Exposing Text-Image Inconsistency Using Diffusion Models
2404.18033
0
1
Abstract
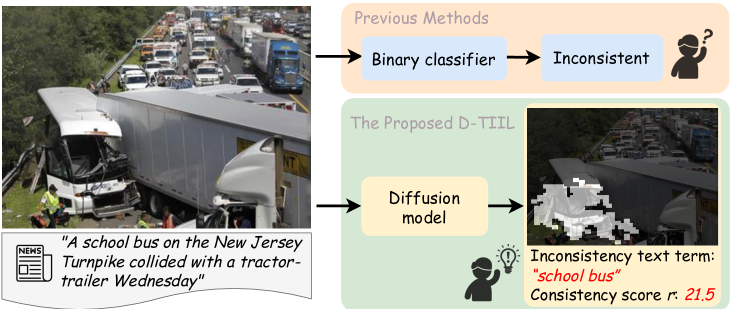
In the battle against widespread online misinformation, a growing problem is text-image inconsistency, where images are misleadingly paired with texts with different intent or meaning. Existing classification-based methods for text-image inconsistency can identify contextual inconsistencies but fail to provide explainable justifications for their decisions that humans can understand. Although more nuanced, human evaluation is impractical at scale and susceptible to errors. To address these limitations, this study introduces D-TIIL (Diffusion-based Text-Image Inconsistency Localization), which employs text-to-image diffusion models to localize semantic inconsistencies in text and image pairs. These models, trained on large-scale datasets act as ``omniscient agents that filter out irrelevant information and incorporate background knowledge to identify inconsistencies. In addition, D-TIIL uses text embeddings and modified image regions to visualize these inconsistencies. To evaluate D-TIIL's efficacy, we introduce a new TIIL dataset containing 14K consistent and inconsistent text-image pairs. Unlike existing datasets, TIIL enables assessment at the level of individual words and image regions and is carefully designed to represent various inconsistencies. D-TIIL offers a scalable and evidence-based approach to identifying and localizing text-image inconsistency, providing a robust framework for future research combating misinformation.
Create account to get full access
Overview
- This paper explores the use of diffusion models to identify inconsistencies between text and images in generated content.
- Diffusion models are a type of generative AI that can be used to create new images or text by gradually adding noise to an input and then reversing the process.
- The researchers propose a method to leverage diffusion models to detect when the text and image in a generated sample are inconsistent or contradictory.
Plain English Explanation
The paper looks at a problem with AI systems that generate both text and images - sometimes the text and image don't match up or make sense together. The researchers used a type of AI called a "diffusion model" to try and detect when the text and image in a generated sample don't go together.
Diffusion models work by taking an image or text and slowly adding "noise" or random data to it, then trying to reverse that process and reconstruct the original. The researchers found that by training the diffusion model on both the text and image, they could identify cases where the text and image didn't seem to match up, even if the individual text or image looked realistic on its own.
This could be useful for catching mistakes or inconsistencies in AI-generated content, like an image that doesn't match the description or caption. By being able to spot these problems, developers could improve the quality and coherence of the content these AI systems produce.
Technical Explanation
The paper proposes a method to [object Object]. The key idea is to leverage the joint modeling capability of diffusion models to capture the relationship between text and images.
Specifically, the researchers train a conditional diffusion model on a dataset of text-image pairs. This model learns to generate images conditioned on the corresponding text description. During inference, the researchers can then use this model to detect inconsistencies between the text and the generated image.
The intuition is that if the text and image are consistent, the diffusion model should be able to generate the image given the text with high fidelity. However, if there is an inconsistency, the generated image will not match the text, and this mismatch can be quantified.
The paper demonstrates the effectiveness of this approach through experiments on various datasets, including [object Object], and [object Object]. The results show that the proposed method can reliably detect text-image inconsistencies across different domains and datasets.
Critical Analysis
The paper presents a novel and interesting approach to detecting text-image inconsistencies using diffusion models. The key strength of the method is its ability to capture the joint distribution of text and images, which allows it to identify mismatches that may not be apparent from the individual modalities alone.
However, the paper does not fully address the potential limitations of this approach. For example, the researchers do not discuss how the method would perform in the presence of more subtle or complex inconsistencies, such as when the text and image convey different emotional or semantic meanings, but are not directly contradictory.
Additionally, the paper does not explore the potential for adversarial attacks, where an adversary could intentionally create inconsistent text-image pairs to bypass the detection system. This is an important consideration, as real-world deployments of such a system would need to be robust to such attacks.
Overall, the paper makes a valuable contribution by demonstrating the potential of diffusion models for text-image consistency verification. However, further research is needed to fully understand the capabilities and limitations of this approach, particularly in more challenging and adversarial settings.
Conclusion
This paper presents a novel approach to detecting inconsistencies between text and images in AI-generated content using diffusion models. The key innovation is the use of a joint text-image diffusion model to capture the relationship between the two modalities, enabling the identification of samples where the text and image do not match.
The results show that this method can effectively detect text-image inconsistencies across different datasets, which has important implications for improving the coherence and reliability of AI-generated content. While the paper does not fully address the potential limitations of the approach, it demonstrates the power of diffusion models for multimodal tasks and opens up new avenues for research in this area.
As AI systems become more capable of generating realistic text and images, the ability to verify the consistency and coherence of this output will be increasingly important. The work presented in this paper represents an important step towards that goal, and suggests that diffusion models may be a promising tool for tackling this challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Enhancing Text-to-Image Editing via Hybrid Mask-Informed Fusion
Aoxue Li, Mingyang Yi, Zhenguo Li
0
0
Recently, text-to-image (T2I) editing has been greatly pushed forward by applying diffusion models. Despite the visual promise of the generated images, inconsistencies with the expected textual prompt remain prevalent. This paper aims to systematically improve the text-guided image editing techniques based on diffusion models, by addressing their limitations. Notably, the common idea in diffusion-based editing firstly reconstructs the source image via inversion techniques e.g., DDIM Inversion. Then following a fusion process that carefully integrates the source intermediate (hidden) states (obtained by inversion) with the ones of the target image. Unfortunately, such a standard pipeline fails in many cases due to the interference of texture retention and the new characters creation in some regions. To mitigate this, we incorporate human annotation as an external knowledge to confine editing within a ``Mask-informed'' region. Then we carefully Fuse the edited image with the source image and a constructed intermediate image within the model's Self-Attention module. Extensive empirical results demonstrate the proposed ``MaSaFusion'' significantly improves the existing T2I editing techniques.
5/27/2024

