EVCL: Elastic Variational Continual Learning with Weight Consolidation
2406.15972
0
0

Abstract
Continual learning aims to allow models to learn new tasks without forgetting what has been learned before. This work introduces Elastic Variational Continual Learning with Weight Consolidation (EVCL), a novel hybrid model that integrates the variational posterior approximation mechanism of Variational Continual Learning (VCL) with the regularization-based parameter-protection strategy of Elastic Weight Consolidation (EWC). By combining the strengths of both methods, EVCL effectively mitigates catastrophic forgetting and enables better capture of dependencies between model parameters and task-specific data. Evaluated on five discriminative tasks, EVCL consistently outperforms existing baselines in both domain-incremental and task-incremental learning scenarios for deep discriminative models.
Create account to get full access
Overview
- This paper introduces a new continual learning method called Elastic Variational Continual Learning (EVCL) that consolidates important weights to prevent catastrophic forgetting.
- EVCL uses a Bayesian neural network approach to learn a distribution over the network's weights, allowing it to maintain uncertainty about past tasks and adapt to new ones.
- The method incorporates a weight consolidation mechanism that selectively freezes important weights to protect knowledge from previous tasks.
Plain English Explanation
Continual learning is the ability for an AI system to learn new tasks or information over time, without forgetting what it has learned previously. This is a challenging problem, as neural networks tend to "catastrophically forget" old information when learning new things.
The EVCL method introduces a new approach to continual learning that uses a Bayesian perspective. Instead of just storing a single set of network weights, EVCL learns a distribution over the possible weights. This allows the system to maintain uncertainty about past tasks, and adapt more flexibly to new information.
Additionally, EVCL incorporates a weight consolidation mechanism that identifies and "freezes" the most important weights from previous tasks. This helps protect the knowledge gained from earlier learning, preventing catastrophic forgetting.
By combining these Bayesian and weight consolidation techniques, EVCL is able to learn new tasks effectively while also retaining knowledge from the past. This is an important advancement in the field of continual learning, which aims to create AI systems that can continuously expand their capabilities over time, like humans do.
Technical Explanation
The EVCL method builds on the concept of Bayesian neural networks, which represent the network's weights as probability distributions rather than single values. This allows the model to maintain uncertainty about past knowledge and adapt more flexibly to new tasks.
To prevent catastrophic forgetting, EVCL incorporates a weight consolidation mechanism that identifies and selectively freezes the most important weights from previous tasks. This is done by estimating the importance of each weight based on its contribution to the model's performance on past tasks.
The full EVCL training process involves:
- Learning a Bayesian neural network for the current task
- Estimating the importance of each weight based on its contribution to past tasks
- Consolidating the important weights by constraining them during training on the new task
This approach allows EVCL to continuously learn new tasks while also retaining relevant knowledge from the past, as demonstrated through experiments on benchmark continual learning datasets.
Critical Analysis
The EVCL method represents an interesting and promising approach to the continual learning problem. By incorporating Bayesian principles and selective weight consolidation, it addresses some of the key challenges in this domain, such as catastrophic forgetting and the inability to adapt flexibly to new tasks.
However, the paper also acknowledges several limitations and areas for future work. For example, the weight consolidation mechanism may not be optimal for all types of tasks or network architectures, and further research is needed to understand its performance in more complex real-world scenarios.
Additionally, the Bayesian neural network approach used in EVCL can be computationally expensive, which may limit its practicality for large-scale applications. Exploring more efficient Bayesian inference techniques or alternative architectural designs could help address this challenge.
Overall, the EVCL method represents an important step forward in the field of continual learning, and the ideas presented in the paper warrant further investigation and refinement. As the development of continually learning AI systems continues, research like this will be crucial in overcoming the limitations of current approaches and enabling more flexible and adaptable AI capabilities.
Conclusion
The EVCL method introduced in this paper offers a novel approach to the challenge of continual learning, combining Bayesian neural networks and selective weight consolidation to prevent catastrophic forgetting. By maintaining uncertainty about past knowledge and selectively preserving important weights, EVCL demonstrates the potential to enable AI systems that can continuously expand their capabilities over time.
