A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
2406.14176
0
0
Abstract
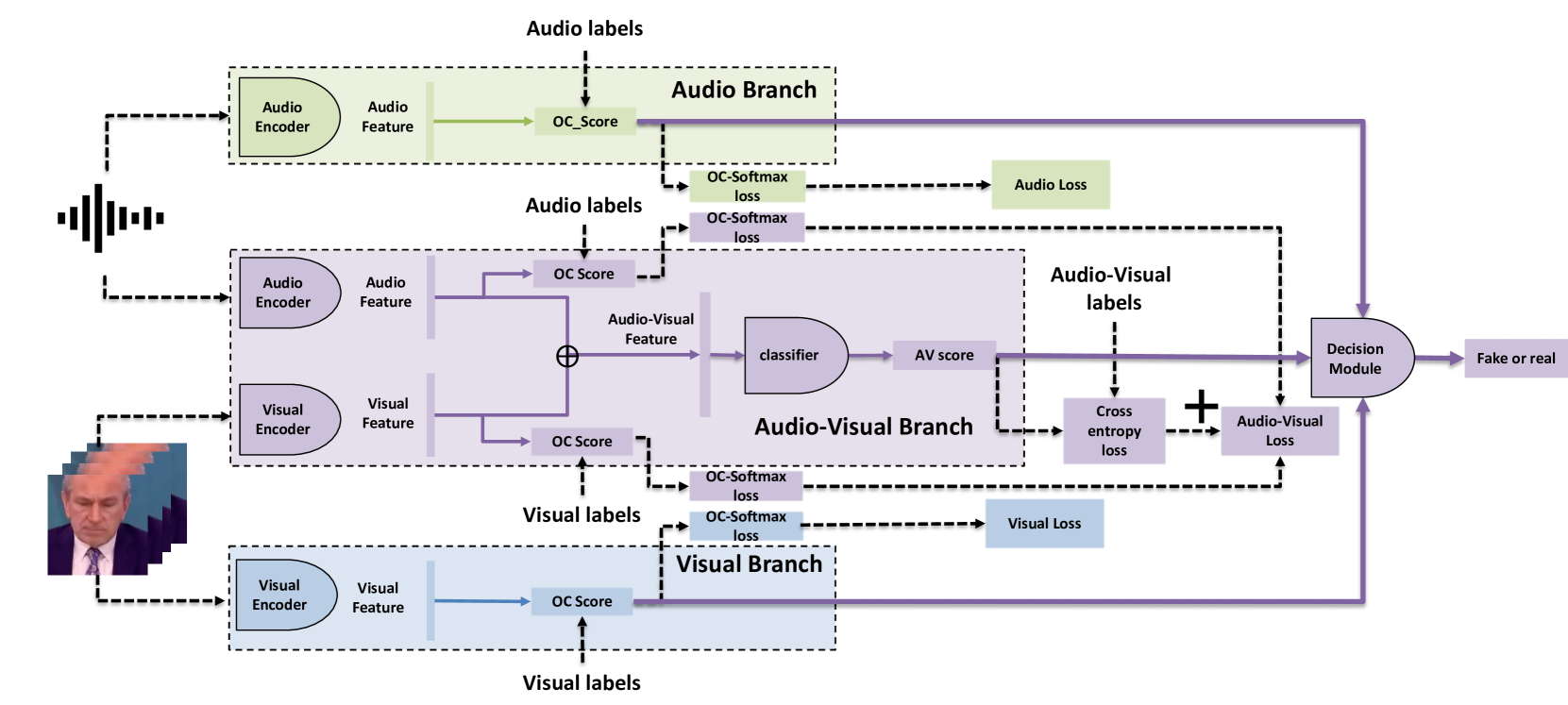
This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake video(Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and unsynchronized video). The experimental results show that our approach improves the model's detection of unseen attacks by an average of 7.31% across four test sets, compared to the baseline model. Additionally, our proposed framework offers interpretability, indicating which modality the model identifies as fake.
Create account to get full access
Overview
- This paper presents a multi-stream fusion approach with one-class learning for detecting audio-visual deepfake videos.
- The work is supported by a New York State Center of Excellence in Data Science award, a National Institute of Justice (NIJ) Graduate Research Fellowship, and National Science Foundation (NSF) funding.
- The proposed method combines visual and audio cues to improve the detection of deepfake videos, which are synthetic media generated using artificial intelligence.
- The one-class learning approach aims to accurately identify real videos without relying on large datasets of fake videos, which can be challenging to obtain.
