An Effective Automated Speaking Assessment Approach to Mitigating Data Scarcity and Imbalanced Distribution
2404.07575
0
0
📊
Abstract
Automated speaking assessment (ASA) typically involves automatic speech recognition (ASR) and hand-crafted feature extraction from the ASR transcript of a learner's speech. Recently, self-supervised learning (SSL) has shown stellar performance compared to traditional methods. However, SSL-based ASA systems are faced with at least three data-related challenges: limited annotated data, uneven distribution of learner proficiency levels and non-uniform score intervals between different CEFR proficiency levels. To address these challenges, we explore the use of two novel modeling strategies: metric-based classification and loss reweighting, leveraging distinct SSL-based embedding features. Extensive experimental results on the ICNALE benchmark dataset suggest that our approach can outperform existing strong baselines by a sizable margin, achieving a significant improvement of more than 10% in CEFR prediction accuracy.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Automated speaking assessment (ASA) typically uses automatic speech recognition (ASR) and manually crafted features from the ASR transcript to evaluate learner speech.
- Recent advances in self-supervised learning (SSL) have shown promising results compared to traditional methods.
- However, SSL-based ASA systems face three key challenges related to data: limited annotated data, uneven distribution of learner proficiency levels, and non-uniform score intervals between CEFR proficiency levels.
- To address these challenges, the paper explores two novel modeling strategies: metric-based classification and loss reweighting, leveraging distinct SSL-based embedding features.
- Extensive experiments on the ICNALE benchmark dataset suggest the proposed approach can outperform existing baselines by a significant margin, achieving over 10% improvement in CEFR prediction accuracy.
Plain English Explanation
Automated speaking assessment (ASA) is a technique used to evaluate how well someone speaks a language. Traditionally, this involves using automatic speech recognition (ASR) to convert the speaker's audio into text, and then analyzing the text to extract features that indicate their proficiency.
Recently, a new approach called self-supervised learning (SSL) has shown promising results for ASA. SSL can learn useful features from speech data without requiring extensive manual labeling. However, SSL-based ASA systems face some challenges:
- There is often limited data available that has been manually labeled for ASA.
- The data may not be evenly distributed, with more samples for some proficiency levels than others.
- The gaps between different proficiency levels (like beginner, intermediate, and advanced) may not be equal.
To address these issues, the researchers in this paper tried two new techniques:
- Metric-based classification: Using SSL to extract features that can be used to classify the speaker's proficiency level, similar to how people recognize different styles of speech.
- Loss reweighting: Adjusting the training process to pay more attention to underrepresented proficiency levels, so the model learns to predict them better.
The researchers tested these techniques on a benchmark dataset for ASA, and found that their approach could outperform existing methods by a significant amount, improving the accuracy of predicting proficiency levels by over 10%.
Technical Explanation
The paper explores two novel modeling strategies to address the data-related challenges faced by self-supervised learning (SSL)-based Automated Speaking Assessment (ASA) systems:
-
Metric-based Classification: Instead of relying on traditional classification architectures, the authors propose a metric-based approach that learns discriminative SSL-based embedding features. This allows the model to better capture the nuanced differences in proficiency levels.
-
Loss Reweighting: To handle the uneven distribution of learner proficiency levels and non-uniform score intervals between CEFR levels, the authors introduce a loss reweighting scheme. This dynamically adjusts the contribution of each sample during training, giving more emphasis to underrepresented proficiency levels.
The authors evaluate their approach on the ICNALE benchmark dataset for ASA. Their extensive experiments show that the proposed strategies, when combined with SSL-based features, can outperform existing strong baselines by a significant margin, achieving over 10% improvement in CEFR prediction accuracy.
Critical Analysis
The paper presents a compelling approach to address the data-related challenges faced by SSL-based Automated Speaking Assessment (ASA) systems. The authors' use of metric-based classification and loss reweighting techniques is a novel and promising direction.
However, the paper does not provide a deeper analysis of the limitations of their approach. For example, it would be interesting to understand how the proposed methods perform on different types of speech data (e.g., non-native speech, pathological speech, or speech with diacritics). Additionally, the authors could explore the interpretability of the learned SSL-based features and their relationship to traditional ASA features.
Further research is needed to fully understand the generalizability and robustness of the proposed techniques, as well as their potential impact on real-world ASA applications.
Conclusion
This paper presents an innovative approach to address the data-related challenges faced by self-supervised learning (SSL)-based Automated Speaking Assessment (ASA) systems. By introducing metric-based classification and loss reweighting strategies, the authors demonstrate significant improvements in CEFR proficiency level prediction accuracy compared to existing baselines.
