Fair Clustering: Critique, Caveats, and Future Directions
2406.15960
0
0
Abstract
Clustering is a fundamental problem in machine learning and operations research. Therefore, given the fact that fairness considerations have become of paramount importance in algorithm design, fairness in clustering has received significant attention from the research community. The literature on fair clustering has resulted in a collection of interesting fairness notions and elaborate algorithms. In this paper, we take a critical view of fair clustering, identifying a collection of ignored issues such as the lack of a clear utility characterization and the difficulty in accounting for the downstream effects of a fair clustering algorithm in machine learning settings. In some cases, we demonstrate examples where the application of a fair clustering algorithm can have significant negative impacts on social welfare. We end by identifying a collection of steps that would lead towards more impactful research in fair clustering.
Create account to get full access
Overview
- This paper provides a critical analysis of the fair clustering research area, highlighting key caveats, challenges, and future research directions.
- It examines the limitations of current fair clustering techniques and raises important considerations for the development of robust and equitable clustering algorithms.
- The paper encourages the research community to think critically about the assumptions and biases inherent in fair clustering approaches and to explore new directions that address these limitations.
Plain English Explanation
Clustering is a common machine learning technique that groups similar data points together. However, as clustering algorithms have become more widely used, researchers have identified issues around fairness and bias in the way they group people or objects.
The authors of this paper take a closer look at the field of "fair clustering" - methods that try to ensure the clusters produced are fair and don't discriminate against certain groups. They highlight several important caveats and criticisms of this research area:
- Current fair clustering techniques often rely on simplistic notions of fairness that may not reflect real-world complexities. For example, they may assume group membership is known, when in reality it can be uncertain or ambiguous.
- Many fair clustering approaches focus only on demographic parity, without considering other important factors like individual merit or systemic biases in the input data.
- There are open questions around how to properly evaluate the fairness of clustering outputs, and how to balance fairness with other desirable properties like cluster quality.
The paper encourages the research community to grapple with these challenges and develop more nuanced, robust fair clustering methods that can better reflect the complexities of real-world applications. It also suggests exploring alternative approaches, like fair mixed-effects support vector machines or considering fairness from a tolerance perspective.
Overall, the paper aims to push the field of fair clustering to move beyond simplistic notions of fairness and tackle the deeper, more difficult challenges involved in developing equitable machine learning systems.
Technical Explanation
The paper begins by providing an overview of the fair clustering research area, which aims to develop clustering algorithms that produce groups that are fair and unbiased with respect to sensitive demographic attributes.
The authors then identify several key caveats and limitations of current fair clustering techniques:
-
Assumptions about Group Membership: Many fair clustering methods assume that group membership (e.g. race, gender) is known with certainty for each data point. However, in reality, group membership can be ambiguous or uncertain, which is not well-addressed by existing approaches.
-
Narrow Notions of Fairness: Fair clustering techniques often focus solely on achieving demographic parity, without considering other important fairness criteria like individual merit or addressing systemic biases present in the input data.
-
Evaluation Challenges: There is an open question of how to properly evaluate the fairness of clustering outputs, and how to balance fairness with other desirable properties like cluster quality.
To address these limitations, the authors suggest exploring alternative frameworks, such as robust fair clustering with uncertainty sets or fair mixed-effects support vector machines. They also discuss the potential of considering algorithmic fairness from a tolerance perspective, which may provide a more nuanced way of thinking about fairness in clustering.
Additionally, the paper highlights the need for more comprehensive evaluations of fair clustering methods, including their performance on real-world datasets and their ability to handle the complexities of practical applications.
Critical Analysis
The paper raises important critiques and caveats regarding the current state of fair clustering research. Its key contribution is the identification of several limitations in existing fair clustering techniques, which the authors argue need to be addressed for the field to make meaningful progress.
