Facial Affect Recognition based on Multi Architecture Encoder and Feature Fusion for the ABAW7 Challenge

0

Sign in to get full access
Overview
- This paper presents a facial affect recognition system for the ABAW7 Challenge, which aims to recognize emotions and facial expressions from facial images.
- The system uses a multi-architecture encoder and feature fusion approach to improve the recognition performance.
- The paper explores various deep learning models and techniques to build an effective facial affect recognition system.
Plain English Explanation
The paper describes a method for recognizing emotions and facial expressions from images of people's faces. This is an important task in the field of computer vision and artificial intelligence, with applications in areas like human-computer interaction, mental health, and social robotics.
The key idea behind the proposed system is to use multiple deep learning models, each with a different architecture, to extract different types of features from the facial images. These features are then combined or "fused" to get a more comprehensive understanding of the facial expressions. This multi-architecture and feature fusion approach is designed to outperform single-model systems, as it can capture a wider range of facial characteristics and their interactions.
The authors tested their system on the ABAW7 Challenge, a widely used benchmark for facial affect recognition. By leveraging the strengths of multiple deep learning models and effectively fusing their outputs, the proposed system achieved state-of-the-art performance on this challenge.
Technical Explanation
The paper presents a facial affect recognition system that employs a multi-architecture encoder and feature fusion approach. The system consists of three main components:
-
Multi-Architecture Encoder: The authors use three different deep learning models as the encoders: ViT-B/16, ResNeXt-101, and EfficientNet-B7. Each model has a unique architecture and is trained to extract different types of facial features.
-
Feature Fusion: The features extracted by the three encoders are concatenated and passed through a fusion module, which combines the information from the different models. This fusion step is designed to capture more comprehensive and robust facial representations.
-
Classification Head: The fused features are then fed into a classification head, which predicts the emotional state or facial expression displayed in the input image.
The authors conducted extensive experiments on the ABAW7 Challenge dataset, which includes images of faces labeled with various emotional and facial expression categories. They compared the performance of their multi-architecture and feature fusion approach to single-model baselines and other state-of-the-art methods.
The results show that the proposed system outperforms the single-model baselines and achieves state-of-the-art performance on the ABAW7 Challenge. The authors attribute this improvement to the ability of the multi-architecture encoder to capture diverse facial features, and the effectiveness of the feature fusion module in integrating these complementary sources of information.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated facial affect recognition system. The authors have made a strong case for the benefits of using a multi-architecture encoder and feature fusion approach, which is supported by the impressive results on the ABAW7 Challenge.
However, the paper does not address some potential limitations and areas for further research:
-
Computational Complexity: The use of multiple deep learning models and a fusion module may increase the computational complexity and inference time of the system, which could be a concern for real-time or resource-constrained applications. The authors could have provided more information on the trade-offs between performance and efficiency.
-
Generalization and Robustness: While the system performs well on the ABAW7 Challenge dataset, it is unclear how it would generalize to other facial affect recognition tasks or datasets with different characteristics. Further evaluation on a broader range of scenarios would be helpful to assess the system's robustness.
-
Interpretability: Deep learning models can sometimes be seen as "black boxes," making it difficult to understand the underlying decision-making processes. Exploring ways to improve the interpretability of the proposed system could enhance its transparency and trust in real-world applications.
-
Ethical Considerations: Facial affect recognition systems, if not designed and deployed carefully, can raise ethical concerns related to privacy, bias, and the potential for misuse. The authors could have discussed some of these important ethical implications and how they might be addressed.
Despite these potential limitations, the paper presents a valuable contribution to the field of facial affect recognition and demonstrates the benefits of leveraging multiple deep learning models and feature fusion techniques.
Conclusion
The paper introduces a facial affect recognition system that employs a multi-architecture encoder and feature fusion approach to achieve state-of-the-art performance on the ABAW7 Challenge. By combining the strengths of different deep learning models, the proposed system is able to capture a more comprehensive representation of facial expressions and emotions.
The results of the study highlight the potential of multi-model and feature fusion techniques in computer vision tasks, particularly in the context of facial affect recognition. This work could have significant implications for a wide range of applications, such as human-computer interaction, mental health monitoring, and social robotics.
