Face Forgery Detection with Elaborate Backbone

0

Sign in to get full access
Overview
- This paper proposes a new face forgery detection method using an elaborate backbone architecture.
- The method aims to improve upon existing deepfake and presentation attack detection approaches.
- Key contributions include a Vision Transformer-based backbone and self-supervised pre-training.
Plain English Explanation
The research paper introduces a new technique for detecting face forgery, which is the process of creating fake or altered facial images, often referred to as "deepfakes." The proposed method uses an advanced Vision Transformer architecture as its backbone, along with a self-supervised learning approach to improve the model's performance.
The key idea is to develop a more powerful and robust detection system that can better identify manipulated or synthetic facial images compared to existing techniques. This is an important problem to solve, as deepfake technology has the potential to be misused for malicious purposes, such as creating false information or impersonating individuals.
Technical Explanation
The paper introduces a new face forgery detection model that uses an elaborate backbone architecture. The backbone is based on a Vision Transformer, which is a type of deep learning model that has shown promising results in various computer vision tasks.
The authors also employ a self-supervised learning approach to pre-train the model, which means the model learns useful features from the data without the need for manual labeling. This helps the model learn more generalized and transferable representations, which can then be fine-tuned for the specific task of face forgery detection.
The paper evaluates the proposed method on several benchmark datasets for deepfake and presentation attack detection, and the results demonstrate improved performance compared to existing state-of-the-art approaches.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed face forgery detection method. The authors acknowledge the limitations of their approach, such as the potential for the model to be biased towards certain types of forgeries or the need for further investigation into the interpretability of the learned representations.
Additionally, the authors suggest that future work could explore the use of mixture-of-experts or generalized parameter-efficient approaches to further improve the model's performance and robustness.
Overall, the paper provides a valuable contribution to the field of face forgery detection and lays the groundwork for future research in this important area.
Conclusion
This research paper introduces a novel face forgery detection method that leverages an elaborate Vision Transformer backbone and self-supervised learning techniques. The proposed approach demonstrates improved performance over existing state-of-the-art methods, highlighting the potential of advanced deep learning architectures and unsupervised pre-training for tackling the challenge of detecting manipulated facial images. The paper's insights and future research directions provide a valuable contribution to the ongoing efforts to combat the growing threat of deepfake and other face forgery techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Face Forgery Detection with Elaborate Backbone
Zonghui Guo, Yingjie Liu, Jie Zhang, Haiyong Zheng, Shiguang Shan
Face Forgery Detection (FFD), or Deepfake detection, aims to determine whether a digital face is real or fake. Due to different face synthesis algorithms with diverse forgery patterns, FFD models often overfit specific patterns in training datasets, resulting in poor generalization to other unseen forgeries. This severe challenge requires FFD models to possess strong capabilities in representing complex facial features and extracting subtle forgery cues. Although previous FFD models directly employ existing backbones to represent and extract facial forgery cues, the critical role of backbones is often overlooked, particularly as their knowledge and capabilities are insufficient to address FFD challenges, inevitably limiting generalization. Therefore, it is essential to integrate the backbone pre-training configurations and seek practical solutions by revisiting the complete FFD workflow, from backbone pre-training and fine-tuning to inference of discriminant results. Specifically, we analyze the crucial contributions of backbones with different configurations in FFD task and propose leveraging the ViT network with self-supervised learning on real-face datasets to pre-train a backbone, equipping it with superior facial representation capabilities. We then build a competitive backbone fine-tuning framework that strengthens the backbone's ability to extract diverse forgery cues within a competitive learning mechanism. Moreover, we devise a threshold optimization mechanism that utilizes prediction confidence to improve the inference reliability. Comprehensive experiments demonstrate that our FFD model with the elaborate backbone achieves excellent performance in FFD and extra face-related tasks, i.e., presentation attack detection. Code and models are available at https://github.com/zhenglab/FFDBackbone.
