Fast Distributed Inference Serving for Large Language Models

0
🤯
Sign in to get full access
Overview
- Large language models (LLMs) power interactive AI applications like ChatGPT
- These applications require low latency for LLM inference
- Existing LLM serving systems use run-to-completion processing, leading to head-of-line blocking and long latency
Plain English Explanation
The paper presents FastServe, a new system for running LLMs efficiently. LLMs power chatbots and other interactive AI apps, but these apps need the LLM responses to be generated quickly. Unfortunately, current LLM serving systems process each inference job from start to finish, which can cause delays when there are many jobs waiting in line.
FastServe solves this by breaking up the LLM inference process into smaller steps. It can interrupt the processing of one job to work on another, higher-priority job, then come back to the first job later. This helps minimize the waiting time for each individual job. FastServe also has an efficient way of managing the GPU memory needed for LLM inference.
Technical Explanation
FastServe exploits the autoregressive pattern of LLM inference to enable preemption at the token level. It uses a novel skip-join Multi-Level Feedback Queue (MLFQ) scheduler to minimize latency. The scheduler assigns each incoming job an appropriate initial queue based on the input length, and allows higher-priority queues to be skipped to reduce demotions.
FastServe also includes an efficient GPU memory management mechanism. It proactively offloads and uploads intermediate state between GPU memory and host memory to facilitate the preemptive scheduling.
Critical Analysis
The paper does not discuss potential issues with the accuracy or fairness of the LLM models being served by FastServe. While improving inference latency is important, the quality and safety of the model outputs should also be considered.
Additionally, the paper focuses on a single-GPU setting. Further research may be needed to understand how FastServe would scale to multi-GPU or distributed environments, and how it would handle load balancing and fault tolerance in those scenarios.
Conclusion
FastServe presents a novel approach to serving LLMs with low latency by enabling preemptive scheduling and efficient GPU memory management. This can significantly improve the performance of interactive AI applications powered by LLMs. While the paper focuses on the technical aspects, future research should also consider the broader implications of such systems, including their impact on model quality and safety.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
New!Fast Distributed Inference Serving for Large Language Models
Bingyang Wu, Yinmin Zhong, Zili Zhang, Shengyu Liu, Fangyue Liu, Yuanhang Sun, Gang Huang, Xuanzhe Liu, Xin Jin
Large language models (LLMs) power a new generation of interactive AI applications exemplified by ChatGPT. The interactive nature of these applications demands low latency for LLM inference. Existing LLM serving systems use run-to-completion processing for inference jobs, which suffers from head-of-line blocking and long latency. We present FastServe, a distributed inference serving system for LLMs. FastServe exploits the autoregressive pattern of LLM inference to enable preemption at the granularity of each output token. FastServe uses preemptive scheduling to minimize latency with a novel skip-join Multi-Level Feedback Queue scheduler. Based on the new semi-information-agnostic setting of LLM inference, the scheduler leverages the input length information to assign an appropriate initial queue for each arrival job to join. The higher priority queues than the joined queue are skipped to reduce demotions. We design an efficient GPU memory management mechanism that proactively offloads and uploads intermediate state between GPU memory and host memory for LLM inference. We build a system prototype of FastServe and experimental results show that compared to the state-of-the-art solution vLLM, FastServe improves the throughput by up to 31.4x and 17.9x under the same average and tail latency requirements, respectively.
Read more9/26/2024
🤯
0
ServerlessLLM: Low-Latency Serverless Inference for Large Language Models
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, Luo Mai
This paper presents ServerlessLLM, a distributed system designed to support low-latency serverless inference for Large Language Models (LLMs). By harnessing the substantial near-GPU storage and memory capacities of inference servers, ServerlessLLM achieves effective local checkpoint storage, minimizing the need for remote checkpoint downloads and ensuring efficient checkpoint loading. The design of ServerlessLLM features three core contributions: (i) emph{fast multi-tier checkpoint loading}, featuring a new loading-optimized checkpoint format and a multi-tier loading system, fully utilizing the bandwidth of complex storage hierarchies on GPU servers; (ii) emph{efficient live migration of LLM inference}, which enables newly initiated inferences to capitalize on local checkpoint storage while ensuring minimal user interruption; and (iii) emph{startup-time-optimized model scheduling}, which assesses the locality statuses of checkpoints on each server and schedules the model onto servers that minimize the time to start the inference. Comprehensive evaluations, including microbenchmarks and real-world scenarios, demonstrate that ServerlessLLM dramatically outperforms state-of-the-art serverless systems, reducing latency by 10 - 200X across various LLM inference workloads.