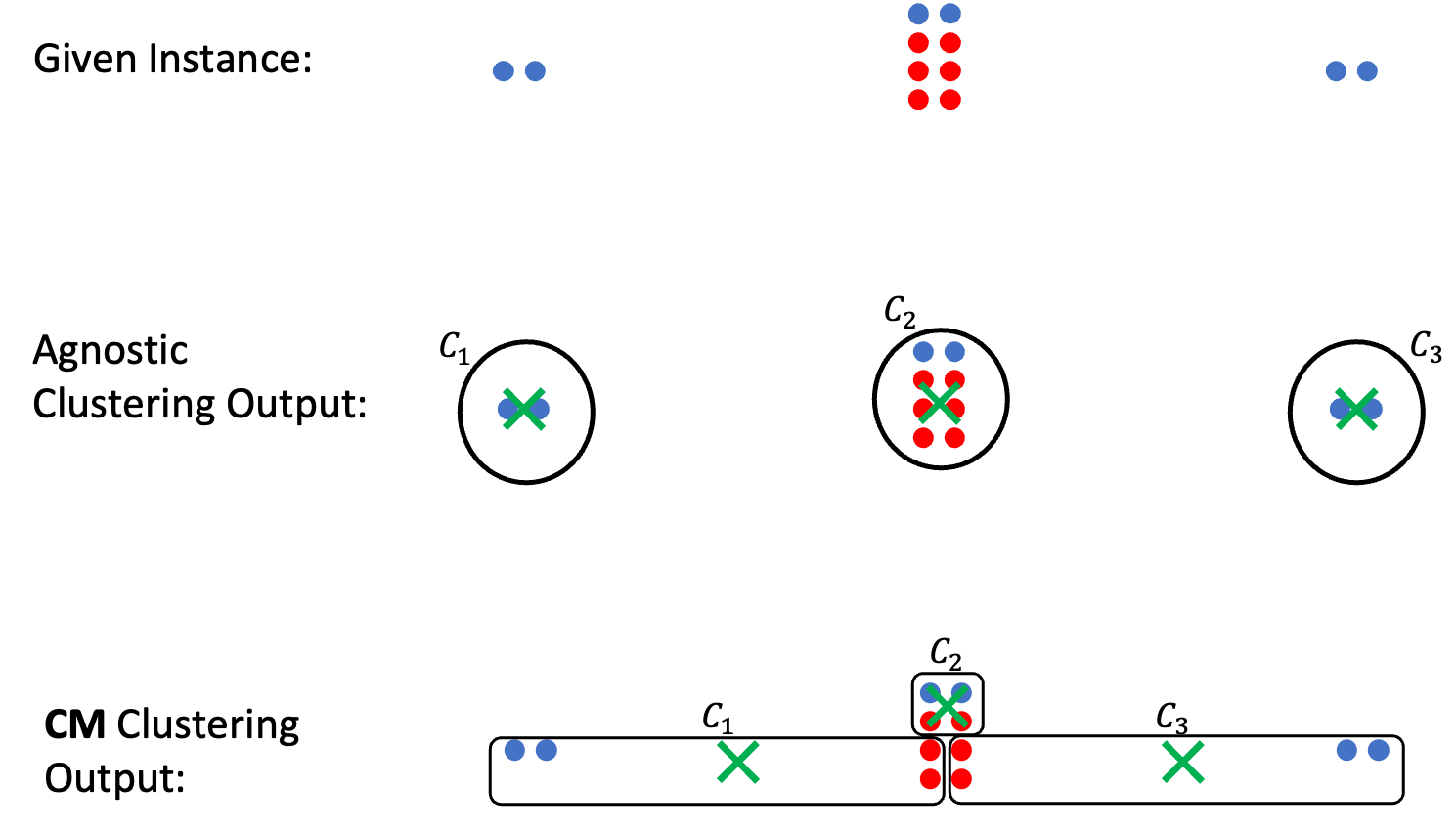
One of the central issues highlighted is the assumption of known group membership, which the authors argue is often an oversimplification of reality. In many real-world scenarios, group membership can be ambiguous or uncertain, and fair clustering methods should be able to handle this complexity. The paper's suggestion to explore robust fair clustering approaches with uncertainty sets is a promising direction to address this limitation.
The authors also rightly point out that many fair clustering techniques focus solely on demographic parity, without considering other important fairness criteria or addressing systemic biases in the input data. This narrow focus on a single fairness metric may lead to solutions that are overly simplistic and fail to capture the nuances of fairness in real-world applications. Exploring alternative fairness frameworks, such as fair mixed-effects support vector machines or algorithmic fairness from a tolerance perspective, could help address this limitation.
While the paper provides a thoughtful critique of the fair clustering research area, it would have been valuable for the authors to also discuss potential pitfalls or unintended consequences of some of the alternative approaches they suggest. For example, the use of tolerance-based fairness metrics could introduce new challenges around how to set appropriate tolerance thresholds.