Read more9/26/2024

0
MoE-FFD: Mixture of Experts for Generalized and Parameter-Efficient Face Forgery Detection
Chenqi Kong, Anwei Luo, Peijun Bao, Yi Yu, Haoliang Li, Zengwei Zheng, Shiqi Wang, Alex C. Kot
Deepfakes have recently raised significant trust issues and security concerns among the public. Compared to CNN face forgery detectors, ViT-based methods take advantage of the expressivity of transformers, achieving superior detection performance. However, these approaches still exhibit the following limitations: (1) Fully fine-tuning ViT-based models from ImageNet weights demands substantial computational and storage resources; (2) ViT-based methods struggle to capture local forgery clues, leading to model bias; (3) These methods limit their scope on only one or few face forgery features, resulting in limited generalizability. To tackle these challenges, this work introduces Mixture-of-Experts modules for Face Forgery Detection (MoE-FFD), a generalized yet parameter-efficient ViT-based approach. MoE-FFD only updates lightweight Low-Rank Adaptation (LoRA) and Adapter layers while keeping the ViT backbone frozen, thereby achieving parameter-efficient training. Moreover, MoE-FFD leverages the expressivity of transformers and local priors of CNNs to simultaneously extract global and local forgery clues. Additionally, novel MoE modules are designed to scale the model's capacity and smartly select optimal forgery experts, further enhancing forgery detection performance. Our proposed learning scheme can be seamlessly adapted to various transformer backbones in a plug-and-play manner. Extensive experimental results demonstrate that the proposed method achieves state-of-the-art face forgery detection performance with significantly reduced parameter overhead. The code is released at: https://github.com/LoveSiameseCat/MoE-FFD.
Read more6/11/2024
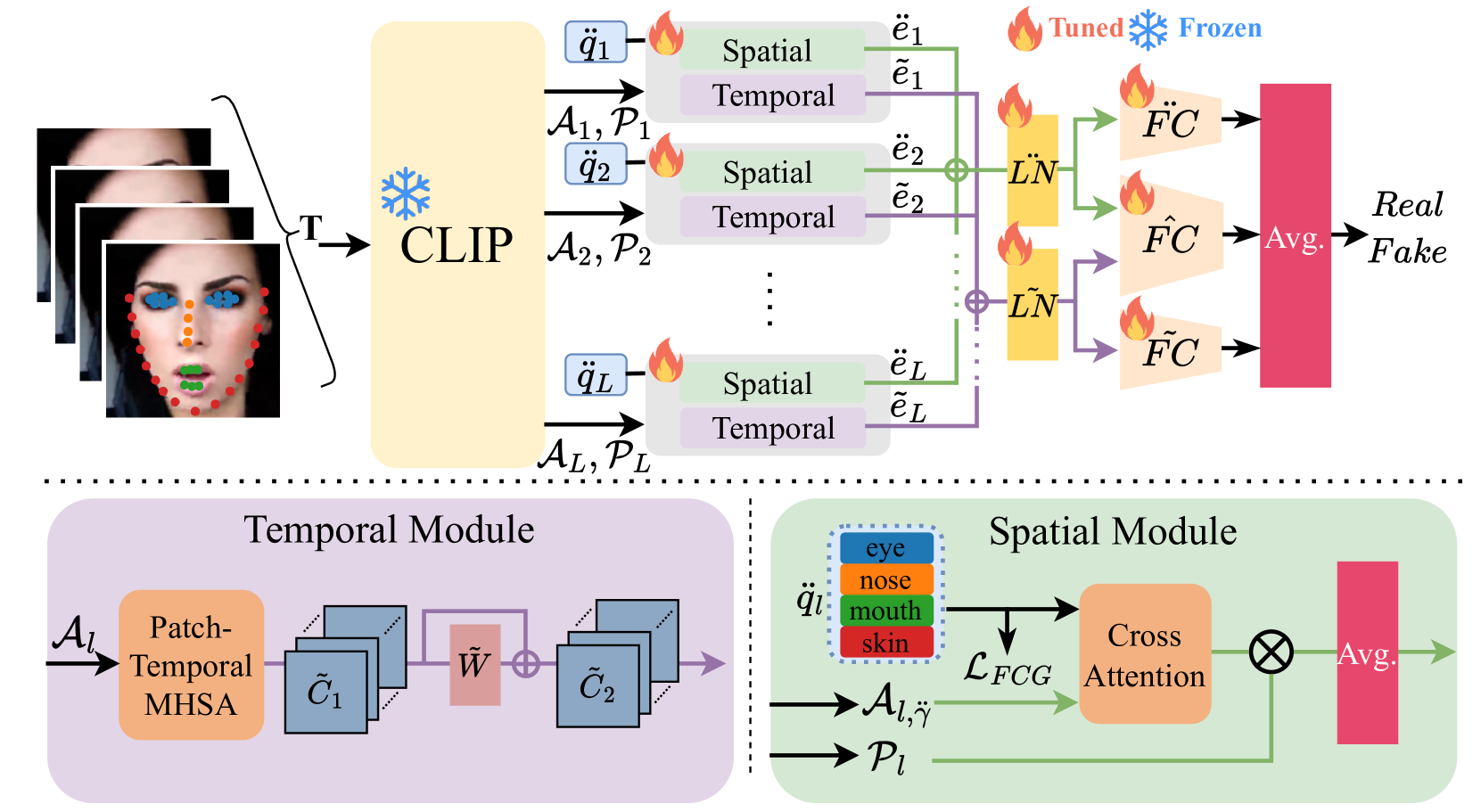
0
Towards More General Video-based Deepfake Detection through Facial Feature Guided Adaptation for Foundation Model
Yue-Hua Han, Tai-Ming Huang, Shu-Tzu Lo, Po-Han Huang, Kai-Lung Hua, Jun-Cheng Chen
With the rise of deep learning, generative models have enabled the creation of highly realistic synthetic images, presenting challenges due to their potential misuse. While research in Deepfake detection has grown rapidly in response, many detection methods struggle with unseen Deepfakes generated by new synthesis techniques. To address this generalisation challenge, we propose a novel Deepfake detection approach by adapting the Foundation Models with rich information encoded inside, specifically using the image encoder from CLIP which has demonstrated strong zero-shot capability for downstream tasks. Inspired by the recent advances of parameter efficient