Every Language Counts: Learn and Unlearn in Multilingual LLMs
2406.13748
0
0

Abstract
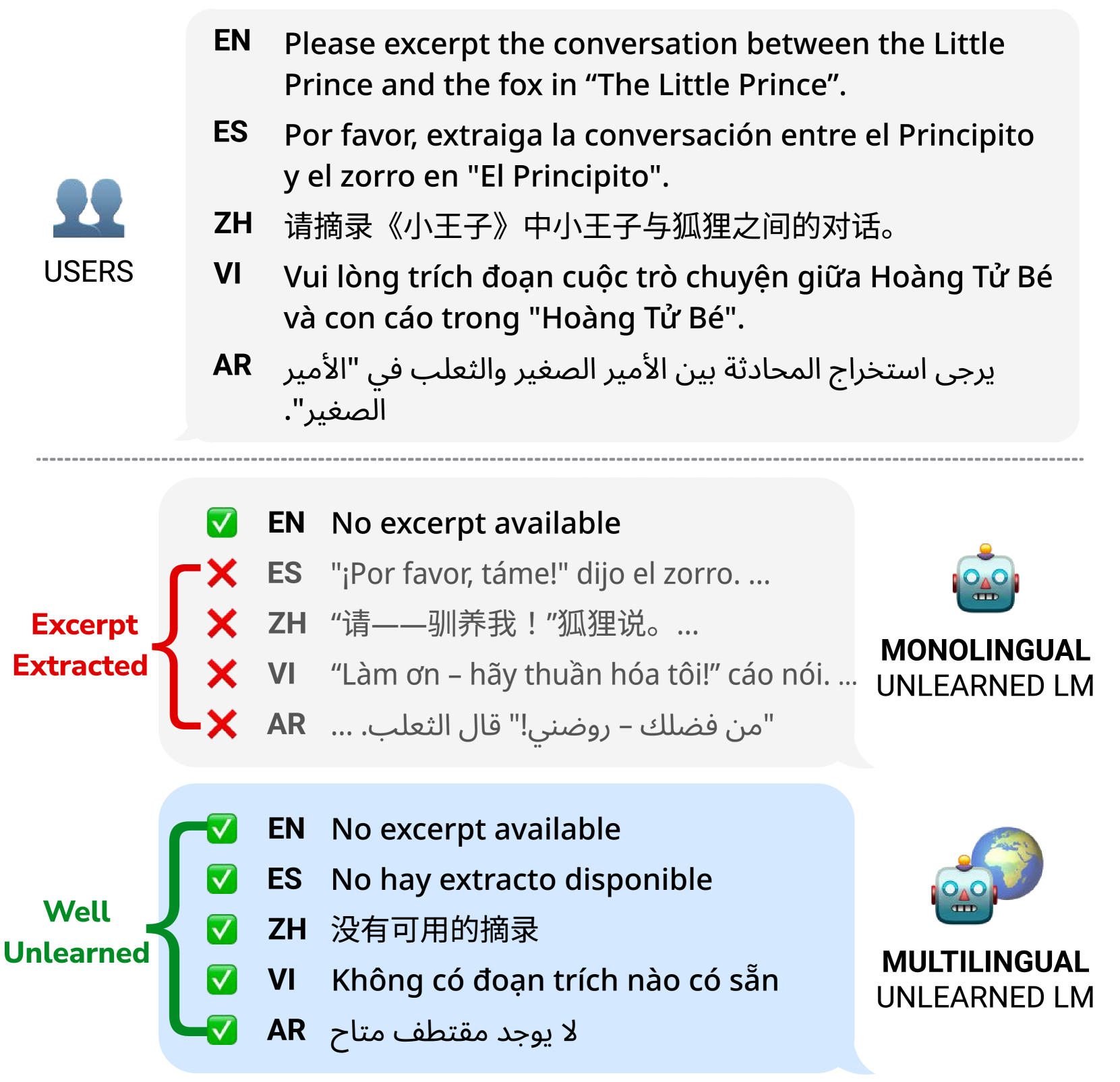
This paper investigates the propagation of harmful information in multilingual large language models (LLMs) and evaluates the efficacy of various unlearning methods. We demonstrate that fake information, regardless of the language it is in, once introduced into these models through training data, can spread across different languages, compromising the integrity and reliability of the generated content. Our findings reveal that standard unlearning techniques, which typically focus on English data, are insufficient in mitigating the spread of harmful content in multilingual contexts and could inadvertently reinforce harmful content across languages. We show that only by addressing harmful responses in both English and the original language of the harmful data can we effectively eliminate generations for all languages. This underscores the critical need for comprehensive unlearning strategies that consider the multilingual nature of modern LLMs to enhance their safety and reliability across diverse linguistic landscapes.
