Evolving from Single-modal to Multi-modal Facial Deepfake Detection: A Survey
2406.06965
0
0

Abstract
This survey addresses the critical challenge of deepfake detection amidst the rapid advancements in artificial intelligence. As AI-generated media, including video, audio and text, become more realistic, the risk of misuse to spread misinformation and commit identity fraud increases. Focused on face-centric deepfakes, this work traces the evolution from traditional single-modality methods to sophisticated multi-modal approaches that handle audio-visual and text-visual scenarios. We provide comprehensive taxonomies of detection techniques, discuss the evolution of generative methods from auto-encoders and GANs to diffusion models, and categorize these technologies by their unique attributes. To our knowledge, this is the first survey of its kind. We also explore the challenges of adapting detection methods to new generative models and enhancing the reliability and robustness of deepfake detectors, proposing directions for future research. This survey offers a detailed roadmap for researchers, supporting the development of technologies to counter the deceptive use of AI in media creation, particularly facial forgery. A curated list of all related papers can be found at href{https://github.com/qiqitao77/Comprehensive-Advances-in-Deepfake-Detection-Spanning-Diverse-Modalities}{https://github.com/qiqitao77/Awesome-Comprehensive-Deepfake-Detection}.
Create account to get full access
Overview
• This paper provides a comprehensive survey on the evolution of facial deepfake detection techniques, from single-modal to multi-modal approaches.
• Deepfakes are synthetic media where a person's face is digitally edited to depict them saying or doing something they never actually did. As deepfake technology advances, detection methods must also evolve to keep pace.
• The paper examines the transition from using only visual cues to incorporating additional modalities like audio, text, and even behavioral patterns to detect deepfakes more accurately.
• It also covers how large language models like ChatGPT can be leveraged for multimodal deepfake detection and the role of diffusion models in this space.
Plain English Explanation
Deepfakes are manipulated videos or images where a person's face is swapped with someone else's. This technology has advanced rapidly, making it increasingly difficult to detect these forgeries using just visual cues.
The paper describes how researchers are tackling this challenge by moving from single-modal (only using visual information) to multi-modal deepfake detection. This involves incorporating additional data sources like audio, text, and even behavioral patterns to more accurately identify when a face has been digitally altered.
For example, a multi-modal system might not only look at inconsistencies in the video, but also analyze the audio to see if it matches the lip movements, and cross-reference the content with known information about the person. This helps catch deepfakes that could slip through using just one type of data.
The paper also explores how powerful language models like ChatGPT can be used to assist in multi-modal deepfake detection. These models can draw connections between different cues to identify manipulated media. Additionally, new AI techniques like diffusion models are emerging as effective tools for this task.
Technical Explanation
The paper begins by providing background on the evolution of deepfake detection methods. Initially, researchers relied solely on visual cues like facial artifacts, lighting inconsistencies, and other pixel-level anomalies to identify manipulated media. However, as deepfake generation techniques became more sophisticated, these single-modal approaches became less effective.
The paper then examines the shift towards multi-modal deepfake detection. By incorporating additional data sources like audio, text, and behavioral patterns, researchers can build more robust and accurate detection systems. For example, analyzing the correlation between lip movements and audio, or cross-referencing statements made in the video with known facts about the person, can help uncover manipulated content.
The survey also covers how large language models like ChatGPT can be leveraged for multi-modal deepfake detection. These models can understand the semantic and contextual relationships between different modalities, allowing them to detect inconsistencies that might be missed by single-modal approaches.
Additionally, the paper discusses the emergence of diffusion models as a promising technique for deepfake detection. Diffusion models, which are based on the process of adding noise to an image and then reversing it, have shown potential in identifying manipulated media.
Critical Analysis
The paper provides a comprehensive overview of the state-of-the-art in deepfake detection, highlighting the important shift from single-modal to multi-modal approaches. However, the authors acknowledge that even multi-modal systems are not infallible, as deepfake generation techniques continue to evolve rapidly.
One potential limitation mentioned is the reliance on large, labeled datasets for training multi-modal models. Acquiring and curating such datasets can be a significant challenge, and the models may not generalize well to real-world scenarios where the deepfakes are more nuanced or diverse.
Additionally, the paper does not delve deeply into the potential privacy and ethical concerns surrounding the use of multi-modal deepfake detection systems. As these systems become more sophisticated, there may be increasing concerns about the potential for misuse or overreach in surveillance and monitoring applications.
