FDLoRA: Personalized Federated Learning of Large Language Model via Dual LoRA Tuning
2406.07925
0
0

Abstract
Large language models (LLMs) have emerged as important components across various fields, yet their training requires substantial computation resources and abundant labeled data. It poses a challenge to robustly training LLMs for individual users (clients). To tackle this challenge, the intuitive idea is to introduce federated learning (FL), which can collaboratively train models on distributed private data. However, existing methods suffer from the challenges of data heterogeneity, system heterogeneity, and model size, resulting in suboptimal performance and high costs. In this work, we proposed a variant of personalized federated learning (PFL) framework, namely FDLoRA, which allows the client to be a single device or a cluster and adopts low-rank adaptation (LoRA) tuning. FDLoRA sets dual LoRA modules on each client to capture personalized and global knowledge, respectively, and only the global LoRA module uploads parameters to the central server to aggregate cross-client knowledge. Finally, an adaptive fusion approach is employed to combine the parameters of the dual LoRAs. This enables FDLoRA to make effective use of private data distributed across different clients, thereby improving performance on the client without incurring high communication and computing costs. We conducted extensive experiments in two practice scenarios. The results demonstrate that FDLoRA outperforms six baselines in terms of performance, stability, robustness, computation cost, and communication cost.
Create account to get full access
Overview
- The paper proposes a new approach called FDLoRA for personalized federated learning of large language models (LLMs) using Dual LoRA Tuning.
- LoRA (Low-Rank Adaptation) is a technique for efficiently fine-tuning LLMs by only updating a small number of parameters.
- FDLoRA introduces a dual LoRA tuning process that fine-tunes the LLM on both the global task and personalized tasks for each client, allowing for efficient and personalized model updates.
- The approach aims to reduce communication costs in federated learning by requiring clients to only send the low-rank adaptation parameters instead of the entire model.
Plain English Explanation
The paper describes a new way to personalize large language models (LLMs) for individual users or devices in a federated learning setting. Federated learning allows multiple devices to collaboratively train a shared model without sharing their raw data. However, this can be challenging when working with large, complex models like LLMs.
The key idea in FDLoRA is to use a technique called LoRA (Low-Rank Adaptation) to efficiently fine-tune the LLM. LoRA only updates a small number of parameters in the model, rather than the entire thing. This makes the updates much smaller and faster to send over the network.
The paper takes this one step further by applying LoRA in a "dual" way. First, the model is fine-tuned on the overall task that all clients care about. Then, it's fine-tuned again on the personalized tasks for each individual client. This allows the model to capture both the global and personalized knowledge, without dramatically increasing the amount of data that needs to be shared.
The authors show that this approach, called FDLoRA, can achieve good performance on personalized tasks while requiring much less communication compared to standard federated learning approaches for LLMs. This could make it easier to deploy personalized LLMs on a wide range of devices, even with limited network bandwidth.
Technical Explanation
The paper introduces a new federated learning approach called FDLoRA that leverages Dual LoRA Tuning to enable efficient and personalized fine-tuning of large language models (LLMs) in a federated setting.
Federated learning allows multiple clients to collaboratively train a shared model without exchanging their raw data. However, naively applying federated learning to LLMs can be challenging due to the large model size and the need for personalization. The key innovation in FDLoRA is the use of a "dual" LoRA tuning process.
LoRA (Differentially Private Low-Rank Adaptation of Large Language Models) is a technique that can efficiently fine-tune LLMs by only updating a small number of low-rank adaptation parameters, rather than the entire model. FDLoRA builds on this by applying LoRA in two stages:
- The model is first fine-tuned on a global task shared across all clients.
- The model is then fine-tuned again on personalized tasks for each individual client.
This dual LoRA tuning process allows the model to capture both the global knowledge and personalized knowledge, without dramatically increasing the amount of data that needs to be shared during federated learning. The clients only need to send the small LoRA parameters, rather than the entire model.
The authors evaluate FDLoRA on several language modeling benchmarks and show that it can achieve competitive performance on personalized tasks while requiring much lower communication costs compared to standard federated fine-tuning approaches for LLMs.
Critical Analysis
The FDLoRA approach presented in the paper appears to be a promising solution for federated learning of large language models. The use of LoRA to reduce the parameter updates that need to be shared is a clever idea that can significantly reduce communication costs.