While the approach has some limitations that require further research, the ideas presented in this paper represent an important advancement in the field of continual learning. As AI systems become more ubiquitous and integral to our daily lives, the ability to learn and adapt continuously will be increasingly crucial. The EVCL method and similar continual learning techniques offer promising paths forward in realizing this goal and unlocking the full potential of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
Elastic Feature Consolidation for Cold Start Exemplar-Free Incremental Learning
Simone Magistri, Tomaso Trinci, Albin Soutif-Cormerais, Joost van de Weijer, Andrew D. Bagdanov
0
0
Exemplar-Free Class Incremental Learning (EFCIL) aims to learn from a sequence of tasks without having access to previous task data. In this paper, we consider the challenging Cold Start scenario in which insufficient data is available in the first task to learn a high-quality backbone. This is especially challenging for EFCIL since it requires high plasticity, which results in feature drift which is difficult to compensate for in the exemplar-free setting. To address this problem, we propose a simple and effective approach that consolidates feature representations by regularizing drift in directions highly relevant to previous tasks and employs prototypes to reduce task-recency bias. Our method, called Elastic Feature Consolidation (EFC), exploits a tractable second-order approximation of feature drift based on an Empirical Feature Matrix (EFM). The EFM induces a pseudo-metric in feature space which we use to regularize feature drift in important directions and to update Gaussian prototypes used in a novel asymmetric cross entropy loss which effectively balances prototype rehearsal with data from new tasks. Experimental results on CIFAR-100, Tiny-ImageNet, ImageNet-Subset and ImageNet-1K demonstrate that Elastic Feature Consolidation is better able to learn new tasks by maintaining model plasticity and significantly outperform the state-of-the-art.
5/31/2024

Continual Learning with Weight Interpolation
Jk{e}drzej Kozal, Jan Wasilewski, Bartosz Krawczyk, Micha{l} Wo'zniak
0
0
