Exploration of Masked and Causal Language Modelling for Text Generation
2405.12630
0
0
💬
Abstract
Large Language Models (LLMs) have revolutionised the field of Natural Language Processing (NLP) and have achieved state-of-the-art performance in practically every task in this field. However, the prevalent approach used in text generation, Causal Language Modelling (CLM), which generates text sequentially from left to right, inherently limits the freedom of the model, which does not decide when and where each token is generated. In contrast, Masked Language Modelling (MLM), primarily used for language understanding tasks, can generate tokens anywhere in the text and any order. This paper conducts an extensive comparison of MLM and CLM approaches for text generation tasks. To do so, we pre-train several language models of comparable sizes on three different datasets, namely 1) medical discharge summaries, 2) movie plot synopses, and 3) authorship verification datasets. To assess the quality of the generations, we first employ quantitative metrics and then perform a qualitative human evaluation to analyse coherence and grammatical correctness. In addition, we evaluate the usefulness of the generated texts by using them in three different downstream tasks: 1) Entity Recognition, 2) Text Classification, and 3) Authorship Verification. The results show that MLM consistently outperforms CLM in text generation across all datasets, with higher quantitative scores and better coherence in the generated text. The study also finds textit{no strong correlation} between the quality of the generated text and the performance of the models in the downstream tasks. With this study, we show that MLM for text generation has great potential for future research and provides direction for future studies in this area.
Create account to get full access
Overview
- This paper compares two approaches to text generation: Causal Language Modelling (CLM) and Masked Language Modelling (MLM).
- CLM generates text sequentially from left to right, while MLM can generate tokens in any order.
- The study pre-trains language models using both approaches on three different datasets and evaluates the quality and usefulness of the generated text.
Plain English Explanation
Large language models (LLMs) have revolutionized the field of natural language processing (NLP) and are now used in a wide range of tasks. However, the predominant approach to text generation, called Causal Language Modelling (CLM), has some limitations. CLM generates text one word at a time, from left to right, which can restrict the model's freedom in deciding where and when to generate each word.
In contrast, Masked Language Modelling (MLM), primarily used for language understanding tasks, allows the model to generate tokens anywhere in the text and in any order. This paper investigates whether MLM can also be effective for text generation tasks.
The researchers pre-trained several language models using both the CLM and MLM approaches on three different datasets: medical discharge summaries, movie plot synopses, and authorship verification datasets. They then evaluated the quality of the generated text using both quantitative metrics and human evaluations, focusing on coherence and grammatical correctness.
Additionally, the researchers tested the usefulness of the generated text by using it in three downstream tasks: entity recognition, text classification, and authorship verification. The results showed that the MLM-based models consistently outperformed the CLM-based models in text generation, with higher scores and better coherence. However, the researchers found no strong correlation between the quality of the generated text and the performance of the models in the downstream tasks.
This study suggests that the MLM approach has great potential for future text generation research and could provide new directions for the field.
Technical Explanation
The paper conducts an extensive comparison of Masked Language Modelling (MLM) and Causal Language Modelling (CLM) approaches for text generation tasks. MLM, primarily used for language understanding tasks, can generate tokens anywhere in the text and in any order, while CLM generates text sequentially from left to right.
To assess the performance of these two approaches, the researchers pre-trained several language models of comparable sizes on three different datasets: 1) medical discharge summaries, 2) movie plot synopses, and 3) authorship verification datasets. They then evaluated the quality of the generated text using both quantitative metrics and human evaluations, focusing on coherence and grammatical correctness.
In addition, the researchers evaluated the usefulness of the generated texts by using them in three different downstream tasks: 1) Entity Recognition, 2) Text Classification, and 3) Authorship Verification.
The results showed that MLM consistently outperformed CLM in text generation across all datasets, with higher quantitative scores and better coherence in the generated text. However, the study also found no strong correlation between the quality of the generated text and the performance of the models in the downstream tasks.
Critical Analysis
The paper provides a comprehensive and well-designed comparison of the MLM and CLM approaches for text generation. By using multiple datasets and a range of evaluation metrics, the researchers have conducted a thorough and rigorous analysis.
