Exploring Pathological Speech Quality Assessment with ASR-Powered Wav2Vec2 in Data-Scarce Context
2403.20184
0
0
Abstract
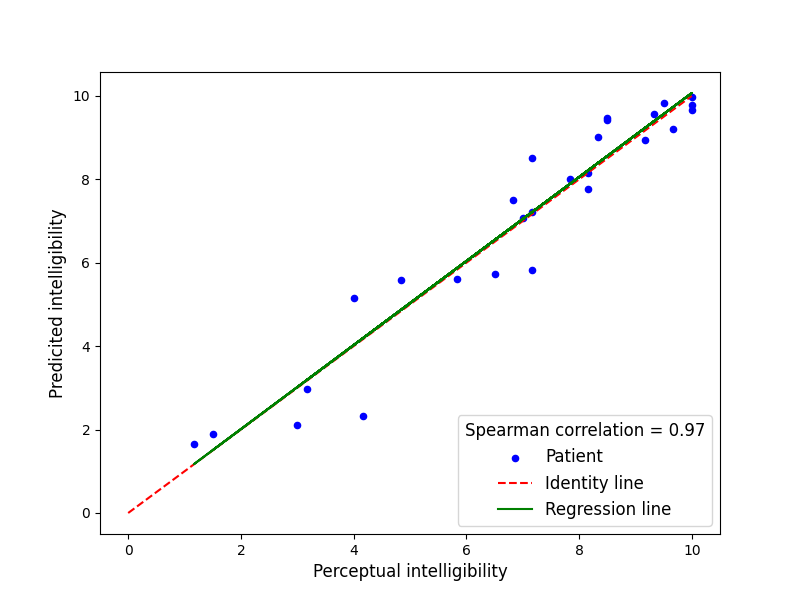
Automatic speech quality assessment has raised more attention as an alternative or support to traditional perceptual clinical evaluation. However, most research so far only gains good results on simple tasks such as binary classification, largely due to data scarcity. To deal with this challenge, current works tend to segment patients' audio files into many samples to augment the datasets. Nevertheless, this approach has limitations, as it indirectly relates overall audio scores to individual segments. This paper introduces a novel approach where the system learns at the audio level instead of segments despite data scarcity. This paper proposes to use the pre-trained Wav2Vec2 architecture for both SSL, and ASR as feature extractor in speech assessment. Carried out on the HNC dataset, our ASR-driven approach established a new baseline compared with other approaches, obtaining average $MSE=0.73$ and $MSE=1.15$ for the prediction of intelligibility and severity scores respectively, using only 95 training samples. It shows that the ASR based Wav2Vec2 model brings the best results and may indicate a strong correlation between ASR and speech quality assessment. We also measure its ability on variable segment durations and speech content, exploring factors influencing its decision.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper explores using a speech recognition model called Wav2Vec2 to assess the quality of pathological speech in scenarios with limited data.
- Pathological speech refers to speech affected by medical conditions like Parkinson's disease or stroke.
- The researchers investigate whether Wav2Vec2, trained on general speech data, can be effectively used to evaluate the quality of pathological speech without requiring extensive new training data.
Plain English Explanation
The paper looks at using a powerful speech recognition model called Wav2Vec2 to evaluate the quality of speech affected by medical conditions like Parkinson's disease or stroke. Normally, assessing the quality of this kind of "pathological" speech requires collecting a large dataset of samples, which can be time-consuming and expensive.
The key idea is to see if Wav2Vec2, which has been trained on a huge amount of general speech data, can be adapted to handle pathological speech without needing to gather a whole new dataset. This would make it much easier to assess speech quality in medical settings where data may be scarce. The researchers test how well Wav2Vec2 performs compared to other approaches, using various metrics to gauge speech quality.
The findings suggest that with some fine-tuning, Wav2Vec2 can be a promising tool for pathological speech assessment, potentially opening up new ways to monitor and manage speech-related medical conditions. By leveraging powerful AI models like this, the hope is to enable better speech analysis and support for patients, even in data-limited scenarios.
Technical Explanation
The paper explores using the Wav2Vec2 speech recognition model for the task of pathological speech quality assessment. Wav2Vec2 is a self-supervised learning approach that can capture rich speech representations from large datasets of general speech audio.
The researchers hypothesized that the strong speech modeling capabilities of Wav2Vec2, learned from natural speech, could be effectively transferred to the domain of pathological speech. This would enable pathological speech quality assessment without requiring the collection of large, specialized datasets for training.
The study evaluates Wav2Vec2's performance on two pathological speech corpora - the C2SI corpus of speech affected by Parkinson's disease, and an internal dataset of stroke-affected speech. The paper compares Wav2Vec2 to other approaches like i-vectors and DeepSpeech2, assessing speech quality using metrics like Word Error Rate (WER), Phoneme Error Rate (PER), and the correlation between predicted and ground-truth quality scores.
The results show that with just a small amount of fine-tuning, Wav2Vec2 can achieve strong performance on both pathological speech datasets, outperforming the baseline methods. This suggests the model's general speech representations can be effectively adapted to the pathological domain, opening up the potential for more accessible and scalable speech quality assessment tools.
Critical Analysis
The paper presents a well-designed study that offers promising evidence for the use of Wav2Vec2 in pathological speech quality evaluation, even in data-scarce scenarios. The authors acknowledge that further research is needed to fully understand the model's limitations and robustness across a wider range of pathological speech conditions.
