Exploiting the equivalence between quantum neural networks and perceptrons

0
🧠
Sign in to get full access
Overview
- Quantum machine learning models based on parametrized quantum circuits, called quantum neural networks (QNNs), are promising for near-term quantum devices.
- The paper explores the expressivity and inductive bias of QNNs by mapping them to classical perceptrons.
- This simplifies training and allows systematic study of the inductive biases of different QNN embeddings on Boolean data.
- The paper also proposes alternate strategies to move beyond standard QNNs, including using a QNN to generate a classical DNN-inspired kernel and constructing a layered non-linear QNN.
Plain English Explanation
Quantum neural networks (QNNs) are a type of machine learning model that use quantum computers to perform computations. Researchers are excited about the potential of QNNs to run on the quantum devices that will be available in the near future.
This paper looks at how expressive and flexible QNNs are, and what kinds of data and problems they are good at. The researchers did this by mapping QNNs to a simpler type of machine learning model called a classical perceptron. This allowed them to more easily study the strengths and weaknesses of different ways of encoding data into QNNs.
The paper shows that current QNN models have some significant limitations. For example, a common way of encoding data into a QNN cannot express certain basic mathematical functions, like the parity function for 3 or more inputs. The researchers also found that popular QNN encodings tend to have an inductive bias towards functions with low class balance, meaning they don't generalize as well as deep neural networks on some types of data.
To address these issues, the paper proposes two alternative strategies. The first is to use a QNN to help generate a more powerful classical machine learning model, like a deep neural network. The second is to build a more complex, layered QNN that is proven to be fully expressive on Boolean data and has a richer inductive bias.
Overall, the paper provides important insight into the current state of QNNs and highlights the challenges that need to be overcome before they can be truly useful general-purpose learning algorithms.
Technical Explanation
The paper begins by noting that quantum machine learning models based on parametrized quantum circuits, known as quantum neural networks (QNNs), are considered promising candidates for near-term quantum devices. To explore the expressivity and inductive bias of QNNs, the researchers exploit an exact mapping from QNNs with inputs x to classical perceptrons acting on x ⊗ x (generalized to complex inputs).
This mapping to classical perceptrons simplifies training and allows the researchers to systematically study the inductive biases of different QNN embeddings on Boolean data. They find that a QNN with amplitude encoding cannot express the Boolean parity function for n ≥ 3, which is just one of an exponential number of data structures that such a QNN is unable to express.
The researchers then explore two alternate strategies to move beyond standard QNNs. First, they use a QNN to help generate a classical DNN-inspired kernel. Second, they draw an analogy to the hierarchical structure of deep neural networks and construct a layered non-linear QNN that is provably fully expressive on Boolean data, while also exhibiting a richer inductive bias than simple QNNs.
Finally, the paper discusses characteristics of the QNN literature that may obscure how challenging it is to achieve quantum advantage over deep learning algorithms on classical data.
Critical Analysis
The paper provides a thoughtful and nuanced analysis of the expressivity and inductive biases of current quantum neural network (QNN) models. By mapping QNNs to classical perceptrons, the researchers are able to gain valuable insights into the limitations of standard QNN architectures and encodings.
One key limitation highlighted is the inability of amplitude-encoded QNNs to express certain basic Boolean functions, like the parity function for 3 or more inputs. This is a significant shortcoming that calls into question the general-purpose learning capabilities of these models.
The paper also raises concerns about the inductive biases of popular QNN embeddings, which tend to favor functions with low class balance. This can reduce the generalization performance of QNNs compared to deep neural networks, which exhibit much richer inductive biases.
While the proposed alternate strategies, such as using a QNN to generate a classical DNN-inspired kernel and constructing a layered non-linear QNN, are promising directions, the paper acknowledges that significant challenges remain in achieving quantum advantage over classical deep learning on real-world data.
One area for further research suggested by the paper is a more systematic exploration of the inductive biases of different QNN embeddings and architectures. Understanding these biases will be crucial for developing QNN models that can effectively compete with state-of-the-art classical machine learning algorithms.
Overall, this paper provides a valuable critique of current QNN research and highlights the need for continued innovation and rigorous analysis to realize the full potential of quantum machine learning.