Plain English Explanation
Deepfake videos are becoming more common, where artificial intelligence is used to create fake videos that appear real. This paper introduces a new way to detect these deepfake videos by analyzing both the video and audio.
The key idea is to use "one-class learning", which means the system is trained to recognize real videos without needing many examples of fake videos. This is important because fake video datasets can be hard to come by.
The system takes in both the video and audio from a clip and fuses the information together to make a decision about whether the clip is real or not. This multi-modal approach helps catch subtle signs of manipulation that may not be visible in just the video or just the audio alone.
Overall, this work aims to improve the generalization of deepfake detection by leveraging both visual and audio cues, without needing large datasets of fake videos to train on.
Technical Explanation
The proposed method uses a multi-stream neural network architecture to process both the video and audio inputs. The visual stream extracts features from the video frames, while the audio stream processes the corresponding audio signals. These two sets of features are then fused together using a series of fully connected layers to produce the final classification output.
The key innovation is the use of one-class learning, where the model is trained to recognize only real videos, without access to large datasets of fake videos. This helps the system generalize better to unseen types of deepfakes. The authors explore different fusion strategies, such as early, intermediate, and late fusion, to determine the optimal way to combine the visual and audio cues.
The model is evaluated on several benchmark deepfake detection datasets, including FaceForensics++, Celeb-DF, and DeeperForensics-1.0. The results show that the multi-stream fusion approach outperforms single-modal baselines and achieves state-of-the-art performance on these tasks.
Critical Analysis
The paper presents a promising approach for detecting deepfake videos, but there are a few potential limitations and areas for further research:
-
The one-class learning strategy relies on having a sufficiently large and diverse dataset of real videos, which may not always be available. Exploring ways to enhance generalization with limited real data would be valuable.
-
The paper does not provide a detailed analysis of the types of audio and visual cues the model is learning to detect. Understanding these signatures could lead to more interpretable and robust deepfake detection systems.
-
The evaluation is limited to a few popular deepfake datasets, but it would be important to test the approach on a wider range of datasets and real-world scenarios to assess its broader applicability.
-
The paper does not discuss the computational complexity and inference time of the proposed multi-stream architecture, which could be an important factor for real-world deployment.
Overall, this work represents an important step forward in the field of audio-visual deepfake detection, but further research is needed to address the above limitations and enhance the practical viability of the approach.
Conclusion
This paper introduces a multi-stream fusion approach with one-class learning for audio-visual deepfake detection. The key contribution is the use of a multi-modal architecture that combines visual and audio cues to improve the generalization of deepfake detection, without requiring large datasets of fake videos.
