Exploiting Diffusion Prior for Generalizable Dense Prediction
2311.18832
0
0

Abstract
Contents generated by recent advanced Text-to-Image (T2I) diffusion models are sometimes too imaginative for existing off-the-shelf dense predictors to estimate due to the immitigable domain gap. We introduce DMP, a pipeline utilizing pre-trained T2I models as a prior for dense prediction tasks. To address the misalignment between deterministic prediction tasks and stochastic T2I models, we reformulate the diffusion process through a sequence of interpolations, establishing a deterministic mapping between input RGB images and output prediction distributions. To preserve generalizability, we use low-rank adaptation to fine-tune pre-trained models. Extensive experiments across five tasks, including 3D property estimation, semantic segmentation, and intrinsic image decomposition, showcase the efficacy of the proposed method. Despite limited-domain training data, the approach yields faithful estimations for arbitrary images, surpassing existing state-of-the-art algorithms.
Create account to get full access
Overview
- This paper explores a method for improving the performance of pixel-level semantic prediction tasks, such as image segmentation, across a variety of datasets and domains.
- The key idea is to leverage a diffusion prior - a model trained to generate realistic natural images - to guide the training of a semantic prediction model.
- The authors demonstrate that this approach leads to improved generalization and robustness compared to standard supervised training.
Plain English Explanation
The researchers in this paper were trying to solve a common problem in computer vision: making models that can accurately identify and label different objects, textures, and other visual elements in images. This is called "pixel-level semantic prediction" and has many real-world applications, like self-driving cars or medical image analysis.
The challenge is that these models often struggle to generalize well - they perform great on the specific datasets they were trained on, but don't do as well when applied to new images or domains. The researchers had an interesting idea to address this: using a "diffusion model."
A diffusion model is a type of AI system that can generate highly realistic-looking natural images from scratch. The key insight here is that the process of learning to generate natural images might give the model a useful prior, or starting point, for understanding the structure and content of images more generally.
So the researchers took this pre-trained diffusion model and used it to guide the training of their semantic prediction model. The idea is that by leveraging the diffusion model's inherent understanding of natural image structure, the semantic model would be better able to generalize to new visual domains.
And indeed, their experiments showed this approach led to significant improvements in performance across a range of different image datasets and tasks, compared to standard training methods. It's a clever way to make these computer vision models more robust and flexible.
Technical Explanation
The core of the researchers' approach is to leverage a pre-trained diffusion model as a guiding prior for training a semantic prediction model. Diffusion models are a type of generative AI system that learn to generate realistic natural images by gradually adding noise to clean images and then learning to reverse that process.
The key insight is that the process of learning to generate natural images imbues the diffusion model with a rich understanding of image structure and visual semantics. The researchers hypothesized that this implicit knowledge could be helpful for guiding a semantic prediction model to learn more general and transferable visual representations.
To achieve this, they introduce a novel training framework that combines the diffusion model with a semantic prediction model. The semantic model is trained to not only predict the pixel-level labels for a given input image, but also to reconstruct the input image using the diffusion model's reverse diffusion process.
This joint training objective encourages the semantic model to learn visual representations that are both discriminative for the pixel-level prediction task and generative, in the sense of being compatible with the diffusion model's generative process. Extensive experiments on a range of semantic prediction benchmarks demonstrate that this approach leads to significant improvements in generalization and robustness compared to standard supervised training.
Critical Analysis
The researchers present a compelling and well-executed approach for leveraging diffusion priors to enhance the generalization capabilities of pixel-level semantic prediction models. The empirical results are convincing, showing meaningful performance gains across multiple datasets and tasks.
That said, the paper does not extensively explore the limitations or potential failure modes of the proposed method. For example, it is not clear how the approach would scale to extremely large or complex prediction tasks, or how sensitive the performance is to the specific architecture and hyperparameters of the diffusion model.
Additionally, the paper lacks a deep dive into the qualitative behavior and internal representations learned by the semantic model when trained with the diffusion prior. A more detailed analysis of failure cases, edge cases, and the model's ability to generalize to out-of-distribution data could further strengthen the claims and insights.