Overall, the paper presents a compelling and technically sound approach to facial affect recognition, paving the way for further advancements in this important field of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Facial Affect Recognition based on Multi Architecture Encoder and Feature Fusion for the ABAW7 Challenge
Kang Shen, Xuxiong Liu, Boyan Wang, Jun Yao, Xin Liu, Yujie Guan, Yu Wang, Gengchen Li, Xiao Sun
In this paper, we present our approach to addressing the challenges of the 7th ABAW competition. The competition comprises three sub-challenges: Valence Arousal (VA) estimation, Expression (Expr) classification, and Action Unit (AU) detection. To tackle these challenges, we employ state-of-the-art models to extract powerful visual features. Subsequently, a Transformer Encoder is utilized to integrate these features for the VA, Expr, and AU sub-challenges. To mitigate the impact of varying feature dimensions, we introduce an affine module to align the features to a common dimension. Overall, our results significantly outperform the baselines.
Read more7/29/2024
👁️
0
Enhancing Facial Expression Recognition through Dual-Direction Attention Mixed Feature Networks: Application to 7th ABAW Challenge
Josep Cabacas-Maso, Elena Ortega-Beltr'an, Ismael Benito-Altamirano, Carles Ventura
We present our contribution to the 7th ABAW challenge at ECCV 2024, by utilizing a Dual-Direction Attention Mixed Feature Network (DDAMFN) for multitask facial expression recognition, we achieve results far beyond the proposed baseline for the Multi-Task ABAW challenge. Our proposal uses the well-known DDAMFN architecture as base to effectively predict valence-arousal, emotion recognition, and facial action units. We demonstrate the architecture ability to handle these tasks simultaneously, providing insights into its architecture and the rationale behind its design. Additionally, we compare our results for a multitask solution with independent single-task performance.
Read more9/6/2024
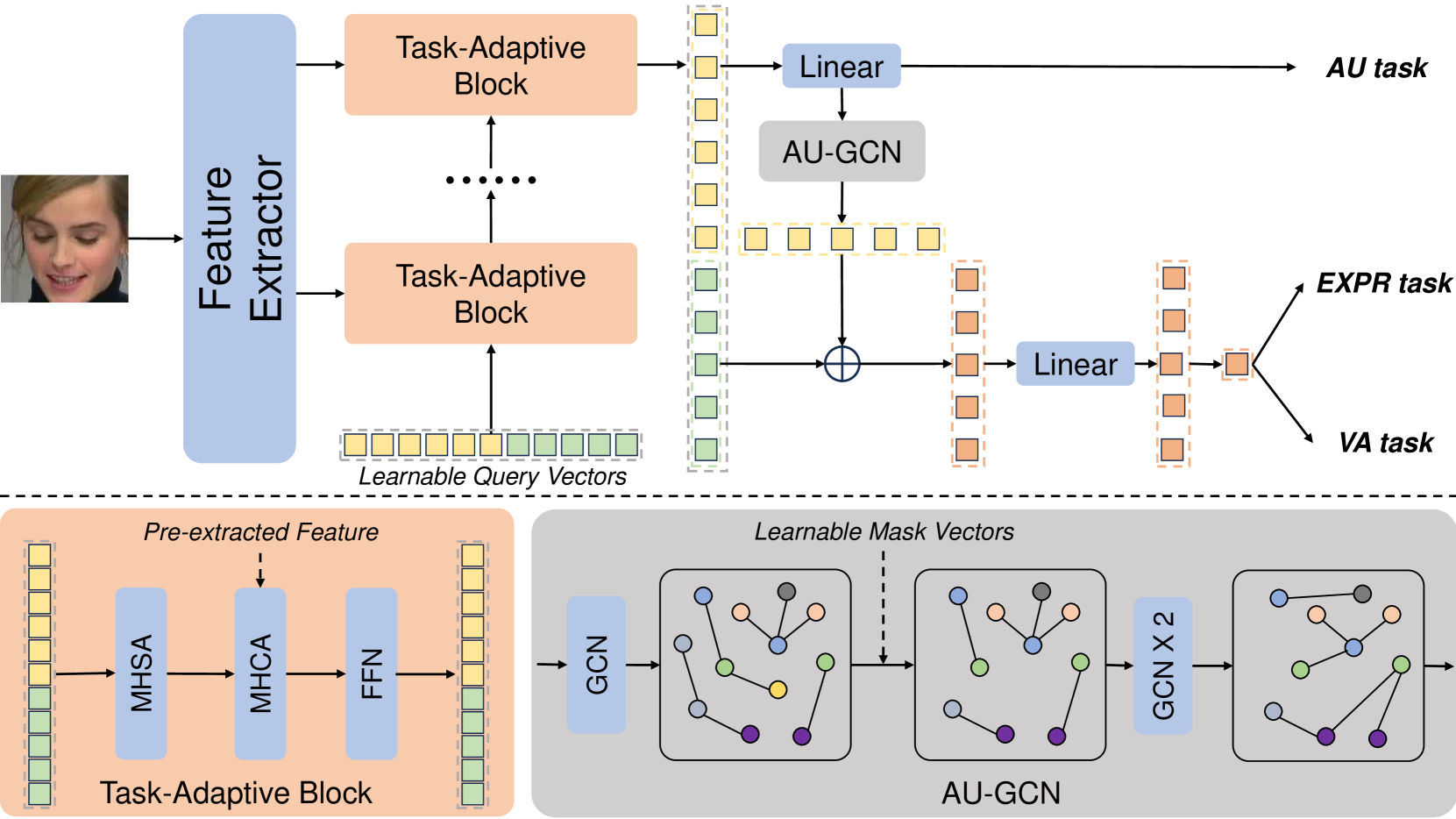
0
Affective Behavior Analysis using Task-adaptive and AU-assisted Graph Network
Xiaodong Li, Wenchao Du, Hongyu Yang
