Improving Data-aware and Parameter-aware Robustness for Continual Learning
2405.17054
0
0
Abstract
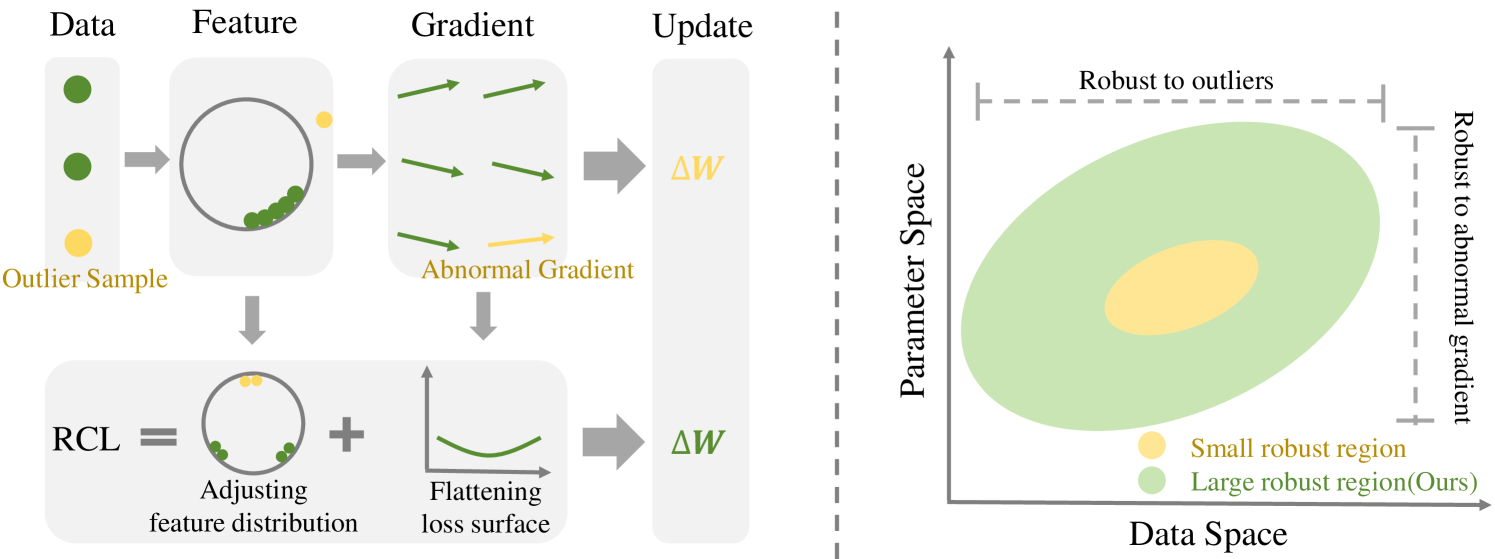
The goal of Continual Learning (CL) task is to continuously learn multiple new tasks sequentially while achieving a balance between the plasticity and stability of new and old knowledge. This paper analyzes that this insufficiency arises from the ineffective handling of outliers, leading to abnormal gradients and unexpected model updates. To address this issue, we enhance the data-aware and parameter-aware robustness of CL, proposing a Robust Continual Learning (RCL) method. From the data perspective, we develop a contrastive loss based on the concepts of uniformity and alignment, forming a feature distribution that is more applicable to outliers. From the parameter perspective, we present a forward strategy for worst-case perturbation and apply robust gradient projection to the parameters. The experimental results on three benchmarks show that the proposed method effectively maintains robustness and achieves new state-of-the-art (SOTA) results. The code is available at: https://github.com/HanxiXiao/RCL
Create account to get full access
Overview
- This research paper focuses on improving the robustness of continual learning models, which are machine learning models that can learn and adapt to new tasks over time without forgetting previous knowledge.
- The authors propose two key improvements: data-aware robustness and parameter-aware robustness.
- Data-aware robustness helps the model become more resilient to changes in the input data distribution over time.
- Parameter-aware robustness helps the model become more robust to changes in the model's own parameters as it learns new tasks.
Plain English Explanation
Continual learning is a type of machine learning where a model is trained to learn and adapt to new tasks over time, without forgetting what it has learned before. This is an important capability, as real-world applications often require models to keep learning and improving as new data becomes available.
However, continual learning models can face challenges when the input data or the model's own internal structure changes over time. This paper introduces techniques to make continual learning models more "robust" - in other words, better able to handle these changes without their performance deteriorating.
The first key idea is "data-aware robustness". This helps the model adapt when the distribution of the input data changes over time, such as when the model is asked to work with new types of images or text. The model learns to be more flexible and generalize better to new data.
