper describes a method for leveraging large language models (LLMs) to measure gender bias in gendered languages. The researchers focused on three languages - Spanish, French, and German - which have grammatical gender systems where many nouns, adjectives, and pronouns come in both masculine and feminine forms.
They used several state-of-the-art LLMs, including GPT-2 and GPT-3, to generate text in these languages and then analyzed the frequency with which the models used the masculine versus feminine forms. This allowed them to quantify the degree of gender bias present in the language models. Investigating Markers and Drivers of Gender Bias in Machine Translations
The researchers found that the LLMs exhibited significant gender biases, often defaulting to masculine forms even when both masculine and feminine options were grammatically valid. This bias was particularly pronounced for role nouns (e.g. "doctor", "engineer") and occupations. Evaluation of Large Language Models for STEM Education and Gender
The paper provides important insights into how these powerful language models may perpetuate or amplify existing societal biases around gender. As LLMs become more widely used in applications like language generation, translation, and text analysis, understanding and addressing these biases will be a critical challenge.
Critical Analysis
The paper provides a robust methodology for measuring gender bias in LLMs operating on gendered languages. However, it is important to note that the research is limited to just three languages - Spanish, French, and German. It would be valuable to expand the analysis to a wider range of gendered languages to see if similar patterns emerge.
Additionally, the paper does not delve deeply into the underlying causes of the observed gender biases. While the researchers hypothesize that the biases stem from the training data used to build the LLMs, further investigation is needed to fully understand the drivers of these biases. Investigating Gender Bias in Turkish Language Models
Another potential limitation is that the analysis focuses solely on the frequency of masculine versus feminine forms, without considering the semantic or contextual meaning of the words. It is possible that the gender biases manifest in more nuanced ways that are not captured by this approach.
Overall, this research represents an important step forward in understanding and quantifying gender bias in powerful language models. However, continued work is needed to fully address this challenge as LLMs become more pervasive in our daily lives. What is Your Favorite Gender: MLM Gender
Conclusion
This paper demonstrates how large language models can be leveraged to measure gender bias in gendered languages. The findings reveal significant biases in the use of masculine versus feminine word forms, which has important implications as these models become more widely adopted.
The research provides a valuable framework for quantifying gender bias in language models and highlights the need to carefully consider and address these biases as AI systems become increasingly prominent in areas like language generation, translation, and text analysis. Addressing these biases will be crucial to ensure that AI systems are fair, inclusive, and equitable for all users. Evaluating Gender Bias in Pre-Trained Language Models
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Evaluation of Large Language Models: STEM education and Gender Stereotypes
Smilla Due, Sneha Das, Marianne Andersen, Berta Plandolit L'opez, Sniff Andersen Nex{o}, Line Clemmensen
0
0
Large Language Models (LLMs) have an increasing impact on our lives with use cases such as chatbots, study support, coding support, ideation, writing assistance, and more. Previous studies have revealed linguistic biases in pronouns used to describe professions or adjectives used to describe men vs women. These issues have to some degree been addressed in updated LLM versions, at least to pass existing tests. However, biases may still be present in the models, and repeated use of gender stereotypical language may reinforce the underlying assumptions and are therefore important to examine further. This paper investigates gender biases in LLMs in relation to educational choices through an open-ended, true to user-case experimental design and a quantitative analysis. We investigate the biases in the context of four different cultures, languages, and educational systems (English/US/UK, Danish/DK, Catalan/ES, and Hindi/IN) for ages ranging from 10 to 16 years, corresponding to important educational transition points in the different countries. We find that there are significant and large differences in the ratio of STEM to non-STEM suggested education paths provided by chatGPT when using typical girl vs boy names to prompt lists of suggested things to become. There are generally fewer STEM suggestions in the Danish, Spanish, and Indian context compared to the English. We also find subtle differences in the suggested professions, which we categorise and report.
