Exploring Frequency-Inspired Optimization in Transformer for Efficient Single Image Super-Resolution
2308.05022
0
0
🛠️
Abstract
Transformer-based methods have exhibited remarkable potential in single image super-resolution (SISR) by effectively extracting long-range dependencies. However, most of the current research in this area has prioritized the design of transformer blocks to capture global information, while overlooking the importance of incorporating high-frequency priors, which we believe could be beneficial. In our study, we conducted a series of experiments and found that transformer structures are more adept at capturing low-frequency information, but have limited capacity in constructing high-frequency representations when compared to their convolutional counterparts. Our proposed solution, the cross-refinement adaptive feature modulation transformer (CRAFT), integrates the strengths of both convolutional and transformer structures. It comprises three key components: the high-frequency enhancement residual block (HFERB) for extracting high-frequency information, the shift rectangle window attention block (SRWAB) for capturing global information, and the hybrid fusion block (HFB) for refining the global representation. To tackle the inherent intricacies of transformer structures, we introduce a frequency-guided post-training quantization (PTQ) method aimed at enhancing CRAFT's efficiency. These strategies incorporate adaptive dual clipping and boundary refinement. To further amplify the versatility of our proposed approach, we extend our PTQ strategy to function as a general quantization method for transformer-based SISR techniques. Our experimental findings showcase CRAFT's superiority over current state-of-the-art methods, both in full-precision and quantization scenarios. These results underscore the efficacy and universality of our PTQ strategy.
Create account to get full access
Overview
- Transformers have shown great potential for single image super-resolution (SISR) by effectively capturing long-range dependencies.
- However, most current research has focused on designing transformer blocks to extract global information, while overlooking the importance of incorporating high-frequency priors.
- The authors conducted experiments and found that transformers are better at capturing low-frequency information, but have limited capacity in constructing high-frequency representations compared to convolutional models.
Plain English Explanation
The paper discusses a new approach to single image super-resolution (SISR) that combines the strengths of both convolutional and transformer-based models. SISR is the process of taking a low-resolution image and generating a higher-quality version of it.
Transformer-based models have been very successful at SISR by effectively capturing long-range dependencies in the image. However, the authors found that these models are better at extracting low-frequency information, while they struggle to represent high-frequency details compared to traditional convolutional models.
To address this, the authors propose a new model called CRAFT (cross-refinement adaptive feature modulation transformer). CRAFT integrates the strengths of both convolutional and transformer structures. It has three key components:
- The high-frequency enhancement residual block (HFERB) for extracting high-frequency information.
- The shift rectangle window attention block (SRWAB) for capturing global information.
- The hybrid fusion block (HFB) for refining the global representation.
The authors also introduce a frequency-guided post-training quantization (PTQ) method to improve the efficiency of the CRAFT model, which can also be applied to other transformer-based SISR techniques.
Technical Explanation
The proposed CRAFT model combines the strengths of convolutional and transformer structures to effectively capture both low-frequency and high-frequency information for SISR.
The high-frequency enhancement residual block (HFERB) is designed to extract high-frequency details from the input image. It uses a series of convolutional layers and residual connections to preserve and amplify the high-frequency components.
The shift rectangle window attention block (SRWAB) is a transformer-based module that captures global information by applying attention mechanisms across a shifted rectangular window. This allows the model to effectively model long-range dependencies in the image.
The hybrid fusion block (HFB) combines the outputs of the HFERB and SRWAB modules, refining the global representation by integrating the high-frequency and long-range information.
To address the inherent challenges of transformer structures, the authors propose a frequency-guided post-training quantization (PTQ) method. This technique incorporates adaptive dual clipping and boundary refinement strategies to enhance the efficiency of the CRAFT model without significantly compromising its performance.
The authors' experimental results demonstrate that CRAFT outperforms current state-of-the-art SISR methods, both in full-precision and quantization scenarios. This highlights the effectiveness and versatility of their proposed approach.
Critical Analysis
The paper presents a well-designed solution to the SISR problem by leveraging the complementary strengths of convolutional and transformer-based models. The authors' insights into the limitations of transformer structures in capturing high-frequency information are valuable and could inform the development of future SISR techniques.
However, the paper does not extensively discuss the potential limitations or caveats of the CRAFT model. For example, it would be interesting to understand the model's performance on more diverse datasets or its robustness to different types of image degradation.
Additionally, the authors' frequency-guided PTQ method is a promising approach, but its applicability to a broader range of transformer-based models could be further explored and validated.
Nonetheless, the paper's core contribution of integrating convolutional and transformer structures for SISR, along with the novel PTQ strategy, represents a significant advancement in the field and provides a solid foundation for future research.
Conclusion
The paper presents the CRAFT model, a novel approach to single image super-resolution that combines the strengths of convolutional and transformer-based structures. By incorporating high-frequency enhancement, global information capture, and hybrid fusion, CRAFT demonstrates superior performance over state-of-the-art SISR methods, both in full-precision and quantization scenarios.