The results demonstrate the effectiveness of this approach on several benchmark datasets, suggesting it could be a valuable tool for combating the growing threat of deepfake media. However, there are still some limitations that need to be addressed, such as the dependence on large datasets of real videos and the need for a more comprehensive evaluation.
As deepfake technology continues to advance, the development of robust and practical detection methods will be crucial for maintaining trust in digital media. This work represents an important step in that direction, and future research building on these ideas could have significant implications for the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection
Trevine Oorloff, Surya Koppisetti, Nicol`o Bonettini, Divyaraj Solanki, Ben Colman, Yaser Yacoob, Ali Shahriyari, Gaurav Bharaj
0
0
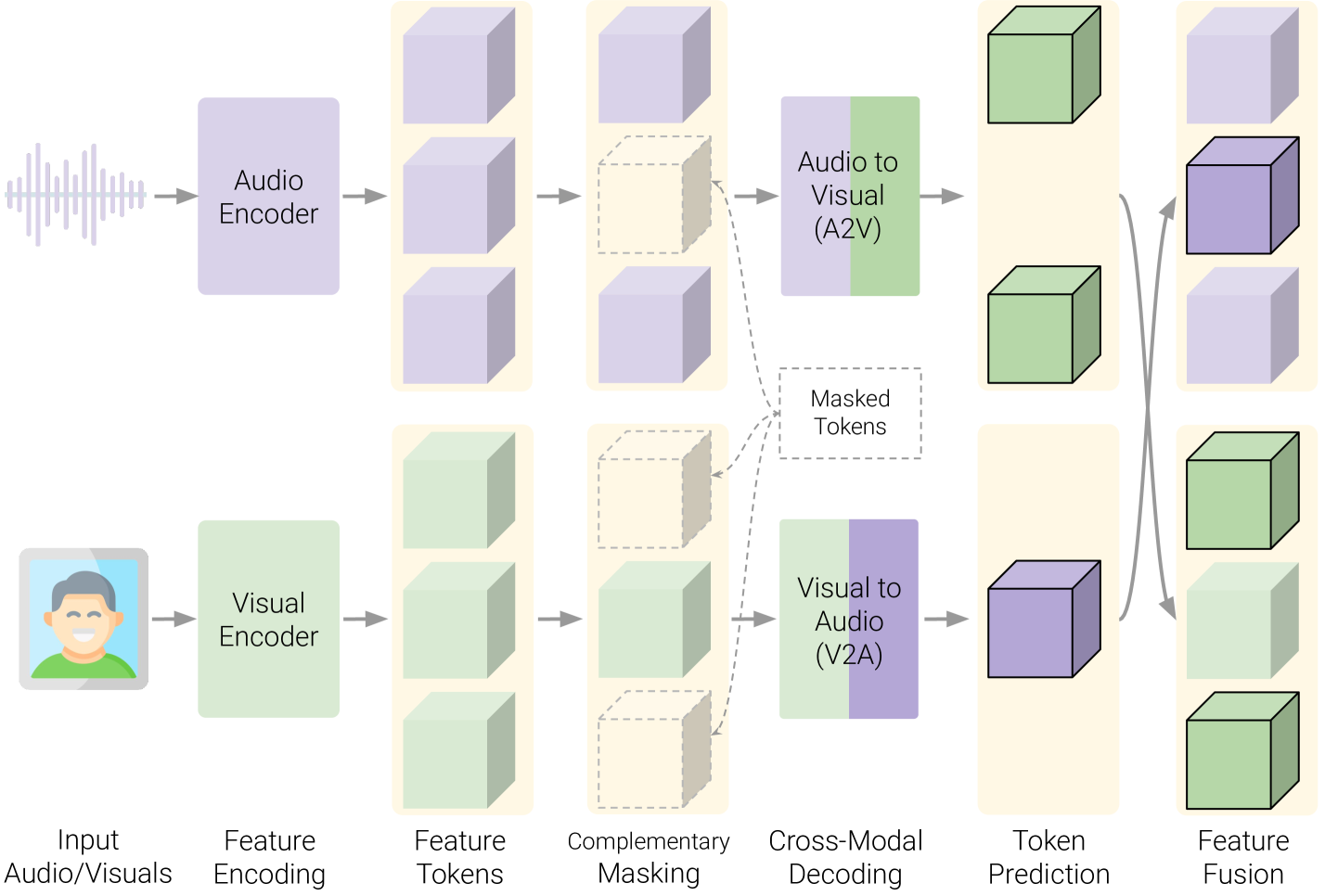
With the rapid growth in deepfake video content, we require improved and generalizable methods to detect them. Most existing detection methods either use uni-modal cues or rely on supervised training to capture the dissonance between the audio and visual modalities. While the former disregards the audio-visual correspondences entirely, the latter predominantly focuses on discerning audio-visual cues within the training corpus, thereby potentially overlooking correspondences that can help detect unseen deepfakes. We present Audio-Visual Feature Fusion (AVFF), a two-stage cross-modal learning method that explicitly captures the correspondence between the audio and visual modalities for improved deepfake detection. The first stage pursues representation learning via self-supervision on real videos to capture the intrinsic audio-visual correspondences. To extract rich cross-modal representations, we use contrastive learning and autoencoding objectives, and introduce a novel audio-visual complementary masking and feature fusion strategy. The learned representations are tuned in the second stage, where deepfake classification is pursued via supervised learning on both real and fake videos. Extensive experiments and analysis suggest that our novel representation learning paradigm is highly discriminative in nature. We report 98.6% accuracy and 99.1% AUC on the FakeAVCeleb dataset, outperforming the current audio-visual state-of-the-art by 14.9% and 9.9%, respectively.
6/6/2024

Zero-Shot Fake Video Detection by Audio-Visual Consistency
Xiaolou Li, Zehua Liu, Chen Chen, Lantian Li, Li Guo, Dong Wang
0
0
Recent studies have advocated the detection of fake videos as a one-class detection task, predicated on the hypothesis that the consistency between audio and visual modalities of genuine data is more significant than that of fake data. This methodology, which solely relies on genuine audio-visual data while negating the need for forged counterparts, is thus delineated as a `zero-shot' detection paradigm. This paper introduces a novel zero-shot detection approach anchored in content consistency across audio and video. By employing pre-trained ASR and VSR models, we recognize the audio and video content sequences, respectively. Then, the edit distance between the two sequences is computed to assess whether the claimed video is genuine. Experimental results indicate that, compared to two mainstream approaches based on semantic consistency and temporal consistency, our approach achieves superior generalizability across various deepfake techniques and demonstrates strong robustness against audio-visual perturbations. Finally, state-of-the-art performance gains can be achieved by simply integrating the decision scores of these three systems.