fine-tuning, we propose a novel side-network-based decoder to extract spatial and temporal cues from the given video clip, with the promotion of the Facial Component Guidance (FCG) to encourage the spatial feature to include features of key facial parts for more robust and general Deepfake detection. Through extensive cross-dataset evaluations, our approach exhibits superior effectiveness in identifying unseen Deepfake samples, achieving notable performance improvement even with limited training samples and manipulation types. Our model secures an average performance enhancement of 0.9% AUROC in cross-dataset assessments comparing with state-of-the-art methods, especially a significant lead of achieving 4.4% improvement on the challenging DFDC dataset.
Read more6/6/2024

0
UniForensics: Face Forgery Detection via General Facial Representation
Ziyuan Fang, Hanqing Zhao, Tianyi Wei, Wenbo Zhou, Ming Wan, Zhanyi Wang, Weiming Zhang, Nenghai Yu
Previous deepfake detection methods mostly depend on low-level textural features vulnerable to perturbations and fall short of detecting unseen forgery methods. In contrast, high-level semantic features are less susceptible to perturbations and not limited to forgery-specific artifacts, thus having stronger generalization. Motivated by this, we propose a detection method that utilizes high-level semantic features of faces to identify inconsistencies in temporal domain. We introduce UniForensics, a novel deepfake detection framework that leverages a transformer-based video classification network, initialized with a meta-functional face encoder for enriched facial representation. In this way, we can take advantage of both the powerful spatio-temporal model and the high-level semantic information of faces. Furthermore, to leverage easily accessible real face data and guide the model in focusing on spatio-temporal features, we design a Dynamic Video Self-Blending (DVSB) method to efficiently generate training samples with diverse spatio-temporal forgery traces using real facial videos. Based on this, we advance our framework with a two-stage training approach: The first stage employs a novel self-supervised contrastive learning, where we encourage the network to focus on forgery traces by impelling videos generated by the same forgery process to have similar representations. On the basis of the representation learned in the first stage, the second stage involves fine-tuning on face forgery detection dataset to build a deepfake detector. Extensive experiments validates that UniForensics outperforms existing face forgery methods in generalization ability and robustness. In particular, our method achieves 95.3% and 77.2% cross dataset AUC on the challenging Celeb-DFv2 and DFDC respectively.
Read more7/30/2024