Exploring Spoken Language Identification Strategies for Automatic Transcription of Multilingual Broadcast and Institutional Speech

0
💬
Sign in to get full access
Overview
- The paper explores strategies for identifying spoken languages in multilingual broadcast and institutional speech to enable accurate automatic transcription.
- It examines various approaches to spoken language identification (SLI) and their impact on downstream automatic speech recognition (ASR) performance.
- The research aims to improve transcription accuracy for diverse, multilingual speech by effectively integrating SLI into the ASR pipeline.
Plain English Explanation
The research paper focuses on improving the ability of speech recognition systems to accurately transcribe multilingual speech, such as what might be found in broadcasts or institutional settings. A key challenge in these scenarios is accurately identifying which language is being spoken at any given time, as the speech can switch between multiple languages.
The paper explores different strategies for spoken language identification (SLI), which is the process of automatically detecting the language being spoken. By effectively integrating SLI into the speech recognition pipeline, the researchers aim to enhance the overall transcription accuracy for diverse, multilingual speech. This could have important applications in areas like media accessibility, government services, and educational resources, where accurate transcription of multilingual content is crucial.
Technical Explanation
The paper presents a system architecture that combines spoken language identification (SLI) and automatic speech recognition (ASR) to tackle the challenge of transcribing multilingual speech. The SLI component is responsible for detecting the language being spoken at any given time, while the ASR module then uses this information to select the appropriate language model for accurate transcription.
The researchers explore various SLI strategies, including language-dependent and language-independent approaches. They evaluate the performance of these SLI methods and their impact on the overall ASR accuracy, using a diverse dataset of multilingual speech from broadcast and institutional sources.
The paper provides insights into the tradeoffs between different SLI techniques and their suitability for specific scenarios. For example, language-dependent SLI may achieve higher accuracy but requires prior knowledge of the languages present, while language-independent approaches can be more flexible but may sacrifice some precision.
Critical Analysis
The paper acknowledges several limitations and areas for further research. For instance, the dataset used may not fully capture the diversity of multilingual speech encountered in real-world settings, and the researchers suggest expanding the evaluation to include a wider range of languages and speech domains.
Additionally, the paper notes that the performance of the SLI and ASR components can be interdependent, and there may be opportunities to further optimize their integration to improve overall transcription accuracy. Exploring more advanced techniques, such as joint modeling of SLI and ASR, could be an area for future research.
Conclusion
This research paper presents a comprehensive exploration of spoken language identification strategies and their impact on automatic transcription of multilingual speech. By effectively integrating SLI into the ASR pipeline, the researchers demonstrate the potential to enhance transcription accuracy for diverse, real-world speech scenarios.
The insights gained from this work could contribute to the development of more robust and inclusive speech recognition systems, with applications in areas such as media accessibility, public services, and educational resources. As the need for accurate transcription of multilingual content continues to grow, this research represents an important step towards addressing the challenges in this domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Exploring Spoken Language Identification Strategies for Automatic Transcription of Multilingual Broadcast and Institutional Speech
Martina Valente, Fabio Brugnara, Giovanni Morrone, Enrico Zovato, Leonardo Badino
This paper addresses spoken language identification (SLI) and speech recognition of multilingual broadcast and institutional speech, real application scenarios that have been rarely addressed in the SLI literature. Observing that in these domains language changes are mostly associated with speaker changes, we propose a cascaded system consisting of speaker diarization and language identification and compare it with more traditional language identification and language diarization systems. Results show that the proposed system often achieves lower language classification and language diarization error rates (up to 10% relative language diarization error reduction and 60% relative language confusion reduction) and leads to lower WERs on multilingual test sets (more than 8% relative WER reduction), while at the same time does not negatively affect speech recognition on monolingual audio (with an absolute WER increase between 0.1% and 0.7% w.r.t. monolingual ASR).
Read more6/14/2024
0
Specific language impairment (SLI) detection pipeline from transcriptions of spontaneous narratives
Santiago Arena, Antonio Quintero-Rinc'on
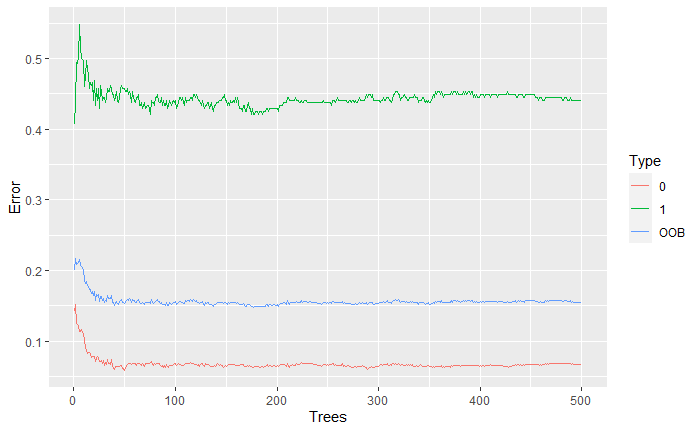
Specific Language Impairment (SLI) is a disorder that affects communication and can affect both comprehension and expression. This study focuses on effectively detecting SLI in children using transcripts of spontaneous narratives from 1063 interviews. A three-stage cascading pipeline was proposed f. In the first stage, feature extraction and dimensionality reduction of the data are performed using the Random Forest (RF) and Spearman correlation methods. In the second stage, the most predictive variables from the first stage are estimated using logistic regression, which is used in the last stage to detect SLI in children from transcripts of spontaneous narratives using a nearest neighbor classifier. The results revealed an accuracy of 97.13% in identifying SLI, highlighting aspects such as the length of the responses, the quality of their utterances, and the complexity of the language. This new approach, framed in natural language processing, offers significant benefits to the field of SLI detection by avoiding complex subjective variables and focusing on quantitative metrics directly related to the child's performance.