In this paper, we present our solution and experiment result for the Multi-Task Learning Challenge of the 7th Affective Behavior Analysis in-the-wild(ABAW7) Competition. This challenge consists of three tasks: action unit detection, facial expression recognition, and valance-arousal estimation. We address the research problems of this challenge from three aspects: 1)For learning robust visual feature representations, we introduce the pre-trained large model Dinov2. 2) To adaptively extract the required features of eack task, we design a task-adaptive block that performs cross-attention between a set of learnable query vectors and pre-extracted features. 3) By proposing the AU-assisted Graph Convolutional Network(AU-GCN), we make full use of the correlation information between AUs to assist in solving the EXPR and VA tasks. Finally, we achieve the evaluation measure of textbf{1.2542} on the validation set provided by the organizers.
Read more7/17/2024

0
HSEmotion Team at the 7th ABAW Challenge: Multi-Task Learning and Compound Facial Expression Recognition
Andrey V. Savchenko
In this paper, we describe the results of the HSEmotion team in two tasks of the seventh Affective Behavior Analysis in-the-wild (ABAW) competition, namely, multi-task learning for simultaneous prediction of facial expression, valence, arousal, and detection of action units, and compound expression recognition. We propose an efficient pipeline based on frame-level facial feature extractors pre-trained in multi-task settings to estimate valence-arousal and basic facial expressions given a facial photo. We ensure the privacy-awareness of our techniques by using the lightweight architectures of neural networks, such as MT-EmotiDDAMFN, MT-EmotiEffNet, and MT-EmotiMobileFaceNet, that can run even on a mobile device without the need to send facial video to a remote server. It was demonstrated that a significant step in improving the overall accuracy is the smoothing of neural network output scores using Gaussian or box filters. It was experimentally demonstrated that such a simple post-processing of predictions from simple blending of two top visual models improves the F1-score of facial expression recognition up to 7%. At the same time, the mean Concordance Correlation Coefficient (CCC) of valence and arousal is increased by up to 1.25 times compared to each model's frame-level predictions. As a result, our final performance score on the validation set from the multi-task learning challenge is 4.5 times higher than the baseline (1.494 vs 0.32).
Read more7/19/2024