Cross-Lingual Unlearning of Selective Knowledge in Multilingual Language Models

0
Sign in to get full access
Overview
- This paper explores a novel approach to "unlearning" selective knowledge in multilingual language models, which can help mitigate issues like copyright infringement and the spread of harmful content.
- The researchers propose a cross-lingual unlearning method that can remove specific knowledge from a model while preserving its overall performance across multiple languages.
- This work builds on prior research on machine unlearning in large language models and rethinking machine unlearning to develop more robust and flexible unlearning techniques.
Plain English Explanation
Language models trained on vast amounts of online data can sometimes inadvertently learn information that should not be retained, such as copyrighted material or toxic content. The researchers in this paper present a way to selectively remove this problematic knowledge from the model while keeping its overall language understanding capabilities intact.
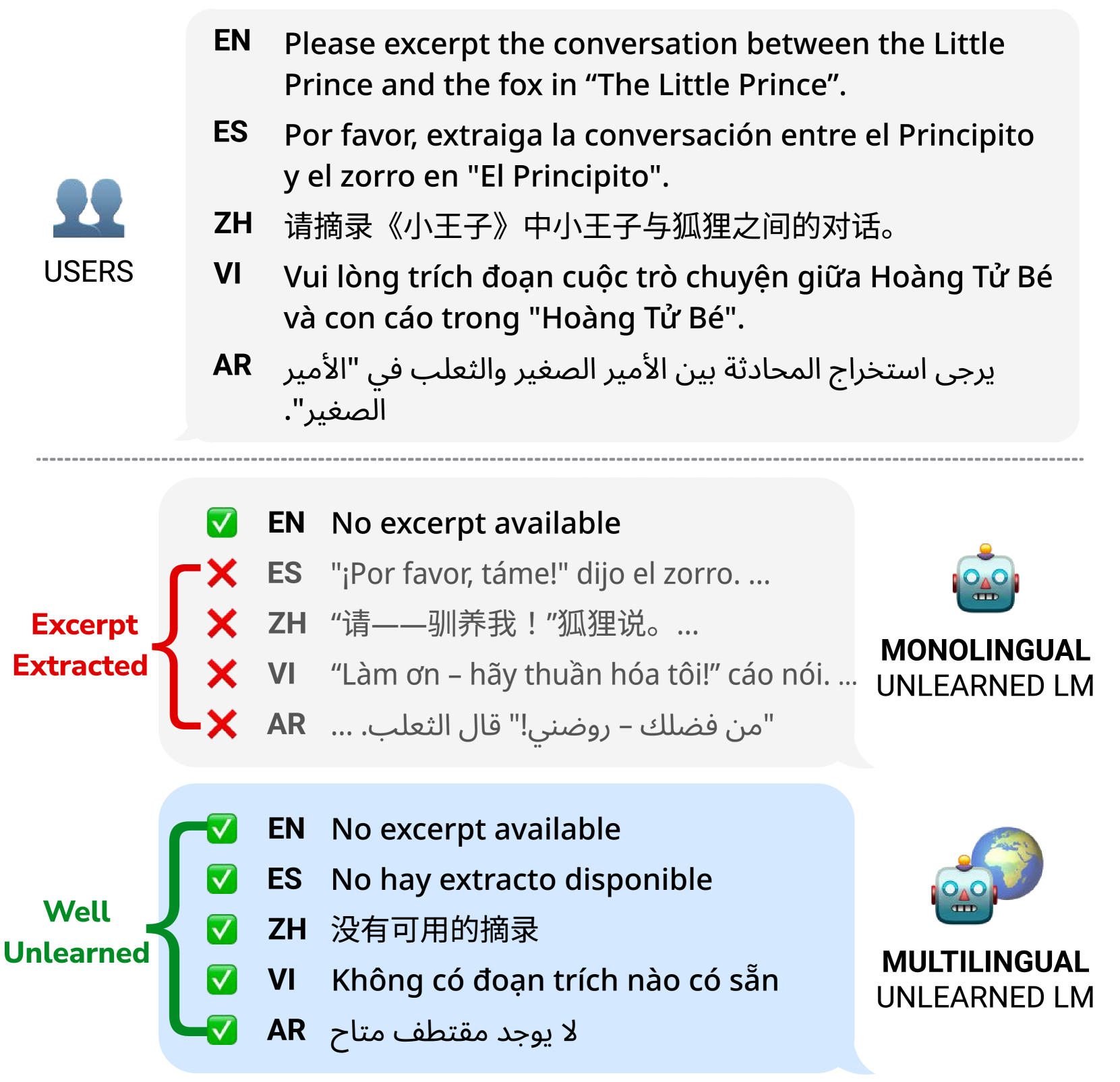
The key idea is to use a "cross-lingual" approach, which means leveraging the model's ability to understand multiple languages to facilitate the unlearning process. By training the model to forget specific information in one language, they found they could effectively remove that knowledge across all the languages the model knows.
This selective unlearning technique could be useful for avoiding copyright infringement or making large language models safer by removing harmful content, without compromising the model's overall performance. It builds on previous work on machine unlearning of pre-trained models to develop more nuanced and effective unlearning strategies.
Technical Explanation
The researchers propose a cross-lingual unlearning method that can selectively remove knowledge from a multilingual language model while preserving its overall performance across multiple languages.
The key elements of their approach include:
-
Identifying Knowledge to Unlearn: The researchers first identify the specific knowledge they want to remove from the model, such as text snippets that may infringe on copyrights or contain toxic content.
-
Cross-Lingual Unlearning: Instead of unlearning this knowledge in a single language, the researchers leverage the model's multilingual capabilities to unlearn the targeted knowledge across all the languages it understands. This "cross-lingual" approach is more effective than unlearning in a single language.
-
Preserving Overall Performance: The researchers carefully design the unlearning process to remove the targeted knowledge while minimizing the impact on the model's overall language understanding abilities across multiple languages.
Through extensive experiments, the researchers demonstrate the effectiveness of their cross-lingual unlearning approach on several benchmark datasets and real-world scenarios. They show that their method can selectively remove unwanted knowledge while maintaining the model's performance on standard language tasks.
Critical Analysis
The researchers have introduced an innovative cross-lingual unlearning technique that addresses important practical challenges in deploying large language models, such as avoiding copyright infringement and making models safer.
However, the paper does not extensively explore the potential limitations or unintended consequences of this approach. For example, it's unclear how the unlearning process might affect the model's coherence, factual knowledge, or other aspects of its language understanding. Additionally, the researchers do not discuss potential biases or fairness issues that could arise from selectively removing knowledge from a multilingual model.
Further research is needed to better understand the long-term effects of this cross-lingual unlearning technique and to explore ways to make it more robust and transparent. Ongoing work in the areas of rethinking machine unlearning and machine unlearning of pre-trained models may provide valuable insights for advancing this line of research.
Conclusion
This paper introduces a novel cross-lingual unlearning approach that can selectively remove unwanted knowledge from multilingual language models while preserving their overall performance. This work has important implications for deploying large language models more safely and responsibly, as it provides a mechanism for mitigating issues like copyright infringement and the spread of harmful content.
While further research is needed to fully understand the limitations and long-term impacts of this approach, the cross-lingual unlearning technique represents a significant step forward in developing more flexible and robust machine unlearning capabilities for large-scale language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cross-Lingual Unlearning of Selective Knowledge in Multilingual Language Models
Minseok Choi, Kyunghyun Min, Jaegul Choo
Pretrained language models memorize vast amounts of information, including private and copyrighted data, raising significant safety concerns. Retraining these models after excluding sensitive data is prohibitively expensive, making machine unlearning a viable, cost-effective alternative. Previous research has focused on machine unlearning for monolingual models, but we find that unlearning in one language does not necessarily transfer to others. This vulnerability makes models susceptible to low-resource language attacks, where sensitive information remains accessible in less dominant languages. This paper presents a pioneering approach to machine unlearning for multilingual language models, selectively erasing information across different languages while maintaining overall performance. Specifically, our method employs an adaptive unlearning scheme that assigns language-dependent weights to address different language performances of multilingual language models. Empirical results demonstrate the effectiveness of our framework compared to existing unlearning baselines, setting a new standard for secure and adaptable multilingual language models.
Read more6/19/2024