Further research is needed to address these challenges and ensure that the development of deepfake detection technologies is balanced with the protection of individual privacy and civil liberties.
Conclusion
This survey paper provides a comprehensive overview of the evolution of facial deepfake detection, from single-modal to multi-modal approaches. As deepfake generation techniques become more advanced, detection methods must also adapt to maintain accuracy and reliability.
The incorporation of additional modalities like audio, text, and behavioral patterns has shown promise in improving deepfake detection. Furthermore, the integration of large language models and diffusion-based techniques offer new avenues for addressing this challenge.
While the advances in multi-modal deepfake detection are encouraging, the authors highlight the need for continued research to address the limitations and potential ethical concerns. As this technology continues to evolve, it will be crucial to strike a balance between effective detection and the protection of individual privacy and rights.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Deepfake Generation and Detection: A Benchmark and Survey
Gan Pei, Jiangning Zhang, Menghan Hu, Zhenyu Zhang, Chengjie Wang, Yunsheng Wu, Guangtao Zhai, Jian Yang, Chunhua Shen, Dacheng Tao
0
0
Deepfake is a technology dedicated to creating highly realistic facial images and videos under specific conditions, which has significant application potential in fields such as entertainment, movie production, digital human creation, to name a few. With the advancements in deep learning, techniques primarily represented by Variational Autoencoders and Generative Adversarial Networks have achieved impressive generation results. More recently, the emergence of diffusion models with powerful generation capabilities has sparked a renewed wave of research. In addition to deepfake generation, corresponding detection technologies continuously evolve to regulate the potential misuse of deepfakes, such as for privacy invasion and phishing attacks. This survey comprehensively reviews the latest developments in deepfake generation and detection, summarizing and analyzing current state-of-the-arts in this rapidly evolving field. We first unify task definitions, comprehensively introduce datasets and metrics, and discuss developing technologies. Then, we discuss the development of several related sub-fields and focus on researching four representative deepfake fields: face swapping, face reenactment, talking face generation, and facial attribute editing, as well as forgery detection. Subsequently, we comprehensively benchmark representative methods on popular datasets for each field, fully evaluating the latest and influential published works. Finally, we analyze challenges and future research directions of the discussed fields.
5/17/2024

An Analysis of Recent Advances in Deepfake Image Detection in an Evolving Threat Landscape
Sifat Muhammad Abdullah, Aravind Cheruvu, Shravya Kanchi, Taejoong Chung, Peng Gao, Murtuza Jadliwala, Bimal Viswanath
0
0
Deepfake or synthetic images produced using deep generative models pose serious risks to online platforms. This has triggered several research efforts to accurately detect deepfake images, achieving excellent performance on publicly available deepfake datasets. In this work, we study 8 state-of-the-art detectors and argue that they are far from being ready for deployment due to two recent developments. First, the emergence of lightweight methods to customize large generative models, can enable an attacker to create many customized generators (to create deepfakes), thereby substantially increasing the threat surface. We show that existing defenses fail to generalize well to such emph{user-customized generative models} that are publicly available today. We discuss new machine learning approaches based on content-agnostic features, and ensemble modeling to improve generalization performance against user-customized models. Second, the emergence of textit{vision foundation models} -- machine learning models trained on broad data that can be easily adapted to several downstream tasks -- can be misused by attackers to craft adversarial deepfakes that can evade existing defenses. We propose a simple adversarial attack that leverages existing foundation models to craft adversarial samples textit{without adding any adversarial noise}, through careful semantic manipulation of the image content. We highlight the vulnerabilities of several defenses against our attack, and explore directions leveraging advanced foundation models and adversarial training to defend against this new threat.
4/26/2024
🌿
Parents and Children: Distinguishing Multimodal DeepFakes from Natural Images
Roberto Amoroso, Davide Morelli, Marcella Cornia, Lorenzo Baraldi, Alberto Del Bimbo, Rita Cucchiara
0
0
Recent advancements in diffusion models have enabled the generation of realistic deepfakes from textual prompts in natural language. While these models have numerous benefits across various sectors, they have also raised concerns about the potential misuse of fake images and cast new pressures on fake image detection. In this work, we pioneer a systematic study on deepfake detection generated by state-of-the-art diffusion models. Firstly, we conduct a comprehensive analysis of the performance of contrastive and classification-based visual features, respectively extracted from CLIP-based models and ResNet or ViT-based architectures trained on image classification datasets. Our results demonstrate that fake images share common low-level cues, which render them easily recognizable. Further, we devise a multimodal setting wherein fake images are synthesized by different textual captions, which are used as seeds for a generator. Under this setting, we quantify the performance of fake detection strategies and introduce a contrastive-based disentangling method that lets us analyze the role of the semantics of textual descriptions and low-level perceptual cues. Finally, we release a new dataset, called COCOFake, containing about 1.2M images generated from the original COCO image-caption pairs using two recent text-to-image diffusion models, namely Stable Diffusion v1.4 and v2.0.