Overall, the paper serves as an important call to the research community to think critically about the assumptions and limitations of existing fair clustering techniques, and to explore more nuanced and comprehensive approaches that can better address the complexities of real-world fairness considerations.
Conclusion
This paper provides a critical analysis of the fair clustering research area, highlighting key caveats and challenges that the field needs to address. The authors argue that current fair clustering techniques often rely on simplistic notions of fairness and make assumptions about group membership that do not reflect the realities of many real-world applications.
To address these limitations, the paper encourages the research community to explore alternative frameworks, such as robust fair clustering with uncertainty sets, fair mixed-effects support vector machines, and algorithmic fairness from a tolerance perspective. It also highlights the need for more comprehensive evaluations of fair clustering methods, taking into account their performance on real-world datasets and their ability to handle the complexities of practical applications.
Overall, the paper serves as an important critical analysis that challenges the research community to move beyond simplistic notions of fairness in clustering and to develop more nuanced, robust, and equitable machine learning systems. By addressing the caveats and limitations identified in this paper, the field of fair clustering can make important strides towards ensuring that clustering algorithms are fair, unbiased, and truly beneficial to all members of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Robust Fair Clustering with Group Membership Uncertainty Sets
Sharmila Duppala, Juan Luque, John P. Dickerson, Seyed A. Esmaeili
0
0
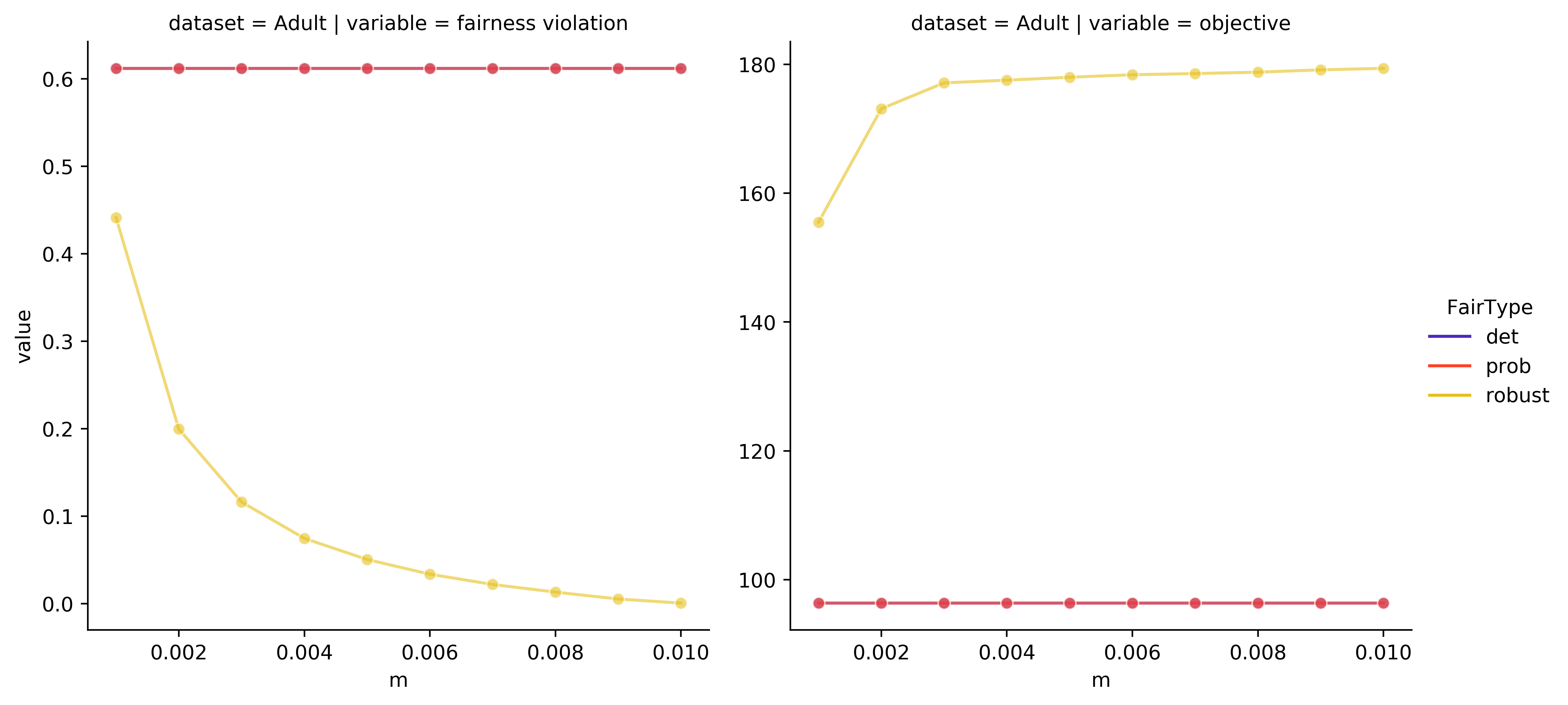
We study the canonical fair clustering problem where each cluster is constrained to have close to population-level representation of each group. Despite significant attention, the salient issue of having incomplete knowledge about the group membership of each point has been superficially addressed. In this paper, we consider a setting where errors exist in the assigned group memberships. We introduce a simple and interpretable family of error models that require a small number of parameters to be given by the decision maker. We then present an algorithm for fair clustering with provable robustness guarantees. Our framework enables the decision maker to trade off between the robustness and the clustering quality. Unlike previous work, our algorithms are backed by worst-case theoretical guarantees. Finally, we empirically verify the performance of our algorithm on real world datasets and show its superior performance over existing baselines.