Finally, the question of how to best leverage large-scale generative models like diffusion models for downstream discriminative tasks is an active area of research, with many open questions around the optimal integration strategies. The current work represents an important step, but there is likely room for further innovation and refinement of the core ideas.
Overall, this is a technically solid and conceptually interesting contribution that merits further exploration and extension by the research community.
Conclusion
This paper presents a novel approach for improving the generalization and robustness of pixel-level semantic prediction models by leveraging a pre-trained diffusion model as a guiding prior. The key insight is that the process of learning to generate realistic natural images imbues diffusion models with a rich understanding of visual structure and semantics, which can be advantageously transferred to downstream prediction tasks.
The proposed training framework, which combines semantic prediction and diffusion-based image reconstruction objectives, demonstrates significant performance gains across a range of benchmarks compared to standard supervised learning. This work highlights the potential for large-scale generative models to serve as powerful priors for enhancing the capabilities of discriminative computer vision systems.
As artificial intelligence continues to advance, techniques like this that can make models more generalizable and robust will become increasingly important, with applications spanning fields like autonomous driving, medical imaging, and beyond. The researchers have taken an important step in this direction, and their work opens up exciting avenues for future exploration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
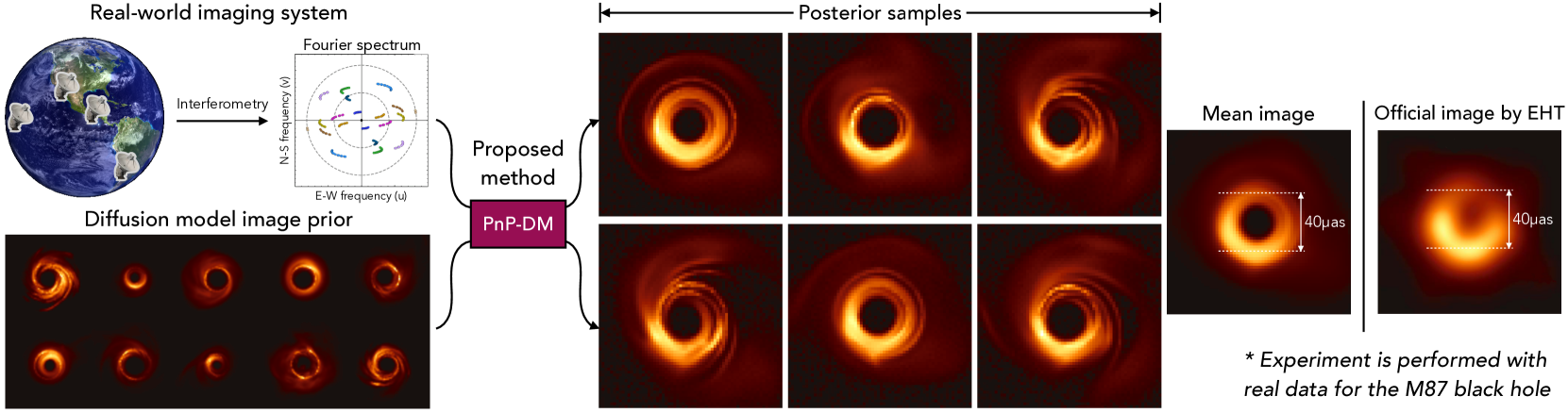
Principled Probabilistic Imaging using Diffusion Models as Plug-and-Play Priors
Zihui Wu, Yu Sun, Yifan Chen, Bingliang Zhang, Yisong Yue, Katherine L. Bouman
0
0
Diffusion models (DMs) have recently shown outstanding capability in modeling complex image distributions, making them expressive image priors for solving Bayesian inverse problems. However, most existing DM-based methods rely on approximations in the generative process to be generic to different inverse problems, leading to inaccurate sample distributions that deviate from the target posterior defined within the Bayesian framework. To harness the generative power of DMs while avoiding such approximations, we propose a Markov chain Monte Carlo algorithm that performs posterior sampling for general inverse problems by reducing it to sampling the posterior of a Gaussian denoising problem. Crucially, we leverage a general DM formulation as a unified interface that allows for rigorously solving the denoising problem with a range of state-of-the-art DMs. We demonstrate the effectiveness of the proposed method on six inverse problems (three linear and three nonlinear), including a real-world black hole imaging problem. Experimental results indicate that our proposed method offers more accurate reconstructions and posterior estimation compared to existing DM-based imaging inverse methods.
