Fast Algorithms for Spiking Neural Network Simulation with FPGAs

0

Sign in to get full access
Overview
- This paper presents fast algorithms for simulating spiking neural networks (SNNs) using field-programmable gate arrays (FPGAs).
- The researchers developed efficient hardware implementations of SNN models and training algorithms to enable real-time, high-performance SNN simulations on FPGAs.
- The proposed techniques aim to address the computational challenges of SNN simulation and unlock the potential of SNNs for edge computing and neuromorphic applications.
Plain English Explanation
Spiking neural networks (SNNs) are a type of artificial neural network that more closely mimic the way the human brain works. Instead of firing signals continuously like traditional neural networks, the neurons in an SNN only fire short "spikes" of activity when stimulated. This makes SNNs more energy-efficient and suitable for edge computing applications like autonomous vehicles or smart devices.
However, simulating SNNs is computationally intensive, which has made it challenging to deploy them in real-world applications. This paper explores ways to speed up SNN simulations using specialized hardware called field-programmable gate arrays (FPGAs). FPGAs are reconfigurable chips that can be optimized for specific tasks, in this case, running SNN models very efficiently.
The researchers developed new algorithms and hardware designs to dramatically improve the performance of SNN simulations on FPGAs. This allows them to run complex SNN models in real-time, unlocking the potential of SNNs for various edge computing and neuromorphic (brain-inspired) applications. By making SNN simulation faster and more efficient, this work could lead to new breakthroughs in areas like robotics, autonomous systems, and energy-efficient AI at the edge.
Technical Explanation
The paper presents several key innovations to enable fast, efficient SNN simulation on FPGAs:
-
Optimized SNN Model Representation: The researchers developed a compact, hardware-friendly representation of SNN models that reduces memory requirements and enables parallel processing on FPGAs.
-
Efficient Neuron and Synapse Computations: They designed custom hardware blocks for performing the core computations of SNN neurons and synapses, leveraging techniques like pipelining and parallelization to maximize throughput.
-
Scalable Neuron and Synapse Mapping: The team developed algorithms to map large-scale SNN models onto the FPGA fabric, distributing the computations across multiple processing elements to achieve high performance.
-
Accelerated Spike Processing: Novel spike processing and event-driven simulation algorithms were implemented to minimize the computational overhead of handling individual spikes, a key bottleneck in SNN simulation.
-
Training-Aware Hardware Design: The researchers co-designed the hardware architecture and SNN training algorithms to enable efficient on-chip learning, avoiding the need to offload training to a separate system.
Through these innovations, the paper demonstrates SNN simulations running at over 1 million neurons and 1 billion synapses per second on a single FPGA, orders of magnitude faster than previous FPGA-based approaches. This advances the state-of-the-art in SNN hardware acceleration and brings us closer to realizing the potential of SNNs for real-world edge computing applications.
Critical Analysis
The paper provides a comprehensive set of techniques to accelerate SNN simulation on FPGAs, addressing key bottlenecks in computation, memory usage, and scalability. The authors have clearly put a significant amount of thought and engineering effort into their hardware designs and algorithms.
That said, the paper does not address some important practical considerations for deploying these FPGA-based SNN systems. For example, it does not discuss the power consumption or energy efficiency of the proposed designs, which are crucial factors for edge computing applications. Additionally, the authors do not provide any analysis of the training time or accuracy of the SNN models when using their hardware-aware training approach.
Furthermore, the paper focuses solely on FPGA-based acceleration, while other hardware platforms like GPUs or specialized neuromorphic chips may also be viable options for SNN simulation. A more comprehensive comparison of different hardware approaches and their tradeoffs would strengthen the paper's contributions.
Overall, the techniques presented in this paper represent an important step forward in enabling high-performance SNN simulation on reconfigurable hardware. However, further research is needed to fully understand the practical implications and trade-offs of this approach for real-world edge computing scenarios.
Conclusion
This paper introduces a set of fast algorithms and hardware designs that enable efficient simulation of large-scale spiking neural networks (SNNs) on field-programmable gate arrays (FPGAs). By developing optimized representations of SNN models, custom computational blocks, and scalable mapping strategies, the researchers have demonstrated SNN simulations running at over 1 million neurons and 1 billion synapses per second on a single FPGA.