The second key idea is "parameter-aware robustness". This helps the model adapt when its own internal structure (the values of the parameters in its neural network) changes over time as it learns new tasks. This makes the model more stable and able to retain its previous knowledge.
By incorporating these data-aware and parameter-aware techniques, the researchers were able to create continual learning models that are more robust and effective at adapting to changes over time. This is an important step forward in making continual learning systems more practical and useful in real-world applications.
Technical Explanation
The key technical innovations introduced in this paper are "data-aware robustness" and "parameter-aware robustness" for continual learning models.
Data-aware robustness helps the model become more resilient to changes in the input data distribution over time. The authors achieve this by explicitly modeling the data distribution shift and incorporating this information into the model's objective function. This allows the model to better calibrate its predictions and generalize to new data.
Parameter-aware robustness helps the model become more robust to changes in its own internal parameters as it learns new tasks. The authors achieve this by adding a regularization term that encourages the model to learn parameters that are less sensitive to change. This helps the model maintain its previous knowledge and avoid catastrophic forgetting.
The authors evaluate their approaches on several standard continual learning benchmarks and show significant improvements in performance compared to previous methods. The techniques introduced in this paper represent an important step forward in making continual learning systems more robust and practically useful.
Critical Analysis
The authors demonstrate the effectiveness of their data-aware and parameter-aware robustness techniques through extensive experiments on standard benchmarks. However, the paper does not address potential limitations or caveats of their approach.
For example, the authors do not discuss how their methods would scale to more complex or open-ended continual learning scenarios, where the model might need to adapt to a much wider range of data and task distributions over time. Further research would be needed to understand the broader applicability and limitations of this approach.
Additionally, the paper does not explore the computational or memory overhead introduced by the additional robustness components. In real-world deployments, these practical considerations could be important factors in determining the feasibility and cost-effectiveness of the proposed techniques.