6/13/2024

Evolving from Single-modal to Multi-modal Facial Deepfake Detection: A Survey
Ping Liu, Qiqi Tao, Joey Tianyi Zhou
0
0
This survey addresses the critical challenge of deepfake detection amidst the rapid advancements in artificial intelligence. As AI-generated media, including video, audio and text, become more realistic, the risk of misuse to spread misinformation and commit identity fraud increases. Focused on face-centric deepfakes, this work traces the evolution from traditional single-modality methods to sophisticated multi-modal approaches that handle audio-visual and text-visual scenarios. We provide comprehensive taxonomies of detection techniques, discuss the evolution of generative methods from auto-encoders and GANs to diffusion models, and categorize these technologies by their unique attributes. To our knowledge, this is the first survey of its kind. We also explore the challenges of adapting detection methods to new generative models and enhancing the reliability and robustness of deepfake detectors, proposing directions for future research. This survey offers a detailed roadmap for researchers, supporting the development of technologies to counter the deceptive use of AI in media creation, particularly facial forgery. A curated list of all related papers can be found at href{https://github.com/qiqitao77/Comprehensive-Advances-in-Deepfake-Detection-Spanning-Diverse-Modalities}{https://github.com/qiqitao77/Awesome-Comprehensive-Deepfake-Detection}.
6/12/2024
Unmasking Illusions: Understanding Human Perception of Audiovisual Deepfakes
Ammarah Hashmi, Sahibzada Adil Shahzad, Chia-Wen Lin, Yu Tsao, Hsin-Min Wang
0
0
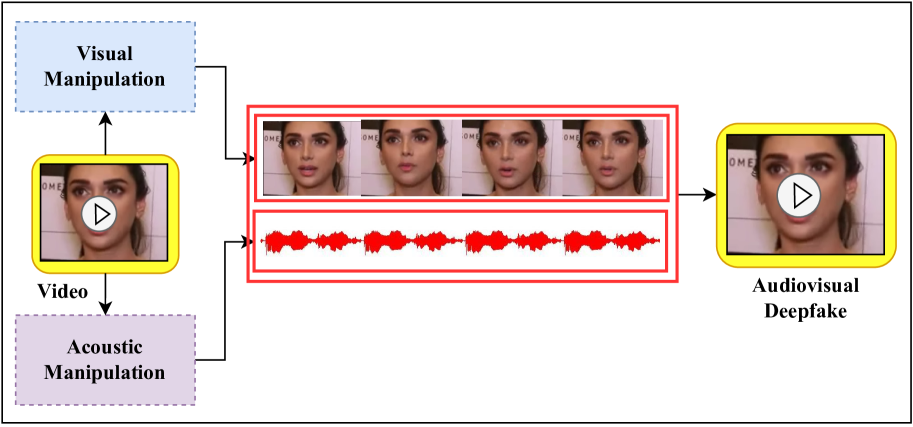
The emergence of contemporary deepfakes has attracted significant attention in machine learning research, as artificial intelligence (AI) generated synthetic media increases the incidence of misinterpretation and is difficult to distinguish from genuine content. Currently, machine learning techniques have been extensively studied for automatically detecting deepfakes. However, human perception has been less explored. Malicious deepfakes could ultimately cause public and social problems. Can we humans correctly perceive the authenticity of the content of the videos we watch? The answer is obviously uncertain; therefore, this paper aims to evaluate the human ability to discern deepfake videos through a subjective study. We present our findings by comparing human observers to five state-ofthe-art audiovisual deepfake detection models. To this end, we used gamification concepts to provide 110 participants (55 native English speakers and 55 non-native English speakers) with a webbased platform where they could access a series of 40 videos (20 real and 20 fake) to determine their authenticity. Each participant performed the experiment twice with the same 40 videos in different random orders. The videos are manually selected from the FakeAVCeleb dataset. We found that all AI models performed better than humans when evaluated on the same 40 videos. The study also reveals that while deception is not impossible, humans tend to overestimate their detection capabilities. Our experimental results may help benchmark human versus machine performance, advance forensics analysis, and enable adaptive countermeasures.
5/8/2024