Conclusion
This paper offers an important perspective on the current state of quantum neural networks (QNNs) and the challenges they face in becoming useful general-purpose learning algorithms. By mapping QNNs to classical perceptrons, the researchers uncover significant limitations in the expressivity and inductive biases of standard QNN models.
The proposed alternate strategies, such as using a QNN to generate a classical DNN-inspired kernel and constructing a layered non-linear QNN, represent promising directions for overcoming these limitations. However, the paper makes it clear that significant work remains to be done before QNNs can reliably outperform classical deep learning approaches on real-world data.
Overall, this paper provides valuable insights that should help guide future research in quantum machine learning, pushing the field to tackle the difficult problems head-on and develop QNN architectures and training methods that can truly harness the power of quantum computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Exploiting the equivalence between quantum neural networks and perceptrons
Chris Mingard, Jessica Pointing, Charles London, Yoonsoo Nam, Ard A. Louis
Quantum machine learning models based on parametrized quantum circuits, also called quantum neural networks (QNNs), are considered to be among the most promising candidates for applications on near-term quantum devices. Here we explore the expressivity and inductive bias of QNNs by exploiting an exact mapping from QNNs with inputs $x$ to classical perceptrons acting on $x otimes x$ (generalised to complex inputs). The simplicity of the perceptron architecture allows us to provide clear examples of the shortcomings of current QNN models, and the many barriers they face to becoming useful general-purpose learning algorithms. For example, a QNN with amplitude encoding cannot express the Boolean parity function for $ngeq 3$, which is but one of an exponential number of data structures that such a QNN is unable to express. Mapping a QNN to a classical perceptron simplifies training, allowing us to systematically study the inductive biases of other, more expressive embeddings on Boolean data. Several popular embeddings primarily produce an inductive bias towards functions with low class balance, reducing their generalisation performance compared to deep neural network architectures which exhibit much richer inductive biases. We explore two alternate strategies that move beyond standard QNNs. In the first, we use a QNN to help generate a classical DNN-inspired kernel. In the second we draw an analogy to the hierarchical structure of deep neural networks and construct a layered non-linear QNN that is provably fully expressive on Boolean data, while also exhibiting a richer inductive bias than simple QNNs. Finally, we discuss characteristics of the QNN literature that may obscure how hard it is to achieve quantum advantage over deep learning algorithms on classical data.
Read more7/8/2024
🧠
0
Do Quantum Neural Networks have Simplicity Bias?
Jessica Pointing
One hypothesis for the success of deep neural networks (DNNs) is that they are highly expressive, which enables them to be applied to many problems, and they have a strong inductive bias towards solutions that are simple, known as simplicity bias, which allows them to generalise well on unseen data because most real-world data is structured (i.e. simple). In this work, we explore the inductive bias and expressivity of quantum neural networks (QNNs), which gives us a way to compare their performance to those of DNNs. Our results show that it is possible to have simplicity bias with certain QNNs, but we prove that this type of QNN limits the expressivity of the QNN. We also show that it is possible to have QNNs with high expressivity, but they either have no inductive bias or a poor inductive bias and result in a worse generalisation performance compared to DNNs. We demonstrate that an artificial (restricted) inductive bias can be produced by intentionally restricting the expressivity of a QNN. Our results suggest a bias-expressivity tradeoff. Our conclusion is that the QNNs we studied can not generally offer an advantage over DNNs, because these QNNs either have a poor inductive bias or poor expressivity compared to DNNs.
