Fair Mixed Effects Support Vector Machine
2405.06433
0
0
📉
Abstract
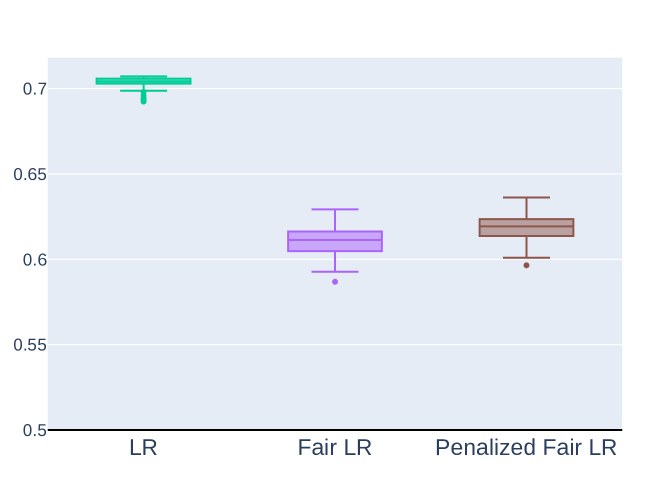
To ensure unbiased and ethical automated predictions, fairness must be a core principle in machine learning applications. Fairness in machine learning aims to mitigate biases present in the training data and model imperfections that could lead to discriminatory outcomes. This is achieved by preventing the model from making decisions based on sensitive characteristics like ethnicity or sexual orientation. A fundamental assumption in machine learning is the independence of observations. However, this assumption often does not hold true for data describing social phenomena, where data points are often clustered based. Hence, if the machine learning models do not account for the cluster correlations, the results may be biased. Especially high is the bias in cases where the cluster assignment is correlated to the variable of interest. We present a fair mixed effects support vector machine algorithm that can handle both problems simultaneously. With a reproducible simulation study we demonstrate the impact of clustered data on the quality of fair machine learning predictions.
Create account to get full access
Overview
- Fairness is a crucial principle in machine learning to mitigate biases and prevent discriminatory outcomes.
- Machine learning models often make assumptions about the independence of data points, which can lead to biased results when dealing with socially-clustered data.
- The paper presents a fair mixed effects support vector machine algorithm to address both the fairness and clustered data challenges simultaneously.
Plain English Explanation
Machine learning models are increasingly being used to make important decisions that impact people's lives, such as loan approvals, job applications, and criminal justice sentencing. However, these models can sometimes be biased and make unfair decisions, leading to discrimination against certain groups based on attributes like race, gender, or sexual orientation.
To address this issue, the researchers in this paper focus on the concept of fairness in machine learning. They explain that a key assumption in machine learning is that each data point, such as an individual person's information, is independent of the others. But in reality, people's lives and experiences are often closely tied to the communities they belong to, which can introduce biases into the data.
For example, imagine a machine learning model used to predict someone's income. If the model doesn't account for the fact that people in certain neighborhoods tend to have similar incomes, it may incorrectly assume that an individual's income is completely independent of where they live. This could lead the model to make unfair predictions that discriminate against people from lower-income areas.
To address this challenge, the researchers developed a new fair machine learning algorithm that can handle both fairness and the clustering of data points. By incorporating these factors, the algorithm can make more accurate and unbiased predictions.
Technical Explanation
The key technical contribution of this paper is a "fair mixed effects support vector machine" algorithm. This algorithm builds upon the standard support vector machine (SVM) approach, which is a widely-used machine learning technique for classification tasks.
The researchers recognized that standard SVMs, like many other machine learning models, make the assumption that each data point is independent of the others. However, as mentioned earlier, this assumption often does not hold true for data describing social phenomena, where data points tend to be clustered.
To address this, the researchers incorporated "mixed effects" into the SVM framework. Mixed effects models account for the fact that data points may be clustered or grouped, such as by geographic location or socioeconomic status. By modeling these cluster-level effects, the algorithm can better capture the underlying structure of the data and make more accurate predictions.
Additionally, the researchers ensured that their algorithm incorporates fairness principles to prevent the model from making decisions based on sensitive attributes like race or gender. This is an important step to mitigate biases and promote algorithmic fairness.
The researchers evaluated their fair mixed effects SVM algorithm using a reproducible simulation study. This allowed them to demonstrate the impact of clustered data on the quality of fair machine learning predictions and validate the effectiveness of their approach.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their paper. One key limitation is that the simulation study they conducted may not fully capture the complexities of real-world data and decision-making scenarios.
Additionally, the paper does not delve into the potential aleatoric and epistemic biases that can arise in machine learning models, which could further complicate the pursuit of fairness.
It would be valuable for future research to explore the performance of the fair mixed effects SVM algorithm on real-world datasets and to investigate the interplay between different types of biases in machine learning systems.