The proposed methods show promise in leveraging the power of SSL to overcome limitations in annotated data, uneven proficiency distributions, and non-uniform score intervals. As the demand for robust and scalable ASA solutions continues to grow, this research represents an important step forward in the field.
Further exploration of the technique's generalizability, interpretability, and real-world impact could lead to valuable insights and advancements in language learning and assessment technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Exploring Pathological Speech Quality Assessment with ASR-Powered Wav2Vec2 in Data-Scarce Context
Tuan Nguyen, Corinne Fredouille, Alain Ghio, Mathieu Balaguer, Virginie Woisard
0
0
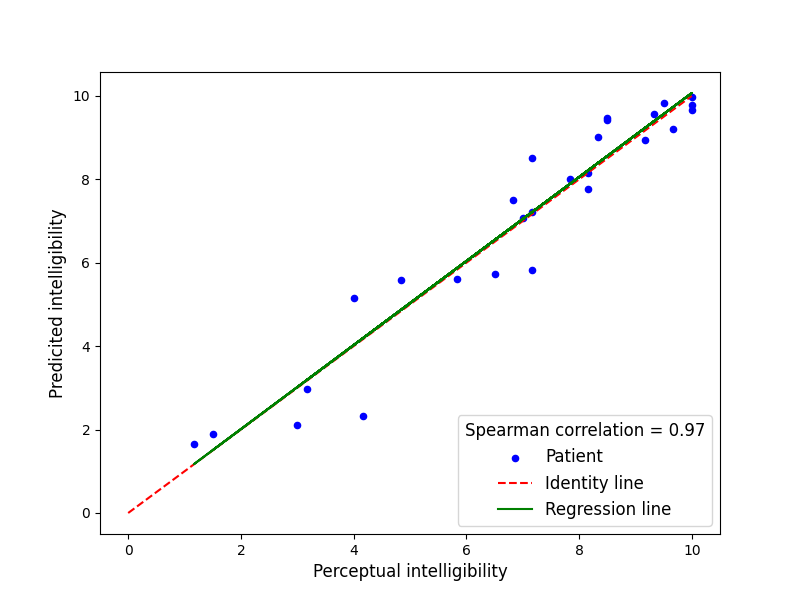
Automatic speech quality assessment has raised more attention as an alternative or support to traditional perceptual clinical evaluation. However, most research so far only gains good results on simple tasks such as binary classification, largely due to data scarcity. To deal with this challenge, current works tend to segment patients' audio files into many samples to augment the datasets. Nevertheless, this approach has limitations, as it indirectly relates overall audio scores to individual segments. This paper introduces a novel approach where the system learns at the audio level instead of segments despite data scarcity. This paper proposes to use the pre-trained Wav2Vec2 architecture for both SSL, and ASR as feature extractor in speech assessment. Carried out on the HNC dataset, our ASR-driven approach established a new baseline compared with other approaches, obtaining average $MSE=0.73$ and $MSE=1.15$ for the prediction of intelligibility and severity scores respectively, using only 95 training samples. It shows that the ASR based Wav2Vec2 model brings the best results and may indicate a strong correlation between ASR and speech quality assessment. We also measure its ability on variable segment durations and speech content, exploring factors influencing its decision.