Read more7/4/2024
0
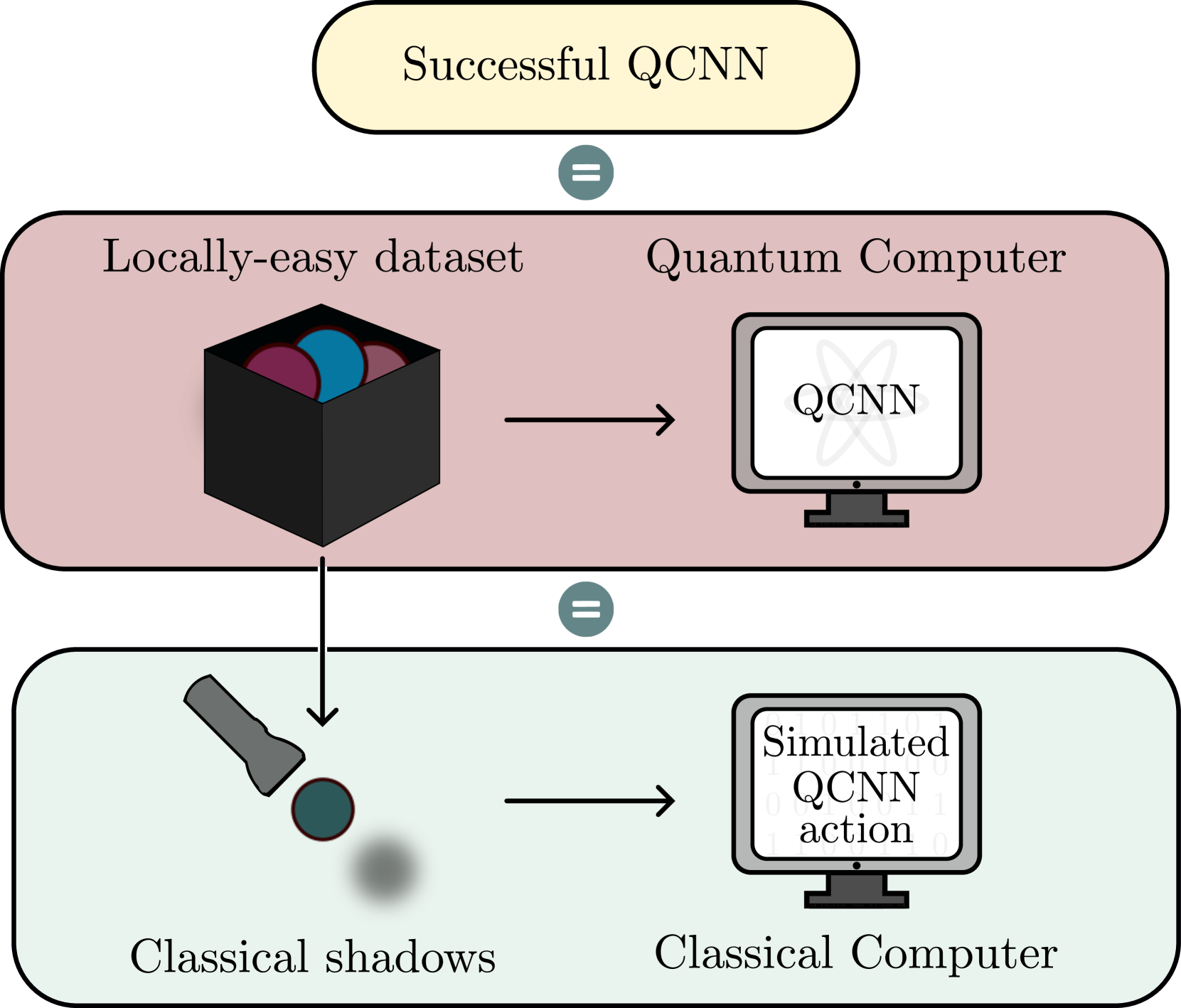
Quantum Convolutional Neural Networks are (Effectively) Classically Simulable
Pablo Bermejo, Paolo Braccia, Manuel S. Rudolph, Zoe Holmes, Lukasz Cincio, M. Cerezo
Quantum Convolutional Neural Networks (QCNNs) are widely regarded as a promising model for Quantum Machine Learning (QML). In this work we tie their heuristic success to two facts. First, that when randomly initialized, they can only operate on the information encoded in low-bodyness measurements of their input states. And second, that they are commonly benchmarked on locally-easy'' datasets whose states are precisely classifiable by the information encoded in these low-bodyness observables subspace. We further show that the QCNN's action on this subspace can be efficiently classically simulated by a classical algorithm equipped with Pauli shadows on the dataset. Indeed, we present a shadow-based simulation of QCNNs on up-to $1024$ qubits for phases of matter classification. Our results can then be understood as highlighting a deeper symptom of QML: Models could only be showing heuristic success because they are benchmarked on simple problems, for which their action can be classically simulated. This insight points to the fact that non-trivial datasets are a truly necessary ingredient for moving forward with QML. To finish, we discuss how our results can be extrapolated to classically simulate other architectures.