The authors' frequency-guided post-training quantization technique further enhances the efficiency of the CRAFT model and can be applied as a general quantization method for transformer-based SISR techniques. These advancements have the potential to significantly impact the field of image enhancement and enable more efficient deployment of super-resolution models in various applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
IG-CFAT: An Improved GAN-Based Framework for Effectively Exploiting Transformers in Real-World Image Super-Resolution
Alireza Aghelan, Ali Amiryan, Abolfazl Zarghani, Behnoush Hatami
0
0
In the field of single image super-resolution (SISR), transformer-based models, have demonstrated significant advancements. However, the potential and efficiency of these models in applied fields such as real-world image super-resolution are less noticed and there are substantial opportunities for improvement. Recently, composite fusion attention transformer (CFAT), outperformed previous state-of-the-art (SOTA) models in classic image super-resolution. This paper extends the CFAT model to an improved GAN-based model called IG-CFAT to effectively exploit the performance of transformers in real-world image super-resolution. IG-CFAT incorporates a semantic-aware discriminator to reconstruct image details more accurately, significantly improving perceptual quality. Moreover, our model utilizes an adaptive degradation model to better simulate real-world degradations. Our methodology adds wavelet losses to conventional loss functions of GAN-based super-resolution models to reconstruct high-frequency details more efficiently. Empirical results demonstrate that IG-CFAT sets new benchmarks in real-world image super-resolution, outperforming SOTA models in both quantitative and qualitative metrics.
6/21/2024

RefQSR: Reference-based Quantization for Image Super-Resolution Networks
Hongjae Lee, Jun-Sang Yoo, Seung-Won Jung
0
0
Single image super-resolution (SISR) aims to reconstruct a high-resolution image from its low-resolution observation. Recent deep learning-based SISR models show high performance at the expense of increased computational costs, limiting their use in resource-constrained environments. As a promising solution for computationally efficient network design, network quantization has been extensively studied. However, existing quantization methods developed for SISR have yet to effectively exploit image self-similarity, which is a new direction for exploration in this study. We introduce a novel method called reference-based quantization for image super-resolution (RefQSR) that applies high-bit quantization to several representative patches and uses them as references for low-bit quantization of the rest of the patches in an image. To this end, we design dedicated patch clustering and reference-based quantization modules and integrate them into existing SISR network quantization methods. The experimental results demonstrate the effectiveness of RefQSR on various SISR networks and quantization methods.
4/3/2024
🖼️
Frequency-Assisted Mamba for Remote Sensing Image Super-Resolution
Yi Xiao, Qiangqiang Yuan, Kui Jiang, Yuzeng Chen, Qiang Zhang, Chia-Wen Lin
0
0
Recent progress in remote sensing image (RSI) super-resolution (SR) has exhibited remarkable performance using deep neural networks, e.g., Convolutional Neural Networks and Transformers. However, existing SR methods often suffer from either a limited receptive field or quadratic computational overhead, resulting in sub-optimal global representation and unacceptable computational costs in large-scale RSI. To alleviate these issues, we develop the first attempt to integrate the Vision State Space Model (Mamba) for RSI-SR, which specializes in processing large-scale RSI by capturing long-range dependency with linear complexity. To achieve better SR reconstruction, building upon Mamba, we devise a Frequency-assisted Mamba framework, dubbed FMSR, to explore the spatial and frequent correlations. In particular, our FMSR features a multi-level fusion architecture equipped with the Frequency Selection Module (FSM), Vision State Space Module (VSSM), and Hybrid Gate Module (HGM) to grasp their merits for effective spatial-frequency fusion. Recognizing that global and local dependencies are complementary and both beneficial for SR, we further recalibrate these multi-level features for accurate feature fusion via learnable scaling adaptors. Extensive experiments on AID, DOTA, and DIOR benchmarks demonstrate that our FMSR outperforms state-of-the-art Transformer-based methods HAT-L in terms of PSNR by 0.11 dB on average, while consuming only 28.05% and 19.08% of its memory consumption and complexity, respectively.
5/9/2024
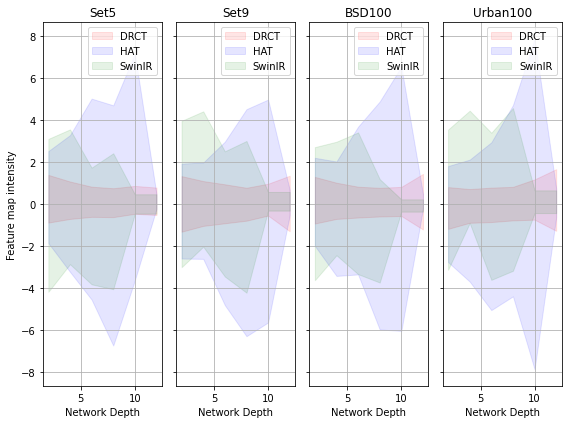
DRCT: Saving Image Super-resolution away from Information Bottleneck
Chih-Chung Hsu, Chia-Ming Lee, Yi-Shiuan Chou
0
0
In recent years, Vision Transformer-based approaches for low-level vision tasks have achieved widespread success. Unlike CNN-based models, Transformers are more adept at capturing long-range dependencies, enabling the reconstruction of images utilizing non-local information. In the domain of super-resolution, Swin-transformer-based models have become mainstream due to their capability of global spatial information modeling and their shifting-window attention mechanism that facilitates the interchange of information between different windows. Many researchers have enhanced model performance by expanding the receptive fields or designing meticulous networks, yielding commendable results. However, we observed that it is a general phenomenon for the feature map intensity to be abruptly suppressed to small values towards the network's end. This implies an information bottleneck and a diminishment of spatial information, implicitly limiting the model's potential. To address this, we propose the Dense-residual-connected Transformer (DRCT), aimed at mitigating the loss of spatial information and stabilizing the information flow through dense-residual connections between layers, thereby unleashing the model's potential and saving the model away from information bottleneck. Experiment results indicate that our approach surpasses state-of-the-art methods on benchmark datasets and performs commendably at the NTIRE-2024 Image Super-Resolution (x4) Challenge. Our source code is available at https://github.com/ming053l/DRCT
4/16/2024