Read more7/26/2024
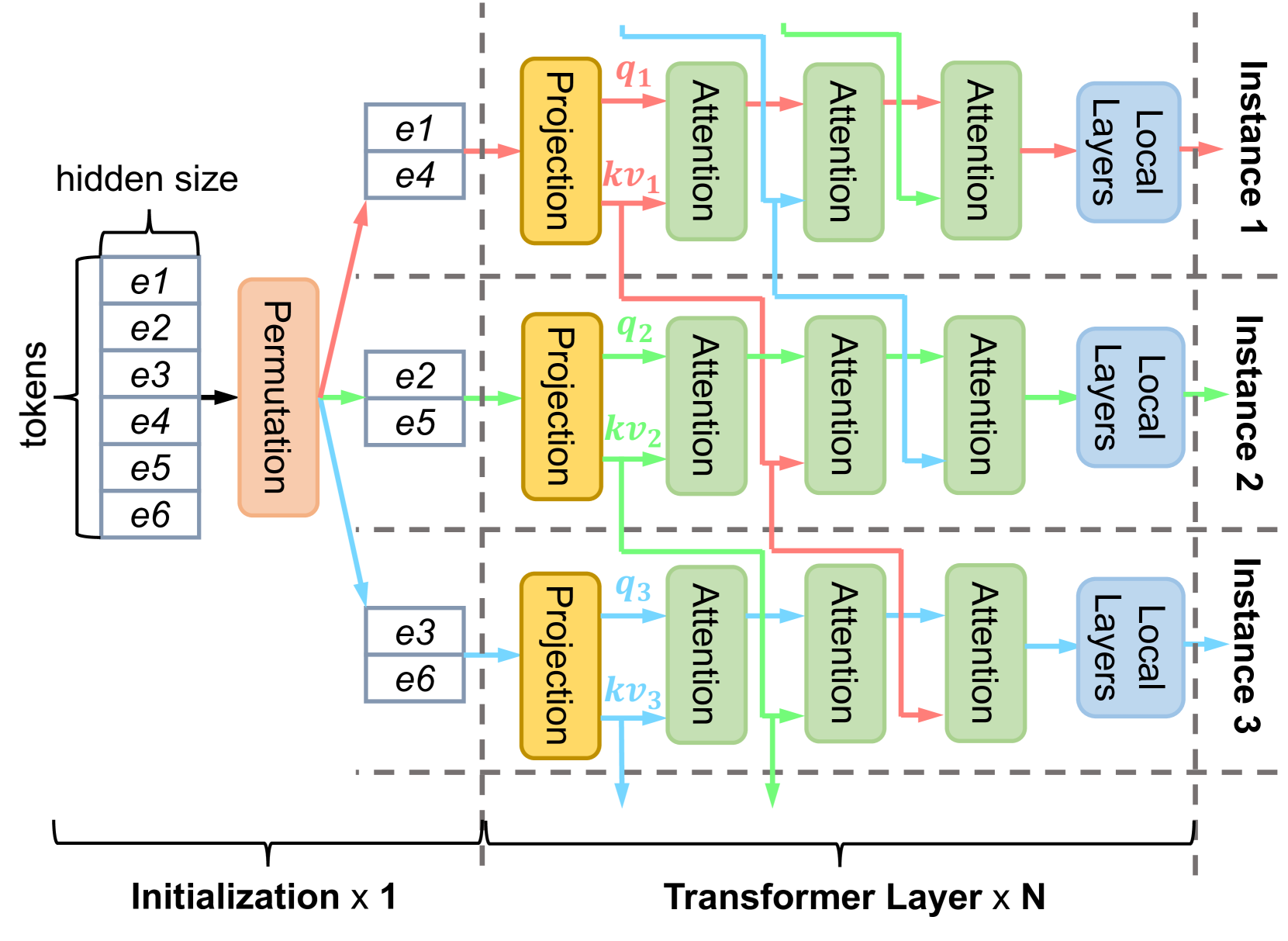
0
LoongServe: Efficiently Serving Long-context Large Language Models with Elastic Sequence Parallelism
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, Xin Jin
The context window of large language models (LLMs) is rapidly increasing, leading to a huge variance in resource usage between different requests as well as between different phases of the same request. Restricted by static parallelism strategies, existing LLM serving systems cannot efficiently utilize the underlying resources to serve variable-length requests in different phases. To address this problem, we propose a new parallelism paradigm, elastic sequence parallelism (ESP), to elastically adapt to the variance between different requests and phases. Based on ESP, we design and build LoongServe, an LLM serving system that (1) improves computation efficiency by elastically adjusting the degree of parallelism in real-time, (2) improves communication efficiency by reducing key-value cache migration overhead and overlapping partial decoding communication with computation, and (3) improves GPU memory efficiency by reducing key-value cache fragmentation across instances. Our evaluation under diverse real-world datasets shows that LoongServe improves the maximum throughput by up to 3.85$times$ compared to the chunked prefill and 5.81$times$ compared to the prefill-decoding disaggregation.
Read more4/16/2024

0
Distributed Inference Performance Optimization for LLMs on CPUs
Pujiang He, Shan Zhou, Changqing Li, Wenhuan Huang, Weifei Yu, Duyi Wang, Chen Meng, Sheng Gui
Large language models (LLMs) hold tremendous potential for addressing numerous real-world challenges, yet they typically demand significant computational resources and memory. Deploying LLMs onto a resource-limited hardware device with restricted memory capacity presents considerable challenges. Distributed computing emerges as a prevalent strategy to mitigate single-node memory constraints and expedite LLM inference performance. To reduce the hardware limitation burden, we proposed an efficient distributed inference optimization solution for LLMs on CPUs. We conduct experiments with the proposed solution on 5th Gen Intel Xeon Scalable Processors, and the result shows the time per output token for the LLM with 72B parameter is 140 ms/token, much faster than the average human reading speed about 200ms per token.
Read more7/2/2024