FAST: Boosting Uncertainty-based Test Prioritization Methods for Neural Networks via Feature Selection

0
Sign in to get full access
Overview
- FAST: Boosting Uncertainty-based Test Prioritization Methods for Neural Networks via Feature Selection
- Proposes a novel approach called FAST to improve uncertainty-based test prioritization for deep neural networks
- Key ideas: feature selection and uncertainty estimation
Plain English Explanation
Deep neural networks (DNNs) are complex models that are widely used in various applications. However, testing and verifying the reliability of these models is a significant challenge. Uncertainty-based test prioritization methods have been proposed to address this, but they can be limited in their effectiveness.
The FAST approach aims to boost the performance of these uncertainty-based methods by incorporating feature selection. The idea is to identify the most influential features in the DNN model and focus the testing efforts on those features. This can help uncover more critical issues and vulnerabilities in the model compared to testing the model as a whole.
The researchers demonstrate that FAST outperforms existing uncertainty-based test prioritization methods in terms of fault detection rate and coverage. By selectively testing the most important features, FAST can more efficiently identify problems in the DNN model.
Technical Explanation
The FAST approach consists of two main components:
-
Feature Selection: The researchers use a technique called Prioritizing Informative Features and Examples for Deep Learning to identify the most influential features in the DNN model. This allows them to focus the testing efforts on the critical parts of the model.
-
Uncertainty Estimation: FAST employs an uncertainty estimation method called Uncertainty-Based Picking of Deep Learning Networks to prioritize the test inputs based on the model's uncertainty. This helps uncover edge cases and potential issues in the DNN.
The researchers evaluate FAST on several DNN models and benchmark datasets, and compare its performance to existing uncertainty-based test prioritization methods. The results show that FAST outperforms these methods in terms of fault detection rate and coverage, demonstrating the benefits of combining feature selection and uncertainty estimation for effective testing of deep neural networks.
Critical Analysis
The researchers acknowledge that FAST, like other uncertainty-based methods, may have limitations in detecting certain types of faults, such as those related to the model's architecture or training process. Additionally, the feature selection technique used in FAST may not always accurately capture the most influential features, especially in complex or highly nonlinear DNN models.
Further research could explore ways to improve the feature selection process, potentially by incorporating additional techniques or domain-specific knowledge. Investigating the performance of FAST on a wider range of DNN models and tasks would also help validate its generalizability.
Conclusion
The FAST approach presents a promising strategy for enhancing the effectiveness of uncertainty-based test prioritization methods for deep neural networks. By combining feature selection and uncertainty estimation, FAST can more efficiently identify critical issues and vulnerabilities in DNN models, which is crucial for ensuring the reliability and robustness of these increasingly important AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FAST: Boosting Uncertainty-based Test Prioritization Methods for Neural Networks via Feature Selection
Jialuo Chen, Jingyi Wang, Xiyue Zhang, Youcheng Sun, Marta Kwiatkowska, Jiming Chen, Peng Cheng
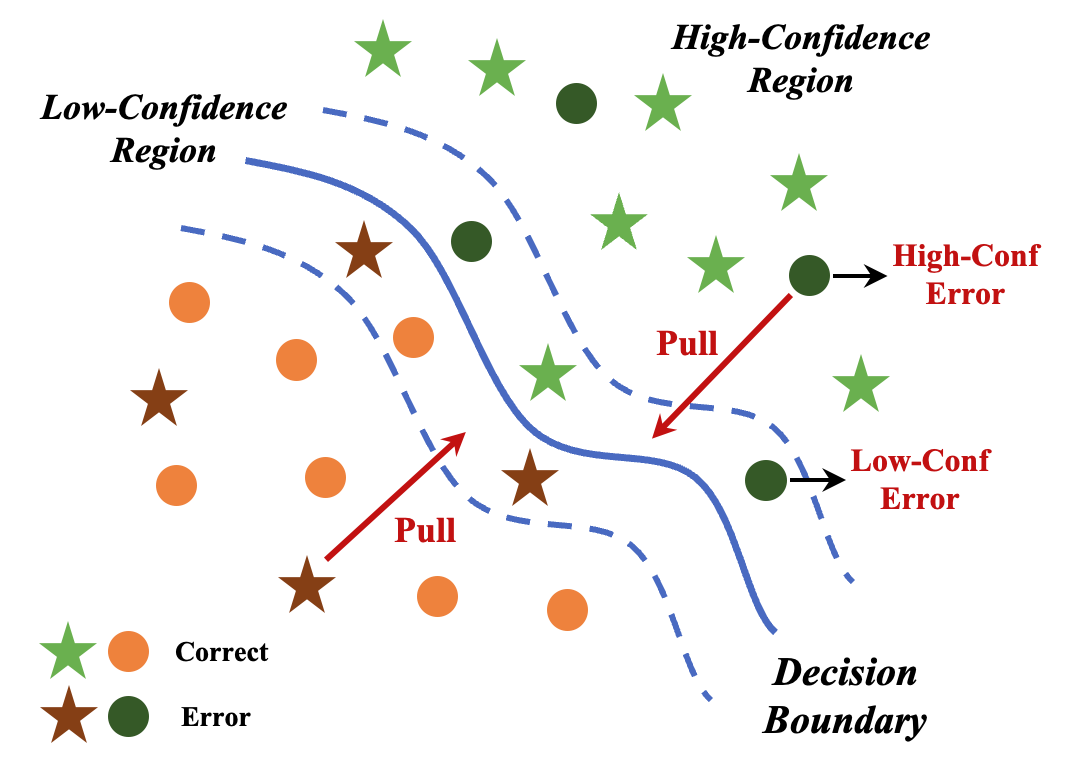
Due to the vast testing space, the increasing demand for effective and efficient testing of deep neural networks (DNNs) has led to the development of various DNN test case prioritization techniques. However, the fact that DNNs can deliver high-confidence predictions for incorrectly predicted examples, known as the over-confidence problem, causes these methods to fail to reveal high-confidence errors. To address this limitation, in this work, we propose FAST, a method that boosts existing prioritization methods through guided FeAture SelecTion. FAST is based on the insight that certain features may introduce noise that affects the model's output confidence, thereby contributing to high-confidence errors. It quantifies the importance of each feature for the model's correct predictions, and then dynamically prunes the information from the noisy features during inference to derive a new probability vector for the uncertainty estimation. With the help of FAST, the high-confidence errors and correctly classified examples become more distinguishable, resulting in higher APFD (Average Percentage of Fault Detection) values for test prioritization, and higher generalization ability for model enhancement. We conduct extensive experiments to evaluate FAST across a diverse set of model structures on multiple benchmark datasets to validate the effectiveness, efficiency, and scalability of FAST compared to the state-of-the-art prioritization techniques.
Read more9/17/2024