Overall, the authors present a promising step forward in improving the robustness of continual learning models, but more research is needed to fully understand the strengths, weaknesses, and broader implications of their approach.
Conclusion
This research paper introduces two key innovations - data-aware robustness and parameter-aware robustness - to improve the performance and reliability of continual learning models. By explicitly accounting for changes in the input data distribution and the model's own internal parameters, the authors were able to create more robust continual learning systems.
These techniques represent an important advancement in the field of continual learning, which is essential for developing machine learning systems that can adapt and learn over time, rather than being limited to static, pre-defined tasks. As the researchers demonstrate, these robustness improvements can lead to significant performance gains on standard benchmarks.
While further research is needed to fully understand the broader applicability and limitations of this approach, the ideas presented in this paper are a valuable contribution to the ongoing efforts to make continual learning systems more practical and effective for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Realistic Continual Learning Approach using Pre-trained Models
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
0
0
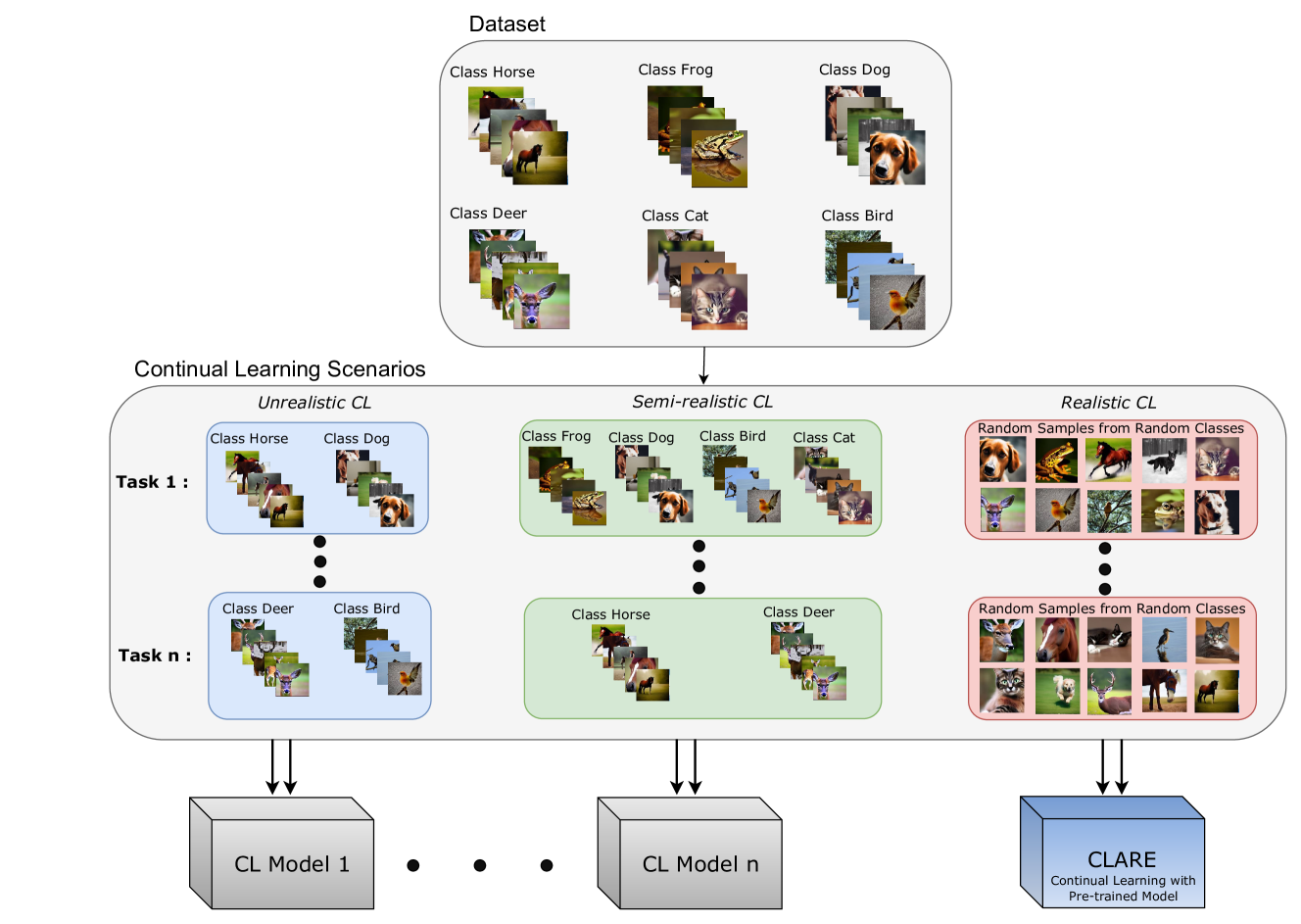
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
4/12/2024
✨
Fixed Design Analysis of Regularization-Based Continual Learning
Haoran Li, Jingfeng Wu, Vladimir Braverman
0
0
We consider a continual learning (CL) problem with two linear regression tasks in the fixed design setting, where the feature vectors are assumed fixed and the labels are assumed to be random variables. We consider an $ell_2$-regularized CL algorithm, which computes an Ordinary Least Squares parameter to fit the first dataset, then computes another parameter that fits the second dataset under an $ell_2$-regularization penalizing its deviation from the first parameter, and outputs the second parameter. For this algorithm, we provide tight bounds on the average risk over the two tasks. Our risk bounds reveal a provable trade-off between forgetting and intransigence of the $ell_2$-regularized CL algorithm: with a large regularization parameter, the algorithm output forgets less information about the first task but is intransigent to extract new information from the second task; and vice versa. Our results suggest that catastrophic forgetting could happen for CL with dissimilar tasks (under a precise similarity measurement) and that a well-tuned $ell_2$-regularization can partially mitigate this issue by introducing intransigence.