Read more7/18/2024
0
Anatomy of Industrial Scale Multilingual ASR
Francis McCann Ramirez, Luka Chkhetiani, Andrew Ehrenberg, Robert McHardy, Rami Botros, Yash Khare, Andrea Vanzo, Taufiquzzaman Peyash, Gabriel Oexle, Michael Liang, Ilya Sklyar, Enver Fakhan, Ahmed Etefy, Daniel McCrystal, Sam Flamini, Domenic Donato, Takuya Yoshioka
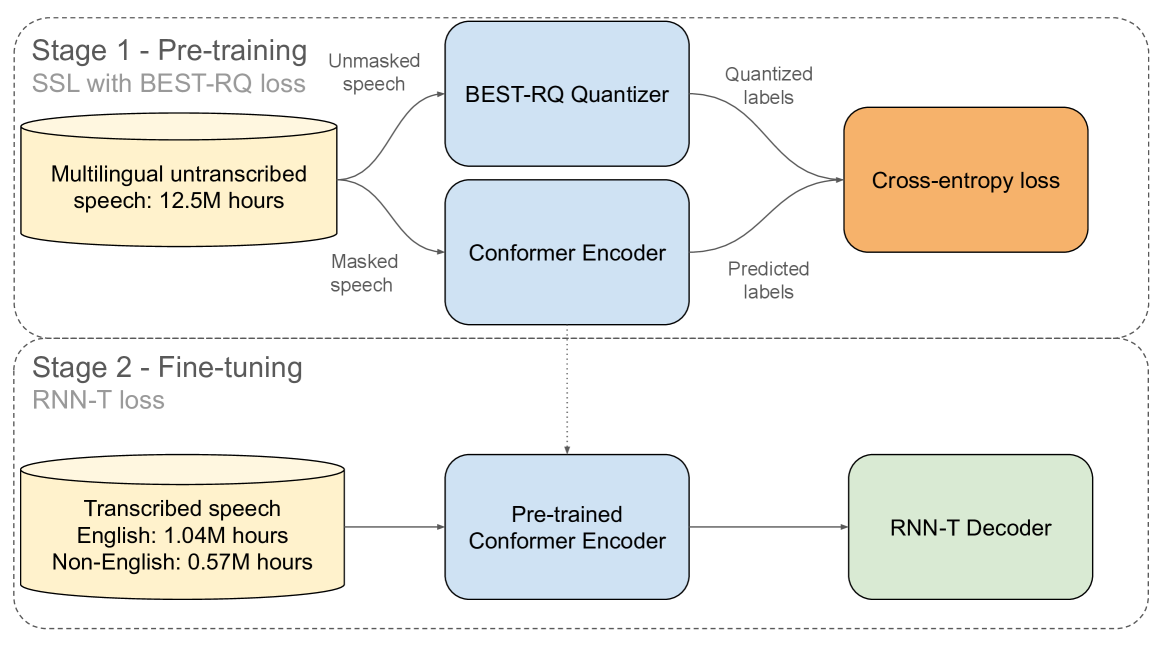
This paper describes AssemblyAI's industrial-scale automatic speech recognition (ASR) system, designed to meet the requirements of large-scale, multilingual ASR serving various application needs. Our system leverages a diverse training dataset comprising unsupervised (12.5M hours), supervised (188k hours), and pseudo-labeled (1.6M hours) data across four languages. We provide a detailed description of our model architecture, consisting of a full-context 600M-parameter Conformer encoder pre-trained with BEST-RQ and an RNN-T decoder fine-tuned jointly with the encoder. Our extensive evaluation demonstrates competitive word error rates (WERs) against larger and more computationally expensive models, such as Whisper large and Canary-1B. Furthermore, our architectural choices yield several key advantages, including an improved code-switching capability, a 5x inference speedup compared to an optimized Whisper baseline, a 30% reduction in hallucination rate on speech data, and a 90% reduction in ambient noise compared to Whisper, along with significantly improved time-stamp accuracy. Throughout this work, we adopt a system-centric approach to analyzing various aspects of fully-fledged ASR models to gain practically relevant insights useful for real-world services operating at scale.