These innovations unlock the potential of SNNs for real-time, energy-efficient edge computing applications, such as autonomous systems, robotics, and embedded AI. By bridging the gap between the computational demands of SNNs and the capabilities of reconfigurable hardware, this work represents an important step towards the widespread adoption of neuromorphic computing technologies.
Further research is needed to fully understand the practical implications and trade-offs of this FPGA-based approach, particularly in terms of power consumption, training efficiency, and comparative performance against other hardware platforms. Nevertheless, the techniques presented in this paper make a significant contribution to the field of spiking neural network simulation and hardware acceleration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fast Algorithms for Spiking Neural Network Simulation with FPGAs
Bjorn A. Lindqvist, Artur Podobas
Using OpenCL-based high-level synthesis, we create a number of spiking neural network (SNN) simulators for the Potjans-Diesmann cortical microcircuit for a high-end Field-Programmable Gate Array (FPGA). Our best simulators simulate the circuit 25% faster than real-time, require less than 21 nJ per synaptic event, and are bottle-necked by the device's on-chip memory. Speed-wise they compare favorably to the state-of-the-art GPU-based simulators and their energy usage is lower than any other published result. This result is the first for simulating the circuit on a single hardware accelerator. We also extensively analyze the techniques and algorithms we implement our simulators with, many of which can be realized on other types of hardware. Thus, this article is of interest to any researcher or practitioner interested in efficient SNN simulation, whether they target FPGAs or not.
Read more5/6/2024
0
An Integrated Toolbox for Creating Neuromorphic Edge Applications
Lars Niedermeier (Niedermeier Consulting, Zurich, ZH, Switzerland), Jeffrey L. Krichmar (Department of Cognitive Sciences, Department of Computer Science, University of California, Irvine, CA, USA)
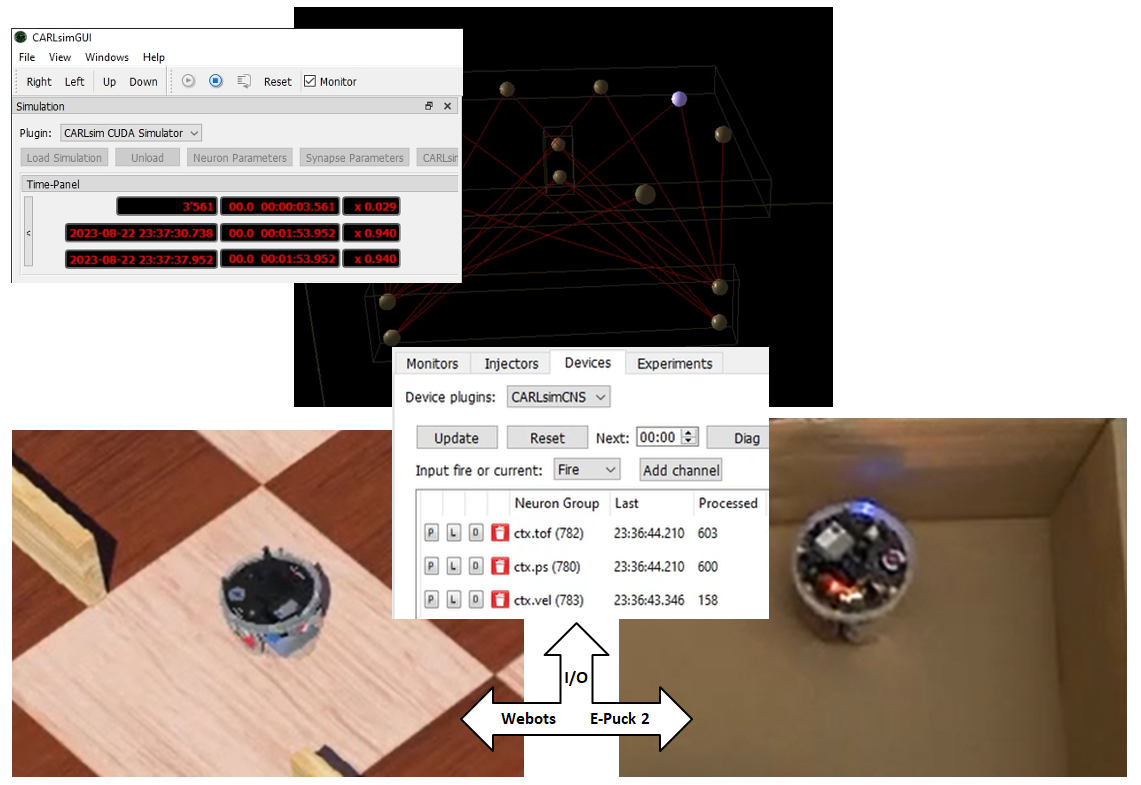
Spiking Neural Networks (SNNs) and neuromorphic models are more efficient and have more biological realism than the activation functions typically used in deep neural networks, transformer models and generative AI. SNNs have local learning rules, are able to learn on small data sets, and can adapt through neuromodulation. Although research has shown their advantages, there are still few compelling practical applications, especially at the edge where sensors and actuators need to be processed in a timely fashion. One reason for this might be that SNNs are much more challenging to understand, build, and operate due to their intrinsic properties. For instance, the mathematical foundation involves differential equations rather than basic activation functions. To address these challenges, we have developed CARLsim++. It is an integrated toolbox that enables fast and easy creation of neuromorphic applications. It encapsulates the mathematical intrinsics and low-level C++ programming by providing a graphical user interface for users who do not have a background in software engineering but still want to create neuromorphic models. Developers can easily configure inputs and outputs to devices and robots. These can be accurately simulated before deploying on physical devices. CARLsim++ can lead to rapid development of neuromorphic applications for simulation or edge processing.