Invertible Consistency Distillation for Text-Guided Image Editing in Around 7 Steps
Nikita Starodubcev, Mikhail Khoroshikh, Artem Babenko, Dmitry Baranchuk
0
0
Diffusion distillation represents a highly promising direction for achieving faithful text-to-image generation in a few sampling steps. However, despite recent successes, existing distilled models still do not provide the full spectrum of diffusion abilities, such as real image inversion, which enables many precise image manipulation methods. This work aims to enrich distilled text-to-image diffusion models with the ability to effectively encode real images into their latent space. To this end, we introduce invertible Consistency Distillation (iCD), a generalized consistency distillation framework that facilitates both high-quality image synthesis and accurate image encoding in only 3-4 inference steps. Though the inversion problem for text-to-image diffusion models gets exacerbated by high classifier-free guidance scales, we notice that dynamic guidance significantly reduces reconstruction errors without noticeable degradation in generation performance. As a result, we demonstrate that iCD equipped with dynamic guidance may serve as a highly effective tool for zero-shot text-guided image editing, competing with more expensive state-of-the-art alternatives.
6/27/2024

Information Theoretic Text-to-Image Alignment
Chao Wang, Giulio Franzese, Alessandro Finamore, Massimo Gallo, Pietro Michiardi
0
0
Diffusion models for Text-to-Image (T2I) conditional generation have seen tremendous success recently. Despite their success, accurately capturing user intentions with these models still requires a laborious trial and error process. This challenge is commonly identified as a model alignment problem, an issue that has attracted considerable attention by the research community. Instead of relying on fine-grained linguistic analyses of prompts, human annotation, or auxiliary vision-language models to steer image generation, in this work we present a novel method that relies on an information-theoretic alignment measure. In a nutshell, our method uses self-supervised fine-tuning and relies on point-wise mutual information between prompts and images to define a synthetic training set to induce model alignment. Our comparative analysis shows that our method is on-par or superior to the state-of-the-art, yet requires nothing but a pre-trained denoising network to estimate MI and a lightweight fine-tuning strategy.
6/3/2024

A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models
Xincheng Shuai, Henghui Ding, Xingjun Ma, Rongcheng Tu, Yu-Gang Jiang, Dacheng Tao
0
0
Image editing aims to edit the given synthetic or real image to meet the specific requirements from users. It is widely studied in recent years as a promising and challenging field of Artificial Intelligence Generative Content (AIGC). Recent significant advancement in this field is based on the development of text-to-image (T2I) diffusion models, which generate images according to text prompts. These models demonstrate remarkable generative capabilities and have become widely used tools for image editing. T2I-based image editing methods significantly enhance editing performance and offer a user-friendly interface for modifying content guided by multimodal inputs. In this survey, we provide a comprehensive review of multimodal-guided image editing techniques that leverage T2I diffusion models. First, we define the scope of image editing from a holistic perspective and detail various control signals and editing scenarios. We then propose a unified framework to formalize the editing process, categorizing it into two primary algorithm families. This framework offers a design space for users to achieve specific goals. Subsequently, we present an in-depth analysis of each component within this framework, examining the characteristics and applicable scenarios of different combinations. Given that training-based methods learn to directly map the source image to target one under user guidance, we discuss them separately, and introduce injection schemes of source image in different scenarios. Additionally, we review the application of 2D techniques to video editing, highlighting solutions for inter-frame inconsistency. Finally, we discuss open challenges in the field and suggest potential future research directions. We keep tracing related works at https://github.com/xinchengshuai/Awesome-Image-Editing.
6/21/2024