Fairness Issues and Mitigations in (Differentially Private) Socio-demographic Data Processes

0

Sign in to get full access
Overview
- The paper discusses fairness issues and mitigation strategies in socio-demographic data processes, particularly in the context of differential privacy.
- It examines how differential privacy techniques can introduce biases and unfairness in data processing and analysis.
- The authors propose methods to address these fairness challenges while preserving privacy protections.
Plain English Explanation
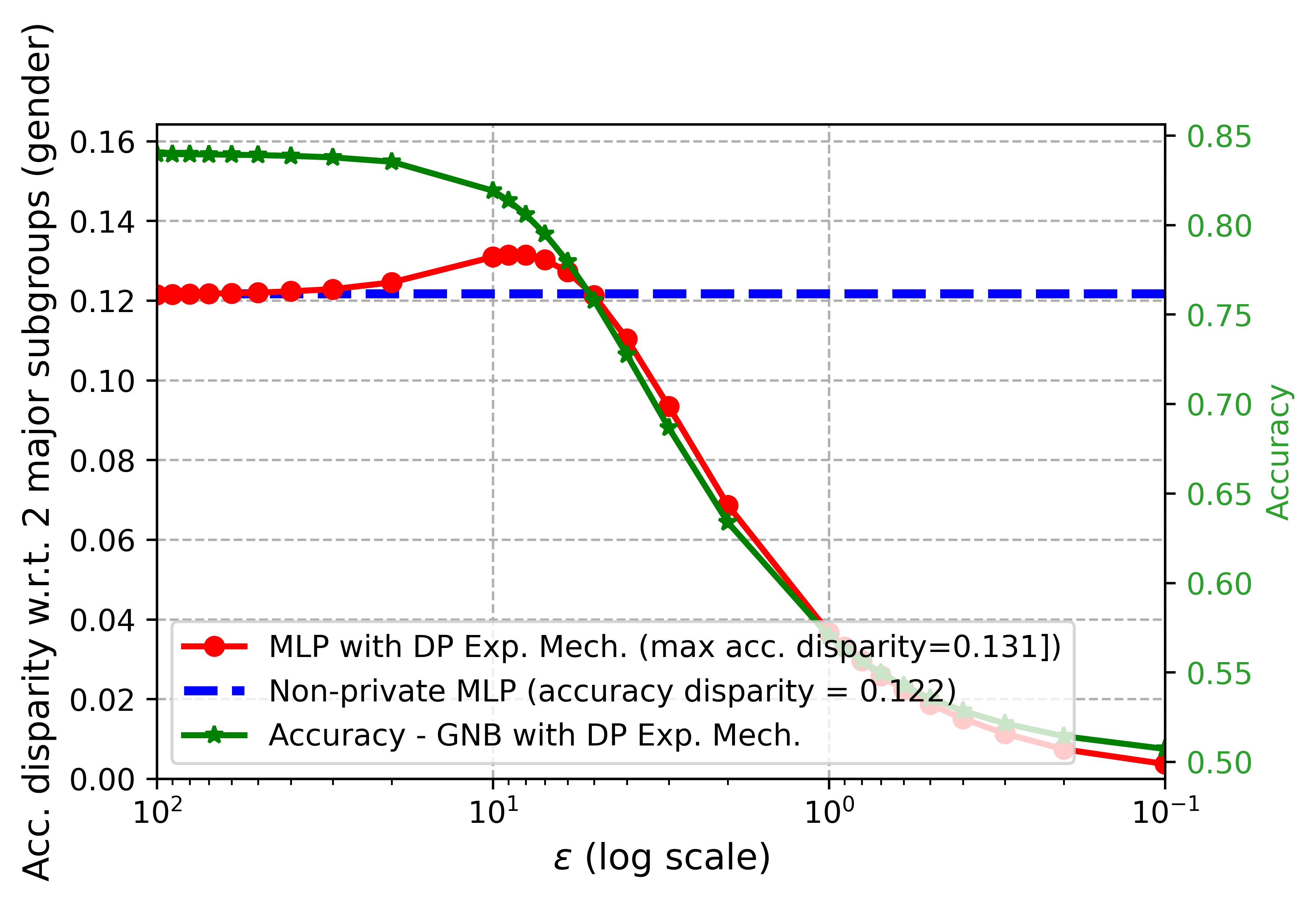
The paper looks at a tricky problem: how can we protect people's privacy when working with sensitive data, like information about demographics, without introducing unfairness or biases? The researchers found that some common privacy-preserving techniques, like "differential privacy", can actually lead to unfair outcomes for certain groups.