Continual learning poses a fundamental challenge for modern machine learning systems, requiring models to adapt to new tasks while retaining knowledge from previous ones. Addressing this challenge necessitates the development of efficient algorithms capable of learning from data streams and accumulating knowledge over time. This paper proposes a novel approach to continual learning utilizing the weight consolidation method. Our method, a simple yet powerful technique, enhances robustness against catastrophic forgetting by interpolating between old and new model weights after each novel task, effectively merging two models to facilitate exploration of local minima emerging after arrival of new concepts. Moreover, we demonstrate that our approach can complement existing rehearsal-based replay approaches, improving their accuracy and further mitigating the forgetting phenomenon. Additionally, our method provides an intuitive mechanism for controlling the stability-plasticity trade-off. Experimental results showcase the significant performance enhancement to state-of-the-art experience replay algorithms the proposed weight consolidation approach offers. Our algorithm can be downloaded from https://github.com/jedrzejkozal/weight-interpolation-cl.
4/10/2024
Improving Data-aware and Parameter-aware Robustness for Continual Learning
Hanxi Xiao, Fan Lyu
0
0
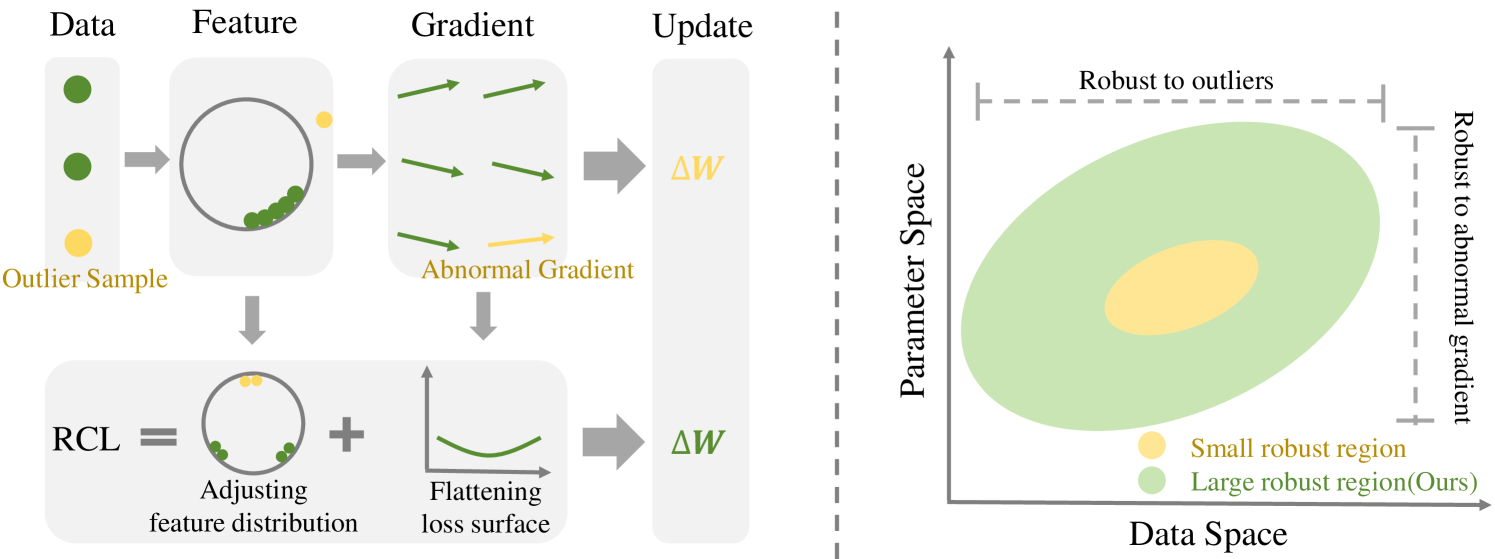
The goal of Continual Learning (CL) task is to continuously learn multiple new tasks sequentially while achieving a balance between the plasticity and stability of new and old knowledge. This paper analyzes that this insufficiency arises from the ineffective handling of outliers, leading to abnormal gradients and unexpected model updates. To address this issue, we enhance the data-aware and parameter-aware robustness of CL, proposing a Robust Continual Learning (RCL) method. From the data perspective, we develop a contrastive loss based on the concepts of uniformity and alignment, forming a feature distribution that is more applicable to outliers. From the parameter perspective, we present a forward strategy for worst-case perturbation and apply robust gradient projection to the parameters. The experimental results on three benchmarks show that the proposed method effectively maintains robustness and achieves new state-of-the-art (SOTA) results. The code is available at: https://github.com/HanxiXiao/RCL
5/28/2024
Realistic Continual Learning Approach using Pre-trained Models
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
0
0
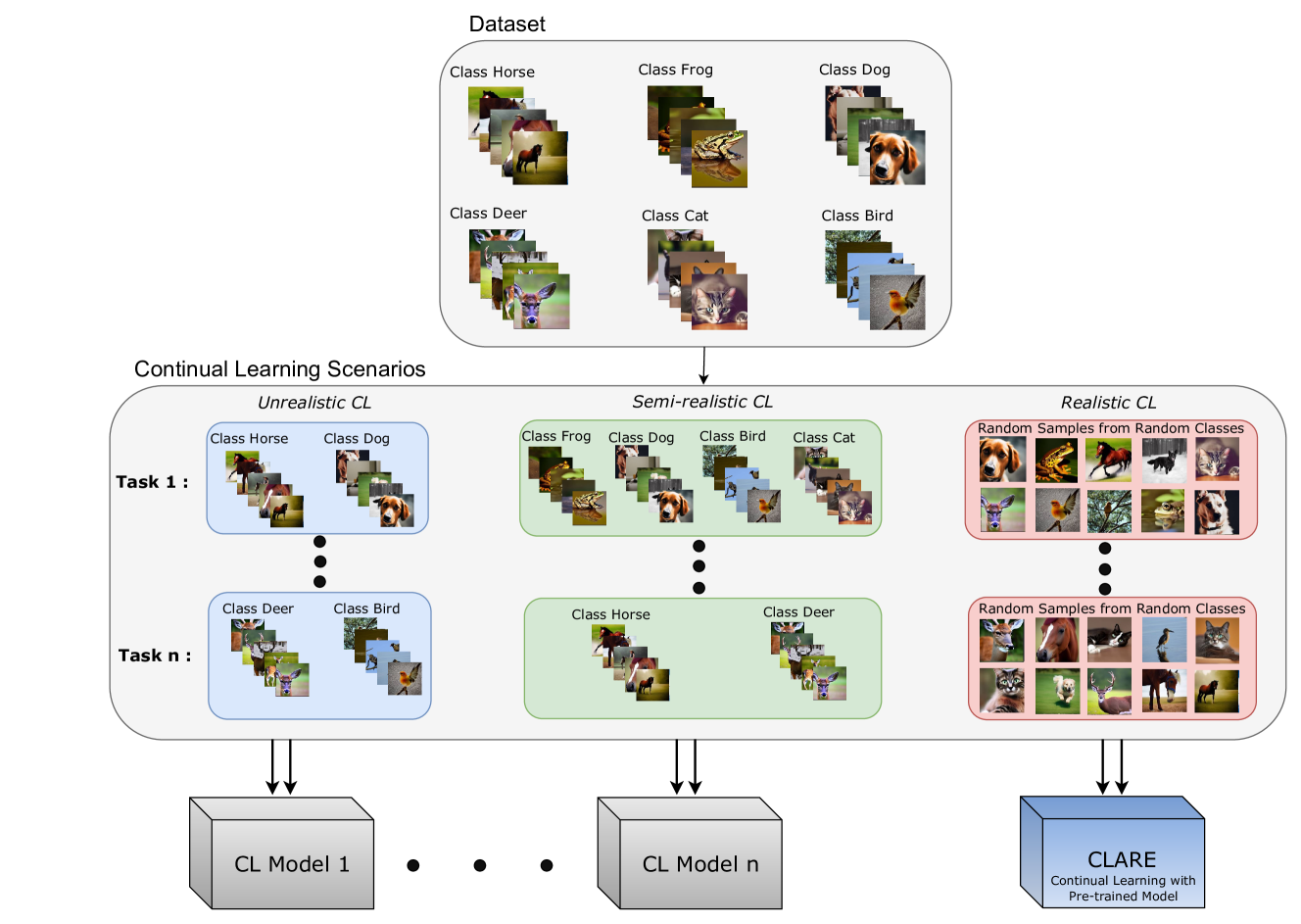
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
4/12/2024