6/19/2024
Calibration of Continual Learning Models
Lanpei Li, Elia Piccoli, Andrea Cossu, Davide Bacciu, Vincenzo Lomonaco
0
0
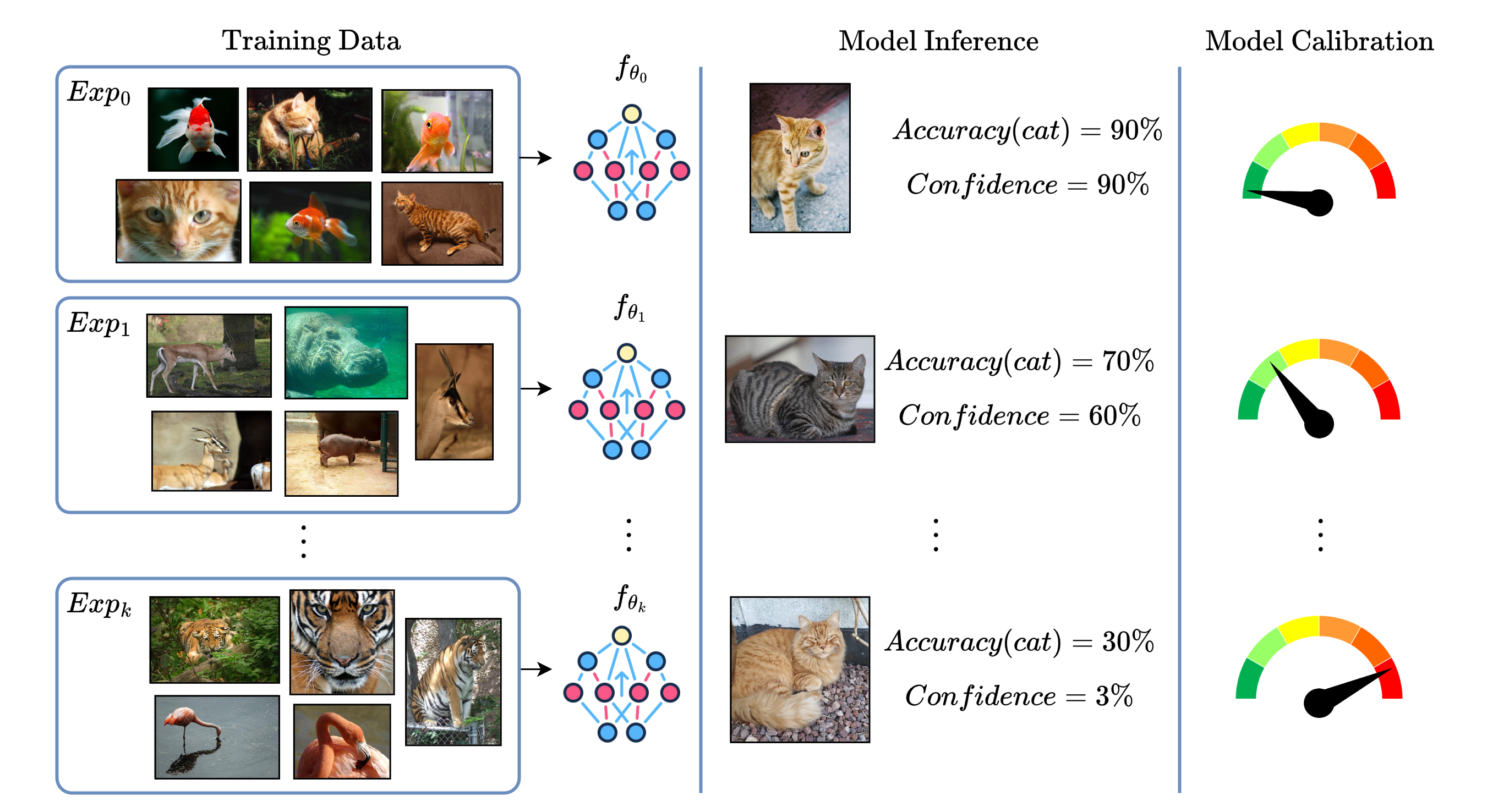
Continual Learning (CL) focuses on maximizing the predictive performance of a model across a non-stationary stream of data. Unfortunately, CL models tend to forget previous knowledge, thus often underperforming when compared with an offline model trained jointly on the entire data stream. Given that any CL model will eventually make mistakes, it is of crucial importance to build calibrated CL models: models that can reliably tell their confidence when making a prediction. Model calibration is an active research topic in machine learning, yet to be properly investigated in CL. We provide the first empirical study of the behavior of calibration approaches in CL, showing that CL strategies do not inherently learn calibrated models. To mitigate this issue, we design a continual calibration approach that improves the performance of post-processing calibration methods over a wide range of different benchmarks and CL strategies. CL does not necessarily need perfect predictive models, but rather it can benefit from reliable predictive models. We believe our study on continual calibration represents a first step towards this direction.
4/15/2024

Provable Contrastive Continual Learning
Yichen Wen, Zhiquan Tan, Kaipeng Zheng, Chuanlong Xie, Weiran Huang
0
0
Continual learning requires learning incremental tasks with dynamic data distributions. So far, it has been observed that employing a combination of contrastive loss and distillation loss for training in continual learning yields strong performance. To the best of our knowledge, however, this contrastive continual learning framework lacks convincing theoretical explanations. In this work, we fill this gap by establishing theoretical performance guarantees, which reveal how the performance of the model is bounded by training losses of previous tasks in the contrastive continual learning framework. Our theoretical explanations further support the idea that pre-training can benefit continual learning. Inspired by our theoretical analysis of these guarantees, we propose a novel contrastive continual learning algorithm called CILA, which uses adaptive distillation coefficients for different tasks. These distillation coefficients are easily computed by the ratio between average distillation losses and average contrastive losses from previous tasks. Our method shows great improvement on standard benchmarks and achieves new state-of-the-art performance.
5/30/2024