For example, imagine a dataset about people's incomes. If you apply differential privacy to protect privacy, it might end up distorting the data in a way that makes it seem like certain racial or gender groups have lower incomes than they actually do. This could then lead to biased decisions or policies.
The researchers explored ways to fix this problem. They came up with methods to adjust the privacy-preserving techniques so that the resulting data is both private and fair, without unfairly disadvantaging any groups. This is an important step in making sure that as we use more data and algorithms, we don't accidentally create new forms of unfairness or discrimination.
Technical Explanation
The paper investigates fairness issues that can arise when applying differential privacy techniques to socio-demographic data. Differential privacy is a widely used approach to protect individual privacy in data processing, but the authors demonstrate how it can introduce biases and unfairness in the output.
The paper presents fairness-aware differential privacy methods to mitigate these issues. These include techniques like differential feature under-reporting and differentially-private synthetic data generation, which aim to preserve both privacy and fairness in the data.
The authors also discuss the trade-offs between privacy and fairness and provide a framework for evaluating fairness in differentially-private data processes.
Critical Analysis
The paper highlights an important and often overlooked issue in the application of differential privacy - the potential for introducing unfairness and biases. While differential privacy is effective at protecting individual privacy, the authors rightly point out that the data distortions it can create can lead to unfair outcomes for certain demographic groups.
The proposed fairness-aware techniques are a promising step towards addressing this challenge. However, the authors acknowledge that there may still be inherent tensions between achieving perfect privacy and perfect fairness. Further research may be needed to fully reconcile these competing objectives.
Additionally, the paper focuses on a limited set of fairness metrics and does not explore more intersectional approaches to fairness. Expanding the fairness framework to consider multiple, overlapping dimensions of identity could lead to more comprehensive solutions.
Conclusion
This paper makes an important contribution by highlighting the fairness implications of differential privacy and proposing methods to address them. As the use of data and algorithms becomes more pervasive, it is crucial that we develop techniques that protect individual privacy while also ensuring fair and equitable outcomes for all. The insights and approaches presented in this work represent a valuable step in that direction, with potential applications in a wide range of socio-demographic data processes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fairness Issues and Mitigations in (Differentially Private) Socio-demographic Data Processes
Joonhyuk Ko, Juba Ziani, Saswat Das, Matt Williams, Ferdinando Fioretto
Statistical agencies rely on sampling techniques to collect socio-demographic data crucial for policy-making and resource allocation. This paper shows that surveys of important societal relevance introduce sampling errors that unevenly impact group-level estimates, thereby compromising fairness in downstream decisions. To address these issues, this paper introduces an optimization approach modeled on real-world survey design processes, ensuring sampling costs are optimized while maintaining error margins within prescribed tolerances. Additionally, privacy-preserving methods used to determine sampling rates can further impact these fairness issues. The paper explores the impact of differential privacy on the statistics informing the sampling process, revealing a surprising effect: not only the expected negative effect from the addition of noise for differential privacy is negligible, but also this privacy noise can in fact reduce unfairness as it positively biases smaller counts. These findings are validated over an extensive analysis using datasets commonly applied in census statistics.