Read more4/17/2024
0
Lost in Transcription: Identifying and Quantifying the Accuracy Biases of Automatic Speech Recognition Systems Against Disfluent Speech
Dena Mujtaba, Nihar R. Mahapatra, Megan Arney, J. Scott Yaruss, Hope Gerlach-Houck, Caryn Herring, Jia Bin
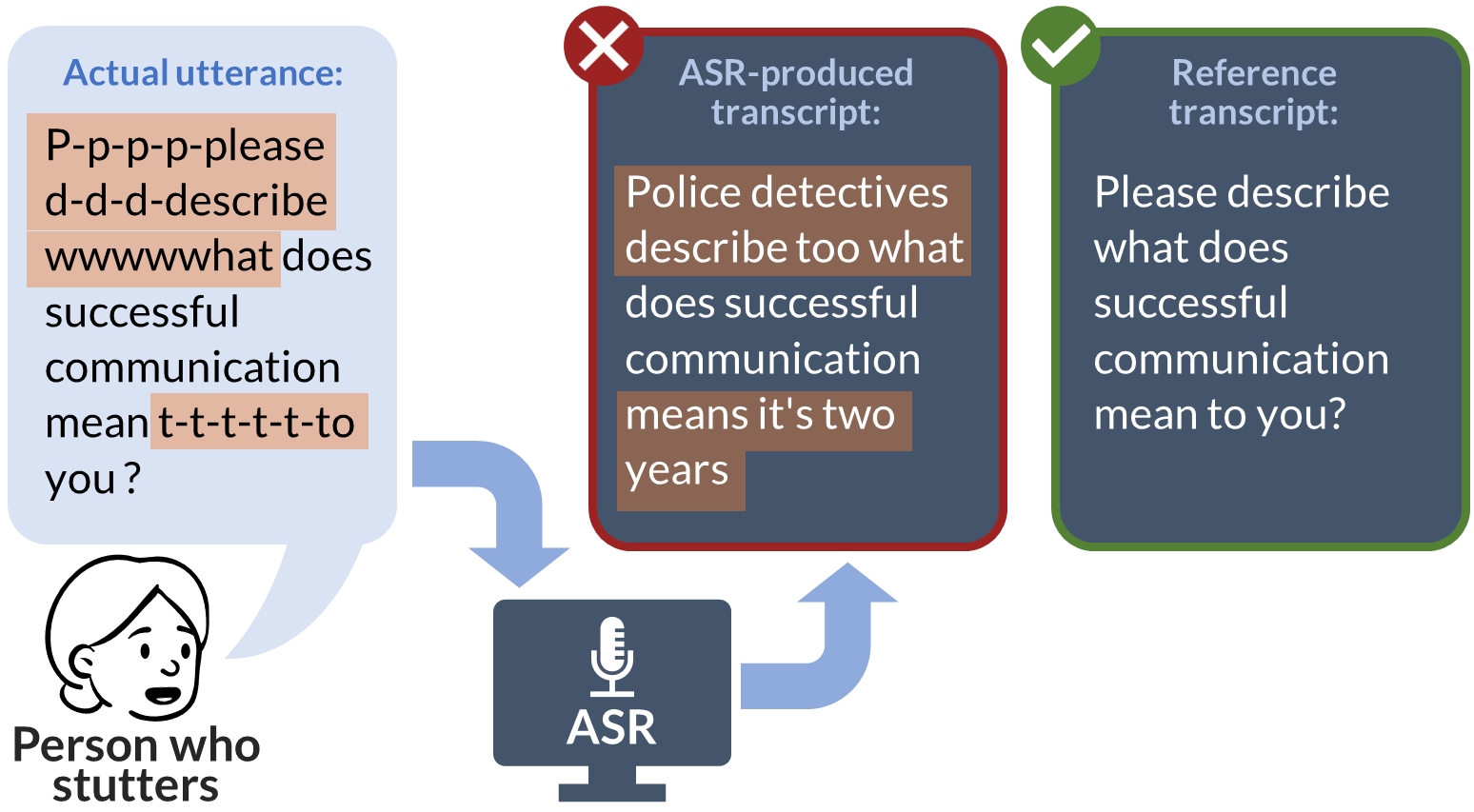
Automatic speech recognition (ASR) systems, increasingly prevalent in education, healthcare, employment, and mobile technology, face significant challenges in inclusivity, particularly for the 80 million-strong global community of people who stutter. These systems often fail to accurately interpret speech patterns deviating from typical fluency, leading to critical usability issues and misinterpretations. This study evaluates six leading ASRs, analyzing their performance on both a real-world dataset of speech samples from individuals who stutter and a synthetic dataset derived from the widely-used LibriSpeech benchmark. The synthetic dataset, uniquely designed to incorporate various stuttering events, enables an in-depth analysis of each ASR's handling of disfluent speech. Our comprehensive assessment includes metrics such as word error rate (WER), character error rate (CER), and semantic accuracy of the transcripts. The results reveal a consistent and statistically significant accuracy bias across all ASRs against disfluent speech, manifesting in significant syntactical and semantic inaccuracies in transcriptions. These findings highlight a critical gap in current ASR technologies, underscoring the need for effective bias mitigation strategies. Addressing this bias is imperative not only to improve the technology's usability for people who stutter but also to ensure their equitable and inclusive participation in the rapidly evolving digital landscape.
Read more5/13/2024