5/22/2024
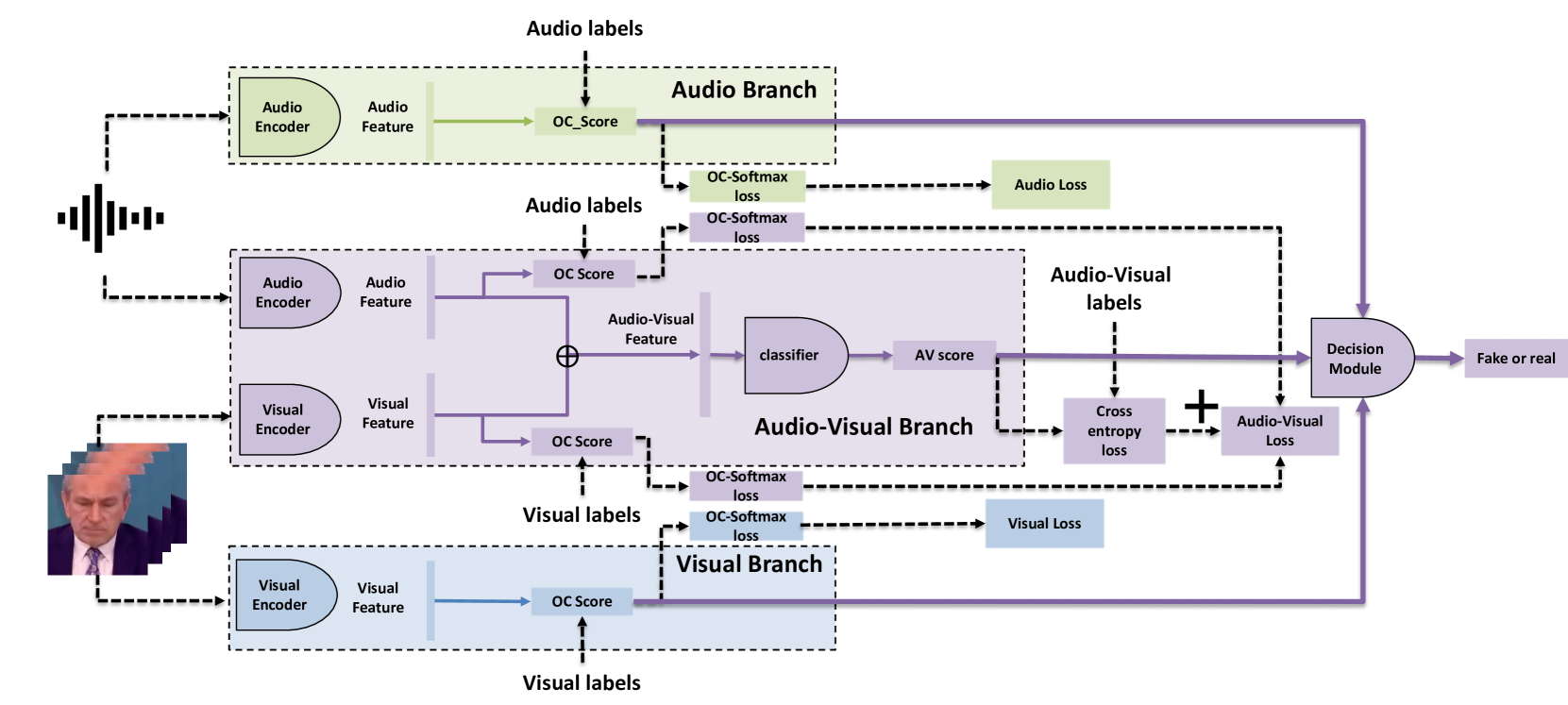
A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
Kyungbok Lee, You Zhang, Zhiyao Duan
0
0
This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake video(Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and unsynchronized video). The experimental results show that our approach improves the model's detection of unseen attacks by an average of 7.31% across four test sets, compared to the baseline model. Additionally, our proposed framework offers interpretability, indicating which modality the model identifies as fake.
6/21/2024