Read more8/26/2024
0
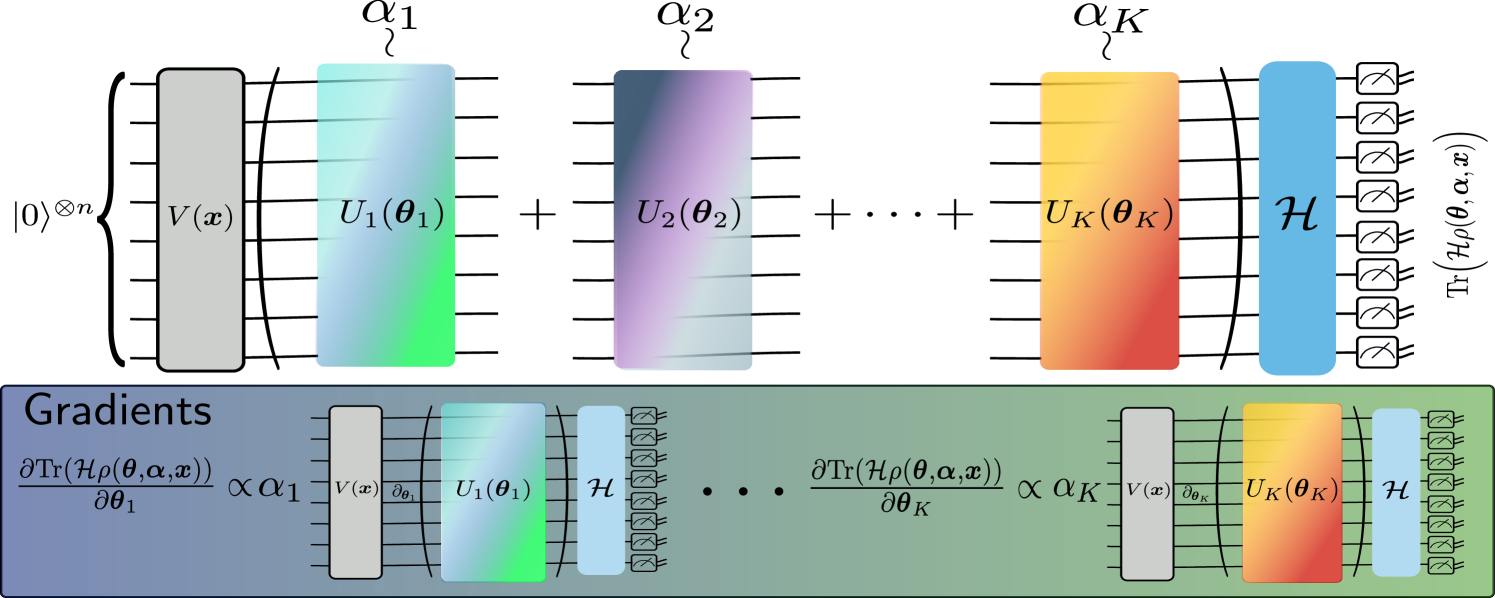
Training-efficient density quantum machine learning
Brian Coyle, El Amine Cherrat, Nishant Jain, Natansh Mathur, Snehal Raj, Skander Kazdaghli, Iordanis Kerenidis
Quantum machine learning requires powerful, flexible and efficiently trainable models to be successful in solving challenging problems. In this work, we present density quantum neural networks, a learning model incorporating randomisation over a set of trainable unitaries. These models generalise quantum neural networks using parameterised quantum circuits, and allow a trade-off between expressibility and efficient trainability, particularly on quantum hardware. We demonstrate the flexibility of the formalism by applying it to two recently proposed model families. The first are commuting-block quantum neural networks (QNNs) which are efficiently trainable but may be limited in expressibility. The second are orthogonal (Hamming-weight preserving) quantum neural networks which provide well-defined and interpretable transformations on data but are challenging to train at scale on quantum devices. Density commuting QNNs improve capacity with minimal gradient complexity overhead, and density orthogonal neural networks admit a quadratic-to-constant gradient query advantage with minimal to no performance loss. We conduct numerical experiments on synthetic translationally invariant data and MNIST image data with hyperparameter optimisation to support our findings. Finally, we discuss the connection to post-variational quantum neural networks, measurement-based quantum machine learning and the dropout mechanism.
Read more5/31/2024