5/30/2024

Diff-Mosaic: Augmenting Realistic Representations in Infrared Small Target Detection via Diffusion Prior
Yukai Shi, Yupei Lin, Pengxu Wei, Xiaoyu Xian, Tianshui Chen, Liang Lin
0
0
Recently, researchers have proposed various deep learning methods to accurately detect infrared targets with the characteristics of indistinct shape and texture. Due to the limited variety of infrared datasets, training deep learning models with good generalization poses a challenge. To augment the infrared dataset, researchers employ data augmentation techniques, which often involve generating new images by combining images from different datasets. However, these methods are lacking in two respects. In terms of realism, the images generated by mixup-based methods lack realism and are difficult to effectively simulate complex real-world scenarios. In terms of diversity, compared with real-world scenes, borrowing knowledge from another dataset inherently has a limited diversity. Currently, the diffusion model stands out as an innovative generative approach. Large-scale trained diffusion models have a strong generative prior that enables real-world modeling of images to generate diverse and realistic images. In this paper, we propose Diff-Mosaic, a data augmentation method based on the diffusion model. This model effectively alleviates the challenge of diversity and realism of data augmentation methods via diffusion prior. Specifically, our method consists of two stages. Firstly, we introduce an enhancement network called Pixel-Prior, which generates highly coordinated and realistic Mosaic images by harmonizing pixels. In the second stage, we propose an image enhancement strategy named Diff-Prior. This strategy utilizes diffusion priors to model images in the real-world scene, further enhancing the diversity and realism of the images. Extensive experiments have demonstrated that our approach significantly improves the performance of the detection network. The code is available at https://github.com/YupeiLin2388/Diff-Mosaic
6/4/2024
🔗
A Dense Reward View on Aligning Text-to-Image Diffusion with Preference
Shentao Yang, Tianqi Chen, Mingyuan Zhou
0
0
Aligning text-to-image diffusion model (T2I) with preference has been gaining increasing research attention. While prior works exist on directly optimizing T2I by preference data, these methods are developed under the bandit assumption of a latent reward on the entire diffusion reverse chain, while ignoring the sequential nature of the generation process. This may harm the efficacy and efficiency of preference alignment. In this paper, we take on a finer dense reward perspective and derive a tractable alignment objective that emphasizes the initial steps of the T2I reverse chain. In particular, we introduce temporal discounting into DPO-style explicit-reward-free objectives, to break the temporal symmetry therein and suit the T2I generation hierarchy. In experiments on single and multiple prompt generation, our method is competitive with strong relevant baselines, both quantitatively and qualitatively. Further investigations are conducted to illustrate the insight of our approach.
5/14/2024

Learning Image Priors through Patch-based Diffusion Models for Solving Inverse Problems
Jason Hu, Bowen Song, Xiaojian Xu, Liyue Shen, Jeffrey A. Fessler
0
0
Diffusion models can learn strong image priors from underlying data distribution and use them to solve inverse problems, but the training process is computationally expensive and requires lots of data. Such bottlenecks prevent most existing works from being feasible for high-dimensional and high-resolution data such as 3D images. This paper proposes a method to learn an efficient data prior for the entire image by training diffusion models only on patches of images. Specifically, we propose a patch-based position-aware diffusion inverse solver, called PaDIS, where we obtain the score function of the whole image through scores of patches and their positional encoding and utilize this as the prior for solving inverse problems. First of all, we show that this diffusion model achieves an improved memory efficiency and data efficiency while still maintaining the capability to generate entire images via positional encoding. Additionally, the proposed PaDIS model is highly flexible and can be plugged in with different diffusion inverse solvers (DIS). We demonstrate that the proposed PaDIS approach enables solving various inverse problems in both natural and medical image domains, including CT reconstruction, deblurring, and superresolution, given only patch-based priors. Notably, PaDIS outperforms previous DIS methods trained on entire image priors in the case of limited training data, demonstrating the data efficiency of our proposed approach by learning patch-based prior.
6/5/2024