Read more4/16/2024
0
Towards Scalable GPU-Accelerated SNN Training via Temporal Fusion
Yanchen Li, Jiachun Li, Kebin Sun, Luziwei Leng, Ran Cheng
Drawing on the intricate structures of the brain, Spiking Neural Networks (SNNs) emerge as a transformative development in artificial intelligence, closely emulating the complex dynamics of biological neural networks. While SNNs show promising efficiency on specialized sparse-computational hardware, their practical training often relies on conventional GPUs. This reliance frequently leads to extended computation times when contrasted with traditional Artificial Neural Networks (ANNs), presenting significant hurdles for advancing SNN research. To navigate this challenge, we present a novel temporal fusion method, specifically designed to expedite the propagation dynamics of SNNs on GPU platforms, which serves as an enhancement to the current significant approaches for handling deep learning tasks with SNNs. This method underwent thorough validation through extensive experiments in both authentic training scenarios and idealized conditions, confirming its efficacy and adaptability for single and multi-GPU systems. Benchmarked against various existing SNN libraries/implementations, our method achieved accelerations ranging from $5times$ to $40times$ on NVIDIA A100 GPUs. Publicly available experimental codes can be found at https://github.com/EMI-Group/snn-temporal-fusion.
Read more8/2/2024

0
Analog Spiking Neuron in CMOS 28 nm Towards Large-Scale Neuromorphic Processors
Marwan Besrour, Jacob Lavoie, Takwa Omrani, Gabriel Martin-Hardy, Esmaeil Ranjbar Koleibi, Jeremy Menard, Konin Koua, Philippe Marcoux, Mounir Boukadoum, Rejean Fontaine
The computational complexity of deep learning algorithms has given rise to significant speed and memory challenges for the execution hardware. In energy-limited portable devices, highly efficient processing platforms are indispensable for reproducing the prowess afforded by much bulkier processing platforms. In this work, we present a low-power Leaky Integrate-and-Fire (LIF) neuron design fabricated in TSMC's 28 nm CMOS technology as proof of concept to build an energy-efficient mixed-signal Neuromorphic System-on-Chip (NeuroSoC). The fabricated neuron consumes 1.61 fJ/spike and occupies an active area of 34 $mu m^{2}$, leading to a maximum spiking frequency of 300 kHz at 250 mV power supply. These performances are used in a software model to emulate the dynamics of a Spiking Neural Network (SNN). Employing supervised backpropagation and a surrogate gradient technique, the resulting accuracy on the MNIST dataset, using 4-bit post-training quantization stands at 82.5%. The approach underscores the potential of such ASIC implementation of quantized SNNs to deliver high-performance, energy-efficient solutions to various embedded machine-learning applications.
Read more8/16/2024