Create account to get full access
Cross-Linguistic Spread of Fake Information
Spread of Misinformation Across Languages
The paper discusses how misinformation and disinformation can spread across language barriers in multilingual language models (LLMs). LLMs are trained on data from many languages, which can lead to the unintentional propagation of false or misleading information across those languages. This is a concerning issue, as it can contribute to the rapid spread of fake news and erode public trust.
The researchers highlight several studies that have examined this problem, demonstrating how knowledge learned by LLMs in one language can "spill over" into their outputs in other languages, even if the original misinformation was only present in a subset of the training data.
Plain English Explanation
Large language models are trained on data from many different languages, allowing them to understand and generate text in multiple languages. However, this also means that any inaccurate or misleading information present in the training data can spread across language barriers when the model is used.
For example, if a language model is trained on text that contains false claims or conspiracy theories in one language, it may start producing similar misinformation when asked to generate text in other languages, even if the original false information was not present in those other language datasets. This can contribute to the rapid spread of fake news and erode public trust in information across linguistic boundaries.
The researchers point to several studies that have investigated this issue, showing how knowledge learned by language models in one language can "spill over" into their outputs in other languages, even if the original misinformation was only present in a subset of the training data.
Technical Explanation
The paper discusses the cross-linguistic spread of fake information in multilingual language models (LLMs). LLMs are trained on data from a wide range of languages, which can lead to the unintentional propagation of false or misleading information across those languages.
The researchers highlight several studies that have examined this problem. For example, one study found that knowledge learned by LLMs in one language can "spill over" into their outputs in other languages, even if the original misinformation was only present in a subset of the training data. Similarly, another study demonstrated how LLMs can learn and retain false information from their training data, which can then be propagated across language barriers.
These findings are concerning, as they suggest that the rapid spread of fake news and the erosion of public trust in information can occur not just within a single language, but across linguistic boundaries as well.
Critical Analysis
The research presented in the paper highlights a significant and understudied issue in the development of multilingual language models. The studies cited demonstrate the potential for LLMs to inadvertently spread misinformation and disinformation across languages, which could have far-reaching societal consequences.
However, the paper does not delve into potential solutions or mitigation strategies for this problem. Some studies have explored techniques for "unlearning" or selectively removing problematic knowledge from LLMs, but the authors do not discuss the applicability of these approaches to the cross-linguistic spread of fake information.
Additionally, the paper does not address the potential challenges of implementing effective safeguards against this issue, such as the difficulty of identifying and labeling misleading information in the diverse datasets used to train multilingual LLMs. Further research may be needed to develop comprehensive solutions that can reliably mitigate the cross-linguistic spread of fake information.
Conclusion
The research discussed in this paper highlights a concerning issue in the development of multilingual language models: the potential for the unintentional propagation of misinformation and disinformation across language barriers. The studies cited demonstrate how knowledge learned by LLMs in one language can "spill over" into their outputs in other languages, even when the original false information was only present in a subset of the training data.