One key limitation is that the evaluation was done on relatively small datasets, so the generalizability of the results remains to be seen. Additionally, the paper does not explore the potential biases or failures of the Wav2Vec2 model when faced with more diverse or severe forms of pathological speech. Further testing on larger and more diverse datasets would help validate the claims.
That said, the core insight - that powerful general-purpose speech models can be effectively adapted to specialized domains like pathological speech - is compelling and aligns with broader trends in the field of transfer learning. If this approach can be further refined and scaled, it could lead to significant improvements in speech-based monitoring and diagnosis for a range of medical conditions.
Conclusion
This research demonstrates the potential of using the Wav2Vec2 speech recognition model for pathological speech quality assessment, even in scenarios where data is limited. By leveraging the strong speech representations learned from large, general speech datasets, the approach shows promise for enabling more accessible and scalable tools to support the monitoring and management of speech-related medical conditions.
While further validation is needed, the findings suggest that advances in general-purpose speech AI can be effectively adapted to specialized domains, opening up new possibilities for improving healthcare applications that rely on speech analysis. As the field of pathological speech processing continues to evolve, techniques like this may play an increasingly important role in enhancing the diagnosis, treatment, and quality of life for patients.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
An Effective Automated Speaking Assessment Approach to Mitigating Data Scarcity and Imbalanced Distribution
Tien-Hong Lo, Fu-An Chao, Tzu-I Wu, Yao-Ting Sung, Berlin Chen
0
0
Automated speaking assessment (ASA) typically involves automatic speech recognition (ASR) and hand-crafted feature extraction from the ASR transcript of a learner's speech. Recently, self-supervised learning (SSL) has shown stellar performance compared to traditional methods. However, SSL-based ASA systems are faced with at least three data-related challenges: limited annotated data, uneven distribution of learner proficiency levels and non-uniform score intervals between different CEFR proficiency levels. To address these challenges, we explore the use of two novel modeling strategies: metric-based classification and loss reweighting, leveraging distinct SSL-based embedding features. Extensive experimental results on the ICNALE benchmark dataset suggest that our approach can outperform existing strong baselines by a sizable margin, achieving a significant improvement of more than 10% in CEFR prediction accuracy.
4/15/2024
🗣️
AV2Wav: Diffusion-Based Re-synthesis from Continuous Self-supervised Features for Audio-Visual Speech Enhancement
Ju-Chieh Chou, Chung-Ming Chien, Karen Livescu
0
0
Speech enhancement systems are typically trained using pairs of clean and noisy speech. In audio-visual speech enhancement (AVSE), there is not as much ground-truth clean data available; most audio-visual datasets are collected in real-world environments with background noise and reverberation, hampering the development of AVSE. In this work, we introduce AV2Wav, a resynthesis-based audio-visual speech enhancement approach that can generate clean speech despite the challenges of real-world training data. We obtain a subset of nearly clean speech from an audio-visual corpus using a neural quality estimator, and then train a diffusion model on this subset to generate waveforms conditioned on continuous speech representations from AV-HuBERT with noise-robust training. We use continuous rather than discrete representations to retain prosody and speaker information. With this vocoding task alone, the model can perform speech enhancement better than a masking-based baseline. We further fine-tune the diffusion model on clean/noisy utterance pairs to improve the performance. Our approach outperforms a masking-based baseline in terms of both automatic metrics and a human listening test and is close in quality to the target speech in the listening test. Audio samples can be found at https://home.ttic.edu/~jcchou/demo/avse/avse_demo.html.
4/10/2024
🗣️
A Comparison of Speech Data Augmentation Methods Using S3PRL Toolkit
Mina Huh, Ruchira Ray, Corey Karnei
0
0
Data augmentations are known to improve robustness in speech-processing tasks. In this study, we summarize and compare different data augmentation strategies using S3PRL toolkit. We explore how HuBERT and wav2vec perform using different augmentation techniques (SpecAugment, Gaussian Noise, Speed Perturbation) for Phoneme Recognition (PR) and Automatic Speech Recognition (ASR) tasks. We evaluate model performance in terms of phoneme error rate (PER) and word error rate (WER). From the experiments, we observed that SpecAugment slightly improves the performance of HuBERT and wav2vec on the original dataset. Also, we show that models trained using the Gaussian Noise and Speed Perturbation dataset are more robust when tested with augmented test sets.
4/1/2024
🚀
Tuning In: Analysis of Audio Classifier Performance in Clinical Settings with Limited Data
Hamza Mahdi, Eptehal Nashnoush, Rami Saab, Arjun Balachandar, Rishit Dagli, Lucas X. Perri, Houman Khosravani
0
0
This study assesses deep learning models for audio classification in a clinical setting with the constraint of small datasets reflecting real-world prospective data collection. We analyze CNNs, including DenseNet and ConvNeXt, alongside transformer models like ViT, SWIN, and AST, and compare them against pre-trained audio models such as YAMNet and VGGish. Our method highlights the benefits of pre-training on large datasets before fine-tuning on specific clinical data. We prospectively collected two first-of-their-kind patient audio datasets from stroke patients. We investigated various preprocessing techniques, finding that RGB and grayscale spectrogram transformations affect model performance differently based on the priors they learn from pre-training. Our findings indicate CNNs can match or exceed transformer models in small dataset contexts, with DenseNet-Contrastive and AST models showing notable performance. This study highlights the significance of incremental marginal gains through model selection, pre-training, and preprocessing in sound classification; this offers valuable insights for clinical diagnostics that rely on audio classification.
4/9/2024