One potential limitation of the study is that it does not explore the reasons behind the lack of correlation between the quality of the generated text and the performance in the downstream tasks. Further investigation into this aspect could provide valuable insights into the relationship between text generation and task-specific performance.
Additionally, the paper does not delve into the computational and training time differences between the two approaches, which could be an important consideration for practical applications. Incorporating such an analysis could enhance the overall understanding of the tradeoffs involved in using MLM versus CLM for text generation.
Despite these minor limitations, the study makes a significant contribution to the understanding of text generation using large language models and provides a clear direction for future research in this area.
Conclusion
This paper presents an extensive comparison of Masked Language Modelling (MLM) and Causal Language Modelling (CLM) approaches for text generation tasks. The results show that MLM consistently outperforms CLM in generating coherent and grammatically correct text, across multiple datasets. However, the study also found no strong correlation between the quality of the generated text and the performance of the models in downstream tasks.
The findings of this research suggest that the MLM approach has great potential for future text generation studies and could open up new directions for the field. By exploring the use of MLM for text generation, the paper contributes to our understanding of the capabilities and limitations of large language models, which have become increasingly influential in natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
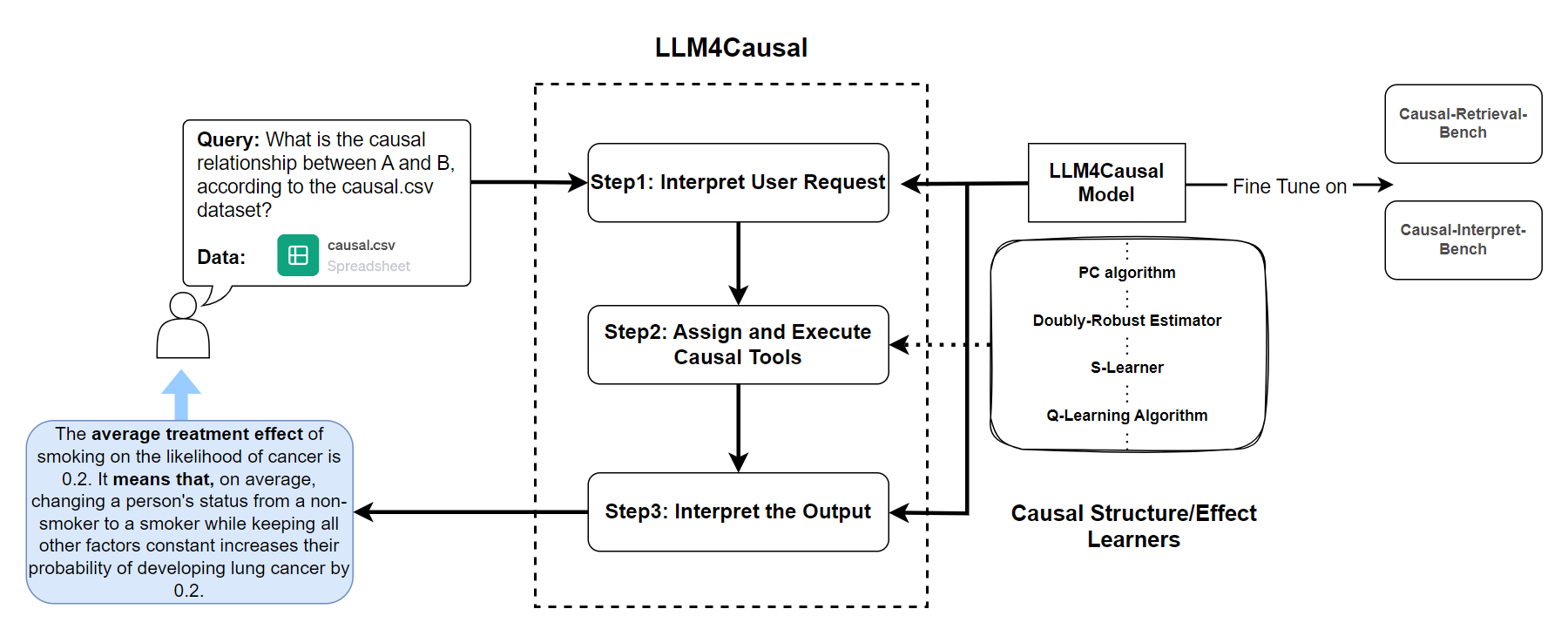
Large Language Model for Causal Decision Making
Haitao Jiang, Lin Ge, Yuhe Gao, Jianian Wang, Rui Song
0
0
Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to perform inference based on user-specified structured data and knowledge in corpus-rare concepts, such as causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. By conducting end-to-end evaluations and two ablation studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers, which significantly outperforms the baselines.