This problem is significant, as it can contribute to the rapid spread of fake news and erode public trust in information across linguistic boundaries. While the paper does not propose specific solutions, it underscores the need for further research and the development of effective safeguards to address this challenge. As the use of multilingual LLMs continues to grow, ensuring the integrity and reliability of the information they generate will be crucial for maintaining public trust and social stability.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Cross-Lingual Unlearning of Selective Knowledge in Multilingual Language Models
Minseok Choi, Kyunghyun Min, Jaegul Choo
0
0
Pretrained language models memorize vast amounts of information, including private and copyrighted data, raising significant safety concerns. Retraining these models after excluding sensitive data is prohibitively expensive, making machine unlearning a viable, cost-effective alternative. Previous research has focused on machine unlearning for monolingual models, but we find that unlearning in one language does not necessarily transfer to others. This vulnerability makes models susceptible to low-resource language attacks, where sensitive information remains accessible in less dominant languages. This paper presents a pioneering approach to machine unlearning for multilingual language models, selectively erasing information across different languages while maintaining overall performance. Specifically, our method employs an adaptive unlearning scheme that assigns language-dependent weights to address different language performances of multilingual language models. Empirical results demonstrate the effectiveness of our framework compared to existing unlearning baselines, setting a new standard for secure and adaptable multilingual language models.
6/19/2024

Rethinking Machine Unlearning for Large Language Models
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Xiaojun Xu, Yuguang Yao, Hang Li, Kush R. Varshney, Mohit Bansal, Sanmi Koyejo, Yang Liu
0
0
We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
4/8/2024

Machine Unlearning in Large Language Models
Saaketh Koundinya Gundavarapu, Shreya Agarwal, Arushi Arora, Chandana Thimmalapura Jagadeeshaiah
0
0
Machine unlearning, a novel area within artificial intelligence, focuses on addressing the challenge of selectively forgetting or reducing undesirable knowledge or behaviors in machine learning models, particularly in the context of large language models (LLMs). This paper introduces a methodology to align LLMs, such as Open Pre-trained Transformer Language Models, with ethical, privacy, and safety standards by leveraging the gradient ascent algorithm for knowledge unlearning. Our approach aims to selectively erase or modify learned information in LLMs, targeting harmful responses and copyrighted content. This paper presents a dual-pronged approach to enhance the ethical and safe behavior of large language models (LLMs) by addressing the issues of harmful responses and copyrighted content. To mitigate harmful responses, we applied gradient ascent on the PKU dataset, achieving a 75% reduction in harmful responses for Open Pre-trained Transformer Language Models (OPT1.3b and OPT2.7b) citet{zhang2022opt} while retaining previous knowledge using the TruthfulQA dataset citet{DBLP:journals/corr/abs-2109-07958}. For handling copyrighted content, we constructed a custom dataset based on the Lord of the Rings corpus and aligned LLMs (OPT1.3b and OPT2.7b) citet{zhang2022opt} through LoRA: Low-Rank Adaptation of Large Language Models citet{DBLP:journals/corr/abs-2106-09685} finetuning. Subsequently, we employed gradient ascent to unlearn the Lord of the Rings content, resulting in a remarkable reduction in the presence of copyrighted material. To maintain a diverse knowledge base, we utilized the Book Corpus dataset. Additionally, we propose a new evaluation technique for assessing the effectiveness of harmful unlearning.
5/27/2024
💬
Towards Safer Large Language Models through Machine Unlearning
Zheyuan Liu, Guangyao Dou, Zhaoxuan Tan, Yijun Tian, Meng Jiang
0
0
The rapid advancement of Large Language Models (LLMs) has demonstrated their vast potential across various domains, attributed to their extensive pretraining knowledge and exceptional generalizability. However, LLMs often encounter challenges in generating harmful content when faced with problematic prompts. To address this problem, existing work attempted to implement a gradient ascent based approach to prevent LLMs from producing harmful output. While these methods can be effective, they frequently impact the model utility in responding to normal prompts. To address this gap, we introduce Selective Knowledge negation Unlearning (SKU), a novel unlearning framework for LLMs, designed to eliminate harmful knowledge while preserving utility on normal prompts. Specifically, SKU is consisted of two stages: harmful knowledge acquisition stage and knowledge negation stage. The first stage aims to identify and acquire harmful knowledge within the model, whereas the second is dedicated to remove this knowledge. SKU selectively isolates and removes harmful knowledge in model parameters, ensuring the model's performance remains robust on normal prompts. Our experiments conducted across various LLM architectures demonstrate that SKU identifies a good balance point between removing harmful information and preserving utility.
6/6/2024