4/1/2024
Lost in Transcription: Identifying and Quantifying the Accuracy Biases of Automatic Speech Recognition Systems Against Disfluent Speech
Dena Mujtaba, Nihar R. Mahapatra, Megan Arney, J. Scott Yaruss, Hope Gerlach-Houck, Caryn Herring, Jia Bin
0
0
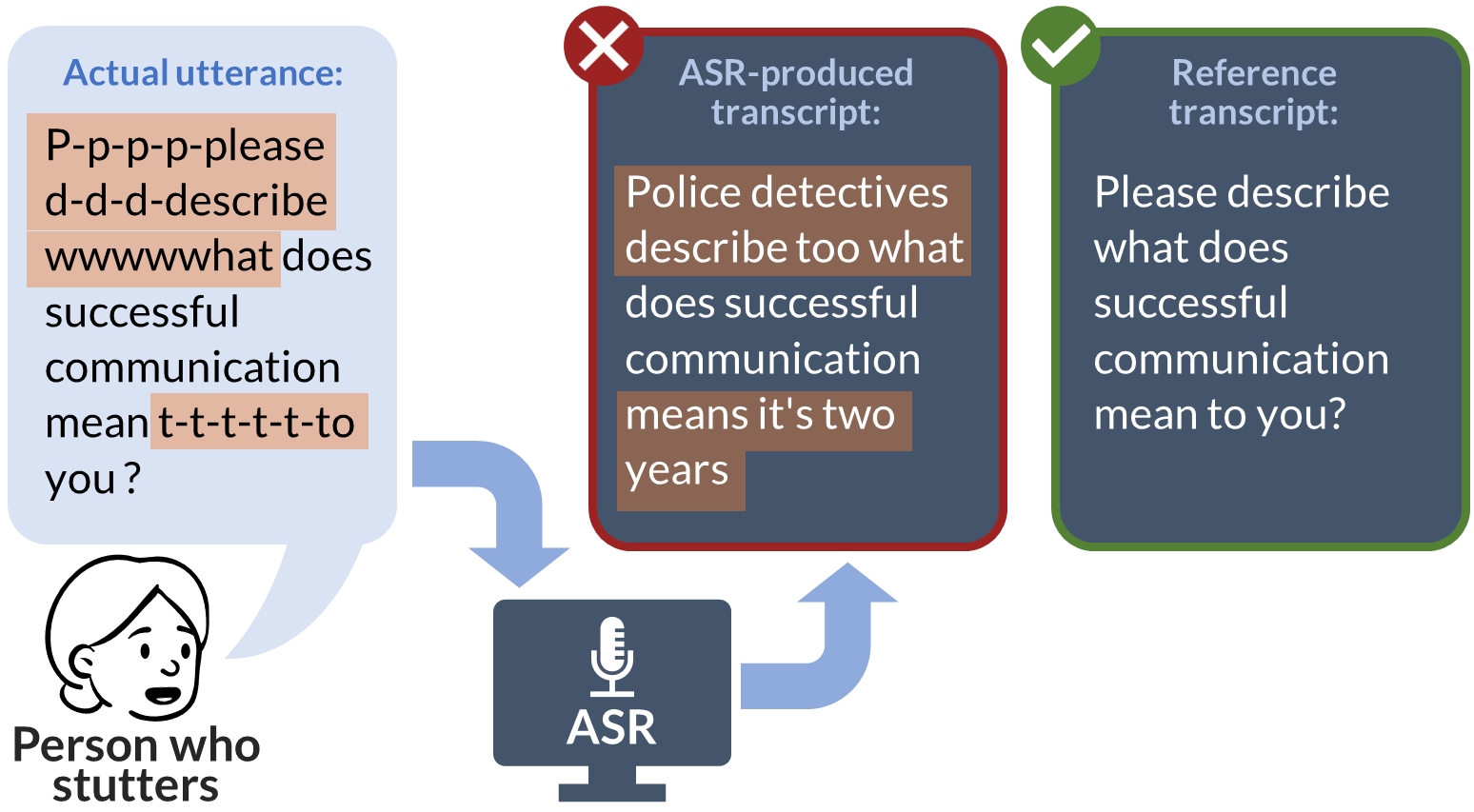
Automatic speech recognition (ASR) systems, increasingly prevalent in education, healthcare, employment, and mobile technology, face significant challenges in inclusivity, particularly for the 80 million-strong global community of people who stutter. These systems often fail to accurately interpret speech patterns deviating from typical fluency, leading to critical usability issues and misinterpretations. This study evaluates six leading ASRs, analyzing their performance on both a real-world dataset of speech samples from individuals who stutter and a synthetic dataset derived from the widely-used LibriSpeech benchmark. The synthetic dataset, uniquely designed to incorporate various stuttering events, enables an in-depth analysis of each ASR's handling of disfluent speech. Our comprehensive assessment includes metrics such as word error rate (WER), character error rate (CER), and semantic accuracy of the transcripts. The results reveal a consistent and statistically significant accuracy bias across all ASRs against disfluent speech, manifesting in significant syntactical and semantic inaccuracies in transcriptions. These findings highlight a critical gap in current ASR technologies, underscoring the need for effective bias mitigation strategies. Addressing this bias is imperative not only to improve the technology's usability for people who stutter but also to ensure their equitable and inclusive participation in the rapidly evolving digital landscape.
5/13/2024

Efficient infusion of self-supervised representations in Automatic Speech Recognition
Darshan Prabhu, Sai Ganesh Mirishkar, Pankaj Wasnik
0
0
Self-supervised learned (SSL) models such as Wav2vec and HuBERT yield state-of-the-art results on speech-related tasks. Given the effectiveness of such models, it is advantageous to use them in conventional ASR systems. While some approaches suggest incorporating these models as a trainable encoder or a learnable frontend, training such systems is extremely slow and requires a lot of computation cycles. In this work, we propose two simple approaches that use (1) framewise addition and (2) cross-attention mechanisms to efficiently incorporate the representations from the SSL model(s) into the ASR architecture, resulting in models that are comparable in size with standard encoder-decoder conformer systems while also avoiding the usage of SSL models during training. Our approach results in faster training and yields significant performance gains on the Librispeech and Tedlium datasets compared to baselines. We further provide detailed analysis and ablation studies that demonstrate the effectiveness of our approach.