4/15/2024

Looking Right is Sometimes Right: Investigating the Capabilities of Decoder-only LLMs for Sequence Labeling
David Duki'c, Jan v{S}najder
0
0
Pre-trained language models based on masked language modeling (MLM) excel in natural language understanding (NLU) tasks. While fine-tuned MLM-based encoders consistently outperform causal language modeling decoders of comparable size, recent decoder-only large language models (LLMs) perform on par with smaller MLM-based encoders. Although their performance improves with scale, LLMs fall short of achieving state-of-the-art results in information extraction (IE) tasks, many of which are formulated as sequence labeling (SL). We hypothesize that LLMs' poor SL performance stems from causal masking, which prevents the model from attending to tokens on the right of the current token. Yet, how exactly and to what extent LLMs' performance on SL can be improved remains unclear. We explore techniques for improving the SL performance of open LLMs on IE tasks by applying layer-wise removal of the causal mask (CM) during LLM fine-tuning. This approach yields performance gains competitive with state-of-the-art SL models, matching or outperforming the results of CM removal from all blocks. Our findings hold for diverse SL tasks, demonstrating that open LLMs with layer-dependent CM removal outperform strong MLM-based encoders and even instruction-tuned LLMs.
6/7/2024

Unlocking the Potential of Large Language Models for Clinical Text Anonymization: A Comparative Study
David Pissarra, Isabel Curioso, Jo~ao Alveira, Duarte Pereira, Bruno Ribeiro, Tom'as Souper, Vasco Gomes, Andr'e V. Carreiro, Vitor Rolla
0
0
Automated clinical text anonymization has the potential to unlock the widespread sharing of textual health data for secondary usage while assuring patient privacy and safety. Despite the proposal of many complex and theoretically successful anonymization solutions in literature, these techniques remain flawed. As such, clinical institutions are still reluctant to apply them for open access to their data. Recent advances in developing Large Language Models (LLMs) pose a promising opportunity to further the field, given their capability to perform various tasks. This paper proposes six new evaluation metrics tailored to the challenges of generative anonymization with LLMs. Moreover, we present a comparative study of LLM-based methods, testing them against two baseline techniques. Our results establish LLM-based models as a reliable alternative to common approaches, paving the way toward trustworthy anonymization of clinical text.
6/4/2024

LLMs for Generating and Evaluating Counterfactuals: A Comprehensive Study
Van Bach Nguyen, Paul Youssef, Jorg Schlotterer, Christin Seifert
0
0
As NLP models become more complex, understanding their decisions becomes more crucial. Counterfactuals (CFs), where minimal changes to inputs flip a model's prediction, offer a way to explain these models. While Large Language Models (LLMs) have shown remarkable performance in NLP tasks, their efficacy in generating high-quality CFs remains uncertain. This work fills this gap by investigating how well LLMs generate CFs for two NLU tasks. We conduct a comprehensive comparison of several common LLMs, and evaluate their CFs, assessing both intrinsic metrics, and the impact of these CFs on data augmentation. Moreover, we analyze differences between human and LLM-generated CFs, providing insights for future research directions. Our results show that LLMs generate fluent CFs, but struggle to keep the induced changes minimal. Generating CFs for Sentiment Analysis (SA) is less challenging than NLI where LLMs show weaknesses in generating CFs that flip the original label. This also reflects on the data augmentation performance, where we observe a large gap between augmenting with human and LLMs CFs. Furthermore, we evaluate LLMs' ability to assess CFs in a mislabelled data setting, and show that they have a strong bias towards agreeing with the provided labels. GPT4 is more robust against this bias and its scores correlate well with automatic metrics. Our findings reveal several limitations and point to potential future work directions.
5/3/2024