Fast Context-Biasing for CTC and Transducer ASR models with CTC-based Word Spotter

0

Sign in to get full access
Overview
- This paper introduces a new technique for "fast context-biasing" in Connectionist Temporal Classification (CTC) and Transducer Automatic Speech Recognition (ASR) models.
- The key idea is to use a CTC-based "word spotter" to quickly identify relevant context words, which can then be used to bias the ASR model's output towards more plausible transcriptions.
- This approach aims to improve ASR accuracy and latency compared to previous context-biasing methods.
Plain English Explanation
The paper describes a way to make speech recognition systems more accurate and faster by using a special technique called "fast context-biasing."
Speech recognition models, like those used in voice assistants, convert speech audio into text. Sometimes these models make mistakes, especially when the audio is noisy or the speaker uses unusual words. To help improve accuracy, researchers have developed methods to "bias" the models towards more likely word sequences based on the context.
For example, if the model hears the audio "I want to ___ a sandwich," it could be biased to output "make" instead of a less common word, since "make a sandwich" is a more natural phrase.
Previous context-biasing techniques worked, but added significant processing time, which is important for real-time applications like voice assistants. This new method uses a separate "CTC-based word spotter" model to quickly identify relevant context words, and then uses that information to efficiently bias the main speech recognition model.
The authors show this "fast context-biasing" approach can improve accuracy compared to previous methods, while also being much faster and more efficient. This could lead to more responsive and reliable speech recognition systems, benefiting voice assistants, dictation tools, and other applications.
Technical Explanation
The paper introduces a new "fast context-biasing" technique for improving the accuracy and latency of both Connectionist Temporal Classification (CTC) and Transducer Automatic Speech Recognition (ASR) models.
The key innovation is the use of a separate CTC-based "word spotter" model that can quickly identify relevant context words from the input audio. This word spotter model is trained in a non-autoregressive way, allowing it to process the audio much faster than the main ASR model.
The context words identified by the word spotter are then used to bias the output of the main ASR model, encouraging it to produce transcriptions that are more consistent with the inferred context. This is achieved through a novel "context-biasing" technique that modifies the model's output logits based on the word spotter's predictions.
The authors evaluate their approach on both CTC and Transducer ASR models, demonstrating significant improvements in transcription accuracy compared to previous context-biasing methods, while also achieving much lower latency. This is enabled by the fast and efficient nature of the CTC-based word spotter.
Critical Analysis
The paper presents a compelling approach to improving the accuracy and latency of speech recognition systems through "fast context-biasing." The authors' key contribution is the introduction of the CTC-based word spotter model, which allows for efficient identification of relevant context words.
One potential limitation of the approach is that it relies on the accuracy of the word spotter model. If the word spotter makes mistakes in its predictions, this could negatively impact the performance of the main ASR model. The authors acknowledge this and suggest further research into improving the robustness of the word spotter.
Additionally, the paper focuses on evaluating the technique on English language tasks. It would be valuable to see how the method generalizes to other languages, which may have different linguistic characteristics and context patterns.
Overall, the "fast context-biasing" approach seems promising and could have significant practical implications for real-world speech recognition applications, especially those with strict latency requirements, such as voice assistants and dictation tools. Further research exploring the method's robustness and cross-lingual applicability would be valuable.
Conclusion
This paper introduces a novel "fast context-biasing" technique for improving the accuracy and latency of CTC and Transducer ASR models. The key innovation is the use of a CTC-based "word spotter" model that can quickly identify relevant context words, which are then used to efficiently bias the main ASR model's output.
The authors demonstrate significant performance improvements over previous context-biasing approaches, while also achieving much lower latency. This could lead to more responsive and reliable speech recognition systems, benefiting a wide range of applications, from voice assistants to dictation tools.
While the paper focuses on English language tasks, the underlying principles of the "fast context-biasing" approach could potentially be applied to other languages as well, pending further research. Overall, this work represents an important step forward in enhancing the capabilities of modern speech recognition systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fast Context-Biasing for CTC and Transducer ASR models with CTC-based Word Spotter
Andrei Andrusenko, Aleksandr Laptev, Vladimir Bataev, Vitaly Lavrukhin, Boris Ginsburg
Accurate recognition of rare and new words remains a pressing problem for contextualized Automatic Speech Recognition (ASR) systems. Most context-biasing methods involve modification of the ASR model or the beam-search decoding algorithm, complicating model reuse and slowing down inference. This work presents a new approach to fast context-biasing with CTC-based Word Spotter (CTC-WS) for CTC and Transducer (RNN-T) ASR models. The proposed method matches CTC log-probabilities against a compact context graph to detect potential context-biasing candidates. The valid candidates then replace their greedy recognition counterparts in corresponding frame intervals. A Hybrid Transducer-CTC model enables the CTC-WS application for the Transducer model. The results demonstrate a significant acceleration of the context-biasing recognition with a simultaneous improvement in F-score and WER compared to baseline methods. The proposed method is publicly available in the NVIDIA NeMo toolkit.
Read more6/12/2024
0
Deferred NAM: Low-latency Top-K Context Injection via DeferredContext Encoding for Non-Streaming ASR
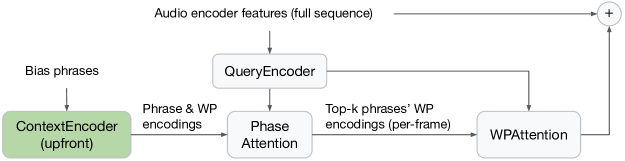
Zelin Wu, Gan Song, Christopher Li, Pat Rondon, Zhong Meng, Xavier Velez, Weiran Wang, Diamantino Caseiro, Golan Pundak, Tsendsuren Munkhdalai, Angad Chandorkar, Rohit Prabhavalkar
Contextual biasing enables speech recognizers to transcribe important phrases in the speaker's context, such as contact names, even if they are rare in, or absent from, the training data. Attention-based biasing is a leading approach which allows for full end-to-end cotraining of the recognizer and biasing system and requires no separate inference-time components. Such biasers typically consist of a context encoder; followed by a context filter which narrows down the context to apply, improving per-step inference time; and, finally, context application via cross attention. Though much work has gone into optimizing per-frame performance, the context encoder is at least as important: recognition cannot begin before context encoding ends. Here, we show the lightweight phrase selection pass can be moved before context encoding, resulting in a speedup of up to 16.1 times and enabling biasing to scale to 20K phrases with a maximum pre-decoding delay under 33ms. With the addition of phrase- and wordpiece-level cross-entropy losses, our technique also achieves up to a 37.5% relative WER reduction over the baseline without the losses and lightweight phrase selection pass.
Read more4/24/2024