Conclusion
This research paper presents an important step towards developing more fair and unbiased machine learning models. By accounting for both fairness principles and the clustering of data points, the fair mixed effects SVM algorithm offers a promising approach to mitigate biases and promote equitable decision-making.
As machine learning continues to play an increasingly pivotal role in society, the insights and techniques discussed in this paper will be crucial for ensuring that these powerful systems are designed and deployed in a responsible and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Fair Generalized Linear Mixed Models
Jan Pablo Burgard, Jo~ao Vitor Pamplona
0
0
When using machine learning for automated prediction, it is important to account for fairness in the prediction. Fairness in machine learning aims to ensure that biases in the data and model inaccuracies do not lead to discriminatory decisions. E.g., predictions from fair machine learning models should not discriminate against sensitive variables such as sexual orientation and ethnicity. The training data often in obtained from social surveys. In social surveys, oftentimes the data collection process is a strata sampling, e.g. due to cost restrictions. In strata samples, the assumption of independence between the observation is not fulfilled. Hence, if the machine learning models do not account for the strata correlations, the results may be biased. Especially high is the bias in cases where the strata assignment is correlated to the variable of interest. We present in this paper an algorithm that can handle both problems simultaneously, and we demonstrate the impact of stratified sampling on the quality of fair machine learning predictions in a reproducible simulation study.
5/24/2024

Predicting Fairness of ML Software Configuration
Salvador Robles Herrera, Verya Monjezi, Vladik Kreinovich, Ashutosh Trivedi, Saeid Tizpaz-Niari
0
0
This paper investigates the relationships between hyperparameters of machine learning and fairness. Data-driven solutions are increasingly used in critical socio-technical applications where ensuring fairness is important. Rather than explicitly encoding decision logic via control and data structures, the ML developers provide input data, perform some pre-processing, choose ML algorithms, and tune hyperparameters (HPs) to infer a program that encodes the decision logic. Prior works report that the selection of HPs can significantly influence fairness. However, tuning HPs to find an ideal trade-off between accuracy, precision, and fairness has remained an expensive and tedious task. Can we predict fairness of HP configuration for a given dataset? Are the predictions robust to distribution shifts? We focus on group fairness notions and investigate the HP space of 5 training algorithms. We first find that tree regressors and XGBoots significantly outperformed deep neural networks and support vector machines in accurately predicting the fairness of HPs. When predicting the fairness of ML hyperparameters under temporal distribution shift, the tree regressors outperforms the other algorithms with reasonable accuracy. However, the precision depends on the ML training algorithm, dataset, and protected attributes. For example, the tree regressor model was robust for training data shift from 2014 to 2018 on logistic regression and discriminant analysis HPs with sex as the protected attribute; but not for race and other training algorithms. Our method provides a sound framework to efficiently perform fine-tuning of ML training algorithms and understand the relationships between HPs and fairness.
5/1/2024
Fair Clustering: Critique, Caveats, and Future Directions
John Dickerson, Seyed A. Esmaeili, Jamie Morgenstern, Claire Jie Zhang
0
0
Clustering is a fundamental problem in machine learning and operations research. Therefore, given the fact that fairness considerations have become of paramount importance in algorithm design, fairness in clustering has received significant attention from the research community. The literature on fair clustering has resulted in a collection of interesting fairness notions and elaborate algorithms. In this paper, we take a critical view of fair clustering, identifying a collection of ignored issues such as the lack of a clear utility characterization and the difficulty in accounting for the downstream effects of a fair clustering algorithm in machine learning settings. In some cases, we demonstrate examples where the application of a fair clustering algorithm can have significant negative impacts on social welfare. We end by identifying a collection of steps that would lead towards more impactful research in fair clustering.
6/26/2024

Does Machine Bring in Extra Bias in Learning? Approximating Fairness in Models Promptly
Yijun Bian, Yujie Luo
0
0
Providing various machine learning (ML) applications in the real world, concerns about discrimination hidden in ML models are growing, particularly in high-stakes domains. Existing techniques for assessing the discrimination level of ML models include commonly used group and individual fairness measures. However, these two types of fairness measures are usually hard to be compatible with each other, and even two different group fairness measures might be incompatible as well. To address this issue, we investigate to evaluate the discrimination level of classifiers from a manifold perspective and propose a harmonic fairness measure via manifolds (HFM) based on distances between sets. Yet the direct calculation of distances might be too expensive to afford, reducing its practical applicability. Therefore, we devise an approximation algorithm named Approximation of distance between sets (ApproxDist) to facilitate accurate estimation of distances, and we further demonstrate its algorithmic effectiveness under certain reasonable assumptions. Empirical results indicate that the proposed fairness measure HFM is valid and that the proposed ApproxDist is effective and efficient.
5/16/2024