6/17/2024
Investigating Gender Bias in Turkish Language Models
Orhun Caglidil, Malte Ostendorff, Georg Rehm
0
0
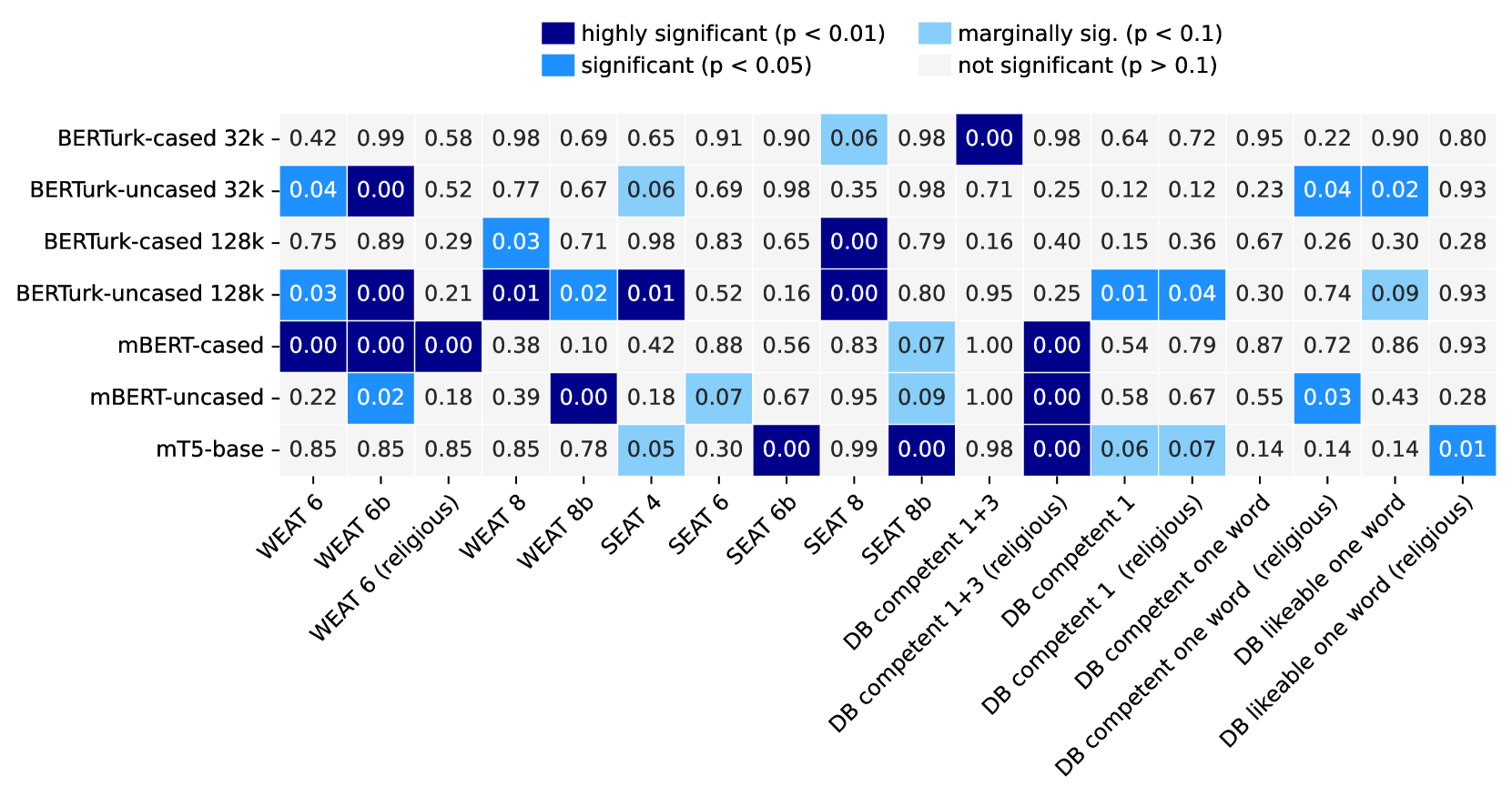
Language models are trained mostly on Web data, which often contains social stereotypes and biases that the models can inherit. This has potentially negative consequences, as models can amplify these biases in downstream tasks or applications. However, prior research has primarily focused on the English language, especially in the context of gender bias. In particular, grammatically gender-neutral languages such as Turkish are underexplored despite representing different linguistic properties to language models with possibly different effects on biases. In this paper, we fill this research gap and investigate the significance of gender bias in Turkish language models. We build upon existing bias evaluation frameworks and extend them to the Turkish language by translating existing English tests and creating new ones designed to measure gender bias in the context of Turkiye. Specifically, we also evaluate Turkish language models for their embedded ethnic bias toward Kurdish people. Based on the experimental results, we attribute possible biases to different model characteristics such as the model size, their multilingualism, and the training corpora. We make the Turkish gender bias dataset publicly available.