0
Improving Neural Biasing for Contextual Speech Recognition by Early Context Injection and Text Perturbation
Ruizhe Huang, Mahsa Yarmohammadi, Sanjeev Khudanpur, Daniel Povey
Existing research suggests that automatic speech recognition (ASR) models can benefit from additional contexts (e.g., contact lists, user specified vocabulary). Rare words and named entities can be better recognized with contexts. In this work, we propose two simple yet effective techniques to improve context-aware ASR models. First, we inject contexts into the encoders at an early stage instead of merely at their last layers. Second, to enforce the model to leverage the contexts during training, we perturb the reference transcription with alternative spellings so that the model learns to rely on the contexts to make correct predictions. On LibriSpeech, our techniques together reduce the rare word error rate by 60% and 25% relatively compared to no biasing and shallow fusion, making the new state-of-the-art performance. On SPGISpeech and a real-world dataset ConEC, our techniques also yield good improvements over the baselines.
Read more7/16/2024

0
Contextualized End-to-end Automatic Speech Recognition with Intermediate Biasing Loss
Muhammad Shakeel, Yui Sudo, Yifan Peng, Shinji Watanabe
Contextualized end-to-end automatic speech recognition has been an active research area, with recent efforts focusing on the implicit learning of contextual phrases based on the final loss objective. However, these approaches ignore the useful contextual knowledge encoded in the intermediate layers. We hypothesize that employing explicit biasing loss as an auxiliary task in the encoder intermediate layers may better align text tokens or audio frames with the desired objectives. Our proposed intermediate biasing loss brings more regularization and contextualization to the network. Our method outperforms a conventional contextual biasing baseline on the LibriSpeech corpus, achieving a relative improvement of 22.5% in biased word error rate (B-WER) and up to 44% compared to the non-contextual baseline with a biasing list size of 100. Moreover, employing RNN-transducer-driven joint decoding further reduces the unbiased word error rate (U-WER), resulting in a more robust network.
Read more6/26/2024