Read more8/19/2024
0
Privacy at a Price: Exploring its Dual Impact on AI Fairness
Mengmeng Yang, Ming Ding, Youyang Qu, Wei Ni, David Smith, Thierry Rakotoarivelo
The worldwide adoption of machine learning (ML) and deep learning models, particularly in critical sectors, such as healthcare and finance, presents substantial challenges in maintaining individual privacy and fairness. These two elements are vital to a trustworthy environment for learning systems. While numerous studies have concentrated on protecting individual privacy through differential privacy (DP) mechanisms, emerging research indicates that differential privacy in machine learning models can unequally impact separate demographic subgroups regarding prediction accuracy. This leads to a fairness concern, and manifests as biased performance. Although the prevailing view is that enhancing privacy intensifies fairness disparities, a smaller, yet significant, subset of research suggests the opposite view. In this article, with extensive evaluation results, we demonstrate that the impact of differential privacy on fairness is not monotonous. Instead, we observe that the accuracy disparity initially grows as more DP noise (enhanced privacy) is added to the ML process, but subsequently diminishes at higher privacy levels with even more noise. Moreover, implementing gradient clipping in the differentially private stochastic gradient descent ML method can mitigate the negative impact of DP noise on fairness. This mitigation is achieved by moderating the disparity growth through a lower clipping threshold.
Read more4/16/2024
🤷
0
A Systematic and Formal Study of the Impact of Local Differential Privacy on Fairness: Preliminary Results
Karima Makhlouf, Tamara Stefanovic, Heber H. Arcolezi, Catuscia Palamidessi
Machine learning (ML) algorithms rely primarily on the availability of training data, and, depending on the domain, these data may include sensitive information about the data providers, thus leading to significant privacy issues. Differential privacy (DP) is the predominant solution for privacy-preserving ML, and the local model of DP is the preferred choice when the server or the data collector are not trusted. Recent experimental studies have shown that local DP can impact ML prediction for different subgroups of individuals, thus affecting fair decision-making. However, the results are conflicting in the sense that some studies show a positive impact of privacy on fairness while others show a negative one. In this work, we conduct a systematic and formal study of the effect of local DP on fairness. Specifically, we perform a quantitative study of how the fairness of the decisions made by the ML model changes under local DP for different levels of privacy and data distributions. In particular, we provide bounds in terms of the joint distributions and the privacy level, delimiting the extent to which local DP can impact the fairness of the model. We characterize the cases in which privacy reduces discrimination and those with the opposite effect. We validate our theoretical findings on synthetic and real-world datasets. Our results are preliminary in the sense that, for now, we study only the case of one sensitive attribute, and only statistical disparity, conditional statistical disparity, and equal opportunity difference.
Read more5/24/2024

0
Understanding and Mitigating the Impacts of Differentially Private Census Data on State Level Redistricting
Christian Cianfarani, Aloni Cohen
Data from the Decennial Census is published only after applying a disclosure avoidance system (DAS). Data users were shaken by the adoption of differential privacy in the 2020 DAS, a radical departure from past methods. The change raises the question of whether redistricting law permits, forbids, or requires taking account of the effect of disclosure avoidance. Such uncertainty creates legal risks for redistricters, as Alabama argued in a lawsuit seeking to prevent the 2020 DAS's deployment. We consider two redistricting settings in which a data user might be concerned about the impacts of privacy preserving noise: drawing equal population districts and litigating voting rights cases. What discrepancies arise if the user does nothing to account for disclosure avoidance? How might the user adapt her analyses to mitigate those discrepancies? We study these questions by comparing the official 2010 Redistricting Data to the 2010 Demonstration Data -- created using the 2020 DAS -- in an analysis of millions of algorithmically generated state legislative redistricting plans. In both settings, we observe that an analyst may come to incorrect conclusions if they do not account for noise. With minor adaptations, though, the underlying policy goals remain achievable: tweaking selection criteria enables a redistricter to draw balanced plans, and illustrative plans can still be used as evidence of the maximum number of majority-minority districts that are possible in a geography. At least for state legislatures, Alabama's claim that differential privacy ``inhibits a State's right to draw fair lines'' appears unfounded.
Read more9/12/2024