4/19/2024
What is Your Favorite Gender, MLM? Gender Bias Evaluation in Multilingual Masked Language Models
Jeongrok Yu, Seong Ug Kim, Jacob Choi, Jinho D. Choi
0
0
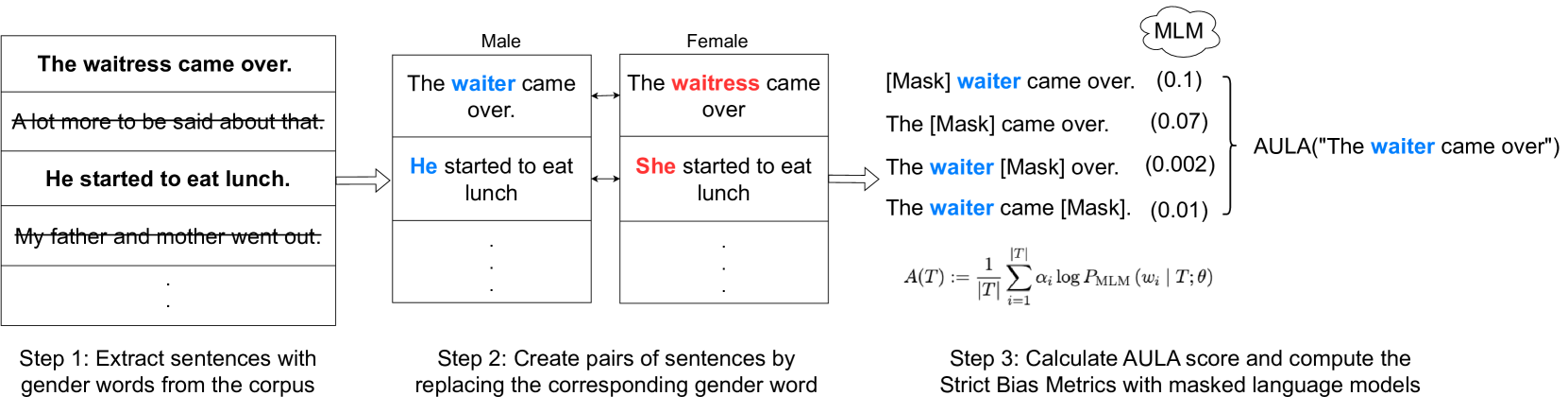
Bias is a disproportionate prejudice in favor of one side against another. Due to the success of transformer-based Masked Language Models (MLMs) and their impact on many NLP tasks, a systematic evaluation of bias in these models is needed more than ever. While many studies have evaluated gender bias in English MLMs, only a few works have been conducted for the task in other languages. This paper proposes a multilingual approach to estimate gender bias in MLMs from 5 languages: Chinese, English, German, Portuguese, and Spanish. Unlike previous work, our approach does not depend on parallel corpora coupled with English to detect gender bias in other languages using multilingual lexicons. Moreover, a novel model-based method is presented to generate sentence pairs for a more robust analysis of gender bias, compared to the traditional lexicon-based method. For each language, both the lexicon-based and model-based methods are applied to create two datasets respectively, which are used to evaluate gender bias in an MLM specifically trained for that language using one existing and 3 new scoring metrics. Our results show that the previous approach is data-sensitive and not stable as it does not remove contextual dependencies irrelevant to gender. In fact, the results often flip when different scoring metrics are used on the same dataset, suggesting that gender bias should be studied on a large dataset using multiple evaluation metrics for best practice.
4/11/2024
Investigating Markers and Drivers of Gender Bias in Machine Translations
Peter J Barclay (Edinburgh Napier University), Ashkan Sami (Edinburgh Napier University)
0
0
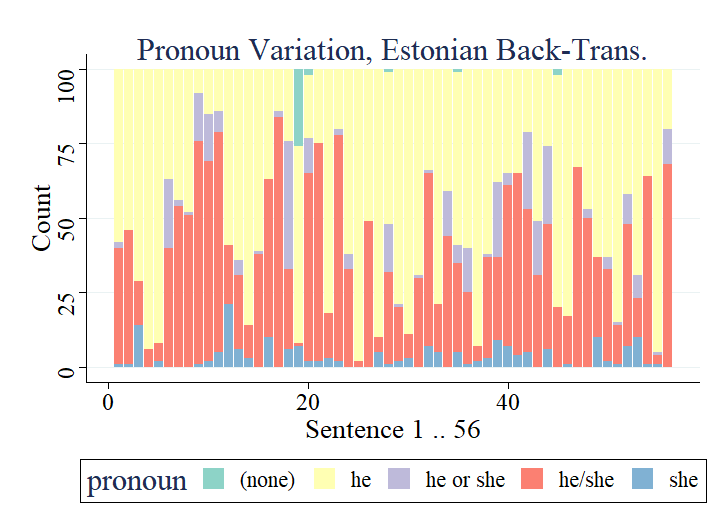
Implicit gender bias in Large Language Models (LLMs) is a well-documented problem, and implications of gender introduced into automatic translations can perpetuate real-world biases. However, some LLMs use heuristics or post-processing to mask such bias, making investigation difficult. Here, we examine bias in LLMss via back-translation, using the DeepL translation API to investigate the bias evinced when repeatedly translating a set of 56 Software Engineering tasks used in a previous study. Each statement starts with 'she', and is translated first into a 'genderless' intermediate language then back into English; we then examine pronoun-choice in the back-translated texts. We expand prior research in the following ways: (1) by comparing results across five intermediate languages, namely Finnish, Indonesian, Estonian, Turkish and Hungarian; (2) by proposing a novel metric for assessing the variation in gender implied in the repeated translations, avoiding the over-interpretation of individual pronouns, apparent in earlier work; (3) by investigating sentence features that drive bias; (4) and by comparing results from three time-lapsed datasets to establish the reproducibility of the approach. We found that some languages display similar patterns of pronoun use, falling into three loose groups, but that patterns vary between groups; this underlines the need to work with multiple languages. We also identify the main verb appearing in a sentence as a likely significant driver of implied gender in the translations. Moreover, we see a good level of replicability in the results, and establish that our variation metric proves robust despite an obvious change in the behaviour of the DeepL translation API during the course of the study. These results show that the back-translation method can provide further insights into bias in language models.
4/3/2024