6/4/2024
📉
Fair Mixed Effects Support Vector Machine
Jo~ao Vitor Pamplona, Jan Pablo Burgard
0
0
To ensure unbiased and ethical automated predictions, fairness must be a core principle in machine learning applications. Fairness in machine learning aims to mitigate biases present in the training data and model imperfections that could lead to discriminatory outcomes. This is achieved by preventing the model from making decisions based on sensitive characteristics like ethnicity or sexual orientation. A fundamental assumption in machine learning is the independence of observations. However, this assumption often does not hold true for data describing social phenomena, where data points are often clustered based. Hence, if the machine learning models do not account for the cluster correlations, the results may be biased. Especially high is the bias in cases where the cluster assignment is correlated to the variable of interest. We present a fair mixed effects support vector machine algorithm that can handle both problems simultaneously. With a reproducible simulation study we demonstrate the impact of clustered data on the quality of fair machine learning predictions.
5/24/2024

Algorithmic Fairness: A Tolerance Perspective
Renqiang Luo, Tao Tang, Feng Xia, Jiaying Liu, Chengpei Xu, Leo Yu Zhang, Wei Xiang, Chengqi Zhang
0
0
Recent advancements in machine learning and deep learning have brought algorithmic fairness into sharp focus, illuminating concerns over discriminatory decision making that negatively impacts certain individuals or groups. These concerns have manifested in legal, ethical, and societal challenges, including the erosion of trust in intelligent systems. In response, this survey delves into the existing literature on algorithmic fairness, specifically highlighting its multifaceted social consequences. We introduce a novel taxonomy based on 'tolerance', a term we define as the degree to which variations in fairness outcomes are acceptable, providing a structured approach to understanding the subtleties of fairness within algorithmic decisions. Our systematic review covers diverse industries, revealing critical insights into the balance between algorithmic decision making and social equity. By synthesizing these insights, we outline a series of emerging challenges and propose strategic directions for future research and policy making, with the goal of advancing the field towards more equitable algorithmic systems.
5/16/2024
💬
Fairness in Large Language Models: A Taxonomic Survey
Zhibo Chu, Zichong Wang, Wenbin Zhang
0
0
Large Language Models (LLMs) have demonstrated remarkable success across various domains. However, despite their promising performance in numerous real-world applications, most of these algorithms lack fairness considerations. Consequently, they may lead to discriminatory outcomes against certain communities, particularly marginalized populations, prompting extensive study in fair LLMs. On the other hand, fairness in LLMs, in contrast to fairness in traditional machine learning, entails exclusive backgrounds, taxonomies, and fulfillment techniques. To this end, this survey presents a comprehensive overview of recent advances in the existing literature concerning fair LLMs. Specifically, a brief introduction to LLMs is provided, followed by an analysis of factors contributing to bias in LLMs. Additionally, the concept of fairness in LLMs is discussed categorically, summarizing metrics for evaluating bias in LLMs and existing algorithms for promoting fairness. Furthermore, resources for evaluating bias in LLMs, including toolkits and datasets, are summarized. Finally, existing research challenges and open questions are discussed.
4/3/2024