4/22/2024
Anatomy of Industrial Scale Multilingual ASR
Francis McCann Ramirez, Luka Chkhetiani, Andrew Ehrenberg, Robert McHardy, Rami Botros, Yash Khare, Andrea Vanzo, Taufiquzzaman Peyash, Gabriel Oexle, Michael Liang, Ilya Sklyar, Enver Fakhan, Ahmed Etefy, Daniel McCrystal, Sam Flamini, Domenic Donato, Takuya Yoshioka
0
0
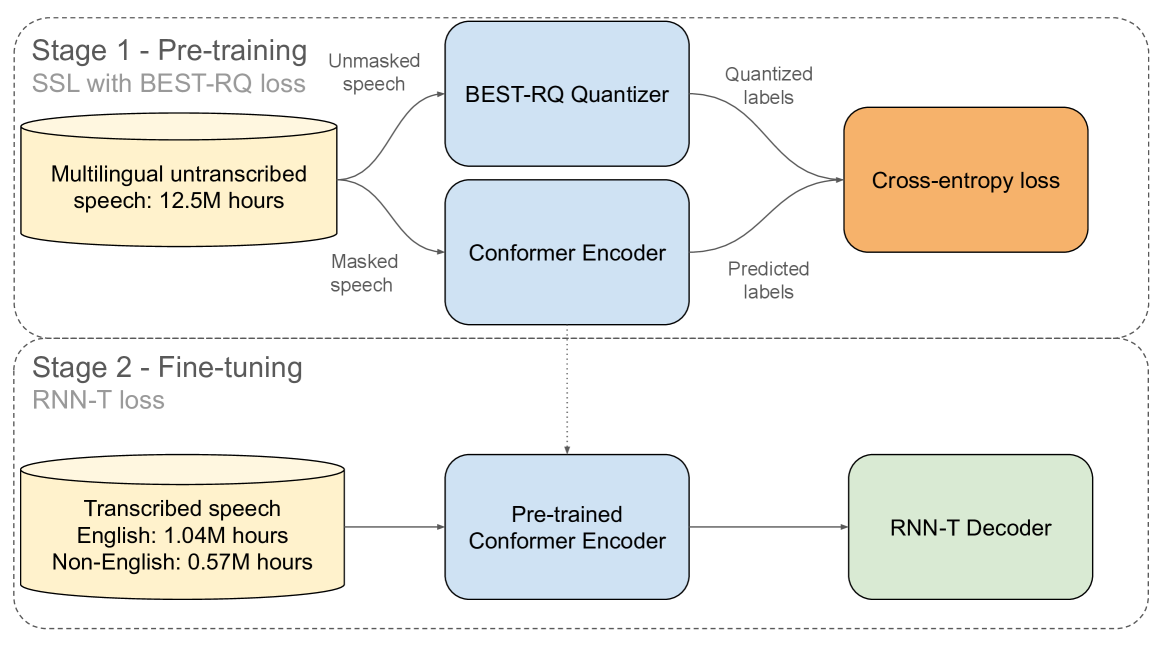
This paper describes AssemblyAI's industrial-scale automatic speech recognition (ASR) system, designed to meet the requirements of large-scale, multilingual ASR serving various application needs. Our system leverages a diverse training dataset comprising unsupervised (12.5M hours), supervised (188k hours), and pseudo-labeled (1.6M hours) data across four languages. We provide a detailed description of our model architecture, consisting of a full-context 600M-parameter Conformer encoder pre-trained with BEST-RQ and an RNN-T decoder fine-tuned jointly with the encoder. Our extensive evaluation demonstrates competitive word error rates (WERs) against larger and more computationally expensive models, such as Whisper large and Canary-1B. Furthermore, our architectural choices yield several key advantages, including an improved code-switching capability, a 5x inference speedup compared to an optimized Whisper baseline, a 30% reduction in hallucination rate on speech data, and a 90% reduction in ambient noise compared to Whisper, along with significantly improved time-stamp accuracy. Throughout this work, we adopt a system-centric approach to analyzing various aspects of fully-fledged ASR models to gain practically relevant insights useful for real-world services operating at scale.
4/17/2024