0
Every Language Counts: Learn and Unlearn in Multilingual LLMs
Taiming Lu, Philipp Koehn
This paper investigates the propagation of harmful information in multilingual large language models (LLMs) and evaluates the efficacy of various unlearning methods. We demonstrate that fake information, regardless of the language it is in, once introduced into these models through training data, can spread across different languages, compromising the integrity and reliability of the generated content. Our findings reveal that standard unlearning techniques, which typically focus on English data, are insufficient in mitigating the spread of harmful content in multilingual contexts and could inadvertently reinforce harmful content across languages. We show that only by addressing harmful responses in both English and the original language of the harmful data can we effectively eliminate generations for all languages. This underscores the critical need for comprehensive unlearning strategies that consider the multilingual nature of modern LLMs to enhance their safety and reliability across diverse linguistic landscapes.
Read more6/21/2024

0
Machine Unlearning in Large Language Models
Saaketh Koundinya Gundavarapu, Shreya Agarwal, Arushi Arora, Chandana Thimmalapura Jagadeeshaiah
Machine unlearning, a novel area within artificial intelligence, focuses on addressing the challenge of selectively forgetting or reducing undesirable knowledge or behaviors in machine learning models, particularly in the context of large language models (LLMs). This paper introduces a methodology to align LLMs, such as Open Pre-trained Transformer Language Models, with ethical, privacy, and safety standards by leveraging the gradient ascent algorithm for knowledge unlearning. Our approach aims to selectively erase or modify learned information in LLMs, targeting harmful responses and copyrighted content. This paper presents a dual-pronged approach to enhance the ethical and safe behavior of large language models (LLMs) by addressing the issues of harmful responses and copyrighted content. To mitigate harmful responses, we applied gradient ascent on the PKU dataset, achieving a 75% reduction in harmful responses for Open Pre-trained Transformer Language Models (OPT1.3b and OPT2.7b) citet{zhang2022opt} while retaining previous knowledge using the TruthfulQA dataset citet{DBLP:journals/corr/abs-2109-07958}. For handling copyrighted content, we constructed a custom dataset based on the Lord of the Rings corpus and aligned LLMs (OPT1.3b and OPT2.7b) citet{zhang2022opt} through LoRA: Low-Rank Adaptation of Large Language Models citet{DBLP:journals/corr/abs-2106-09685} finetuning. Subsequently, we employed gradient ascent to unlearn the Lord of the Rings content, resulting in a remarkable reduction in the presence of copyrighted material. To maintain a diverse knowledge base, we utilized the Book Corpus dataset. Additionally, we propose a new evaluation technique for assessing the effectiveness of harmful unlearning.
Read more5/27/2024

0
Rethinking Machine Unlearning for Large Language Models
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Yuguang Yao, Chris Yuhao Liu, Xiaojun Xu, Hang Li, Kush R. Varshney, Mohit Bansal, Sanmi Koyejo, Yang Liu
We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
Read more7/16/2024