0
Prioritizing Informative Features and Examples for Deep Learning from Noisy Data
Dongmin Park
In this dissertation, we propose a systemic framework that prioritizes informative features and examples to enhance each stage of the development process. Specifically, we prioritize informative features and examples and improve the performance of feature learning, data labeling, and data selection. We first propose an approach to extract only informative features that are inherent to solving a target task by using auxiliary out-of-distribution data. We deactivate the noise features in the target distribution by using that in the out-of-distribution data. Next, we introduce an approach that prioritizes informative examples from unlabeled noisy data in order to reduce the labeling cost of active learning. In order to solve the purity-information dilemma, where an attempt to select informative examples induces the selection of many noisy examples, we propose a meta-model that finds the best balance between purity and informativeness. Lastly, we suggest an approach that prioritizes informative examples from labeled noisy data to preserve the performance of data selection. For labeled image noise data, we propose a data selection method that considers the confidence of neighboring samples to maintain the performance of the state-of-the-art Re-labeling models. For labeled text noise data, we present an instruction selection method that takes diversity into account for ranking the quality of instructions with prompting, thereby enhancing the performance of aligned large language models. Overall, our unified framework induces the deep learning development process robust to noisy data, thereby effectively mitigating noisy features and examples in real-world applications.
Read more8/13/2024

0
Provably Neural Active Learning Succeeds via Prioritizing Perplexing Samples
Dake Bu, Wei Huang, Taiji Suzuki, Ji Cheng, Qingfu Zhang, Zhiqiang Xu, Hau-San Wong
Neural Network-based active learning (NAL) is a cost-effective data selection technique that utilizes neural networks to select and train on a small subset of samples. While existing work successfully develops various effective or theory-justified NAL algorithms, the understanding of the two commonly used query criteria of NAL: uncertainty-based and diversity-based, remains in its infancy. In this work, we try to move one step forward by offering a unified explanation for the success of both query criteria-based NAL from a feature learning view. Specifically, we consider a feature-noise data model comprising easy-to-learn or hard-to-learn features disrupted by noise, and conduct analysis over 2-layer NN-based NALs in the pool-based scenario. We provably show that both uncertainty-based and diversity-based NAL are inherently amenable to one and the same principle, i.e., striving to prioritize samples that contain yet-to-be-learned features. We further prove that this shared principle is the key to their success-achieve small test error within a small labeled set. Contrastingly, the strategy-free passive learning exhibits a large test error due to the inadequate learning of yet-to-be-learned features, necessitating resort to a significantly larger label complexity for a sufficient test error reduction. Experimental results validate our findings.
Read more6/7/2024
🤿
0
UPNet: Uncertainty-based Picking Deep Learning Network for Robust First Break Picking
Hongtao Wang, Jiangshe Zhang, Xiaoli Wei, Li Long, Chunxia Zhang
In seismic exploration, first break (FB) picking is a crucial aspect in the determination of subsurface velocity models, significantly influencing the placement of wells. Many deep neural networks (DNNs)-based automatic picking methods have been proposed to accelerate this processing. Significantly, the segmentation-based DNN methods provide a segmentation map and then estimate FB from the map using a picking threshold. However, the uncertainty of the results picked by DNNs still needs to be analyzed. Thus, the automatic picking methods applied in field datasets can not ensure robustness, especially in the case of a low signal-to-noise ratio (SNR). In this paper, we introduce uncertainty quantification into the FB picking task and propose a novel uncertainty-based picking deep learning network called UPNet. UPNet not only estimates the uncertainty of network output but also can filter the pickings with low confidence. Many experiments evaluate that UPNet exhibits higher accuracy and robustness than the deterministic DNN-based model, achieving State-of-the-Art (SOTA) performance in field surveys. In addition, we verify that the measurement uncertainty is meaningful, which can provide a reference for human decision-making.
Read more4/9/2024