However, the paper does not address some potential limitations or concerns with the approach. For example, it's unclear how the method would scale to a large number of clients with diverse personalized tasks. The authors only evaluate the approach on a few benchmark datasets, and it's possible that the performance may degrade in more complex real-world scenarios.
Additionally, the paper does not discuss the potential privacy implications of the dual LoRA tuning process. While federated learning is designed to protect privacy, the personalized fine-tuning step could potentially leak sensitive information about the client data. Further research would be needed to analyze the privacy guarantees of the FDLoRA approach.
Despite these limitations, the core idea of FDLoRA is a significant contribution to the field of federated learning for large language models. The authors have shown that it's possible to achieve personalization without dramatically increasing communication overhead, which could be valuable for a wide range of real-world applications.
Conclusion
The FDLoRA paper presents a novel approach for personalizing large language models in a federated learning setting. By leveraging the LoRA technique for efficient fine-tuning, the authors are able to update the model with personalized knowledge while significantly reducing the communication costs compared to standard federated learning methods.
This work represents an important step forward in making federated learning of complex models like LLMs more practical and accessible. The ability to personalize these models without large data transfers could enable a wide range of applications, from personalized language assistants to federated translation services. While the approach has some potential limitations that require further exploration, the core ideas of FDLoRA are a valuable contribution to the field of federated learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Federated Fine-tuning of Large Language Models under Heterogeneous Tasks and Client Resources
Jiamu Bai, Daoyuan Chen, Bingchen Qian, Liuyi Yao, Yaliang Li
0
0
Federated Learning (FL) has recently been applied to the parameter-efficient fine-tuning of Large Language Models (LLMs). While promising, it raises significant challenges due to the heterogeneous resources and data distributions of clients. This study introduces FlexLoRA, a simple yet effective aggregation scheme for LLM fine-tuning, which mitigates the ``bucket effect'' in traditional FL that restricts the potential of clients with ample resources by tying them to the capabilities of the least-resourced participants. FlexLoRA allows for dynamic adjustment of local LoRA ranks, fostering the development of a global model imbued with broader, less task-specific knowledge. By synthesizing a full-size LoRA weight from individual client contributions and employing Singular Value Decomposition (SVD) for weight redistribution, FlexLoRA fully leverages heterogeneous client resources. Involving thousands of clients performing heterogeneous NLP tasks and client resources, our experiments validate the efficacy of FlexLoRA, with the federated global model achieving consistently better improvement over SOTA FL methods in downstream NLP task performance across various heterogeneous distributions. FlexLoRA's practicality is further underscored by our theoretical analysis and its seamless integration with existing LoRA-based FL methods, offering a path toward cross-device, privacy-preserving federated tuning for LLMs.
5/31/2024

Differentially Private Low-Rank Adaptation of Large Language Model Using Federated Learning
Xiao-Yang Liu, Rongyi Zhu, Daochen Zha, Jiechao Gao, Shan Zhong, Matt White, Meikang Qiu
0
0
The surge in interest and application of large language models (LLMs) has sparked a drive to fine-tune these models to suit specific applications, such as finance and medical science. However, concerns regarding data privacy have emerged, especially when multiple stakeholders aim to collaboratively enhance LLMs using sensitive data. In this scenario, federated learning becomes a natural choice, allowing decentralized fine-tuning without exposing raw data to central servers. Motivated by this, we investigate how data privacy can be ensured in LLM fine-tuning through practical federated learning approaches, enabling secure contributions from multiple parties to enhance LLMs. Yet, challenges arise: 1) despite avoiding raw data exposure, there is a risk of inferring sensitive information from model outputs, and 2) federated learning for LLMs incurs notable communication overhead. To address these challenges, this article introduces DP-LoRA, a novel federated learning algorithm tailored for LLMs. DP-LoRA preserves data privacy by employing a Gaussian mechanism that adds noise in weight updates, maintaining individual data privacy while facilitating collaborative model training. Moreover, DP-LoRA optimizes communication efficiency via low-rank adaptation, minimizing the transmission of updated weights during distributed training. The experimental results across medical, financial, and general datasets using various LLMs demonstrate that DP-LoRA effectively ensures strict privacy constraints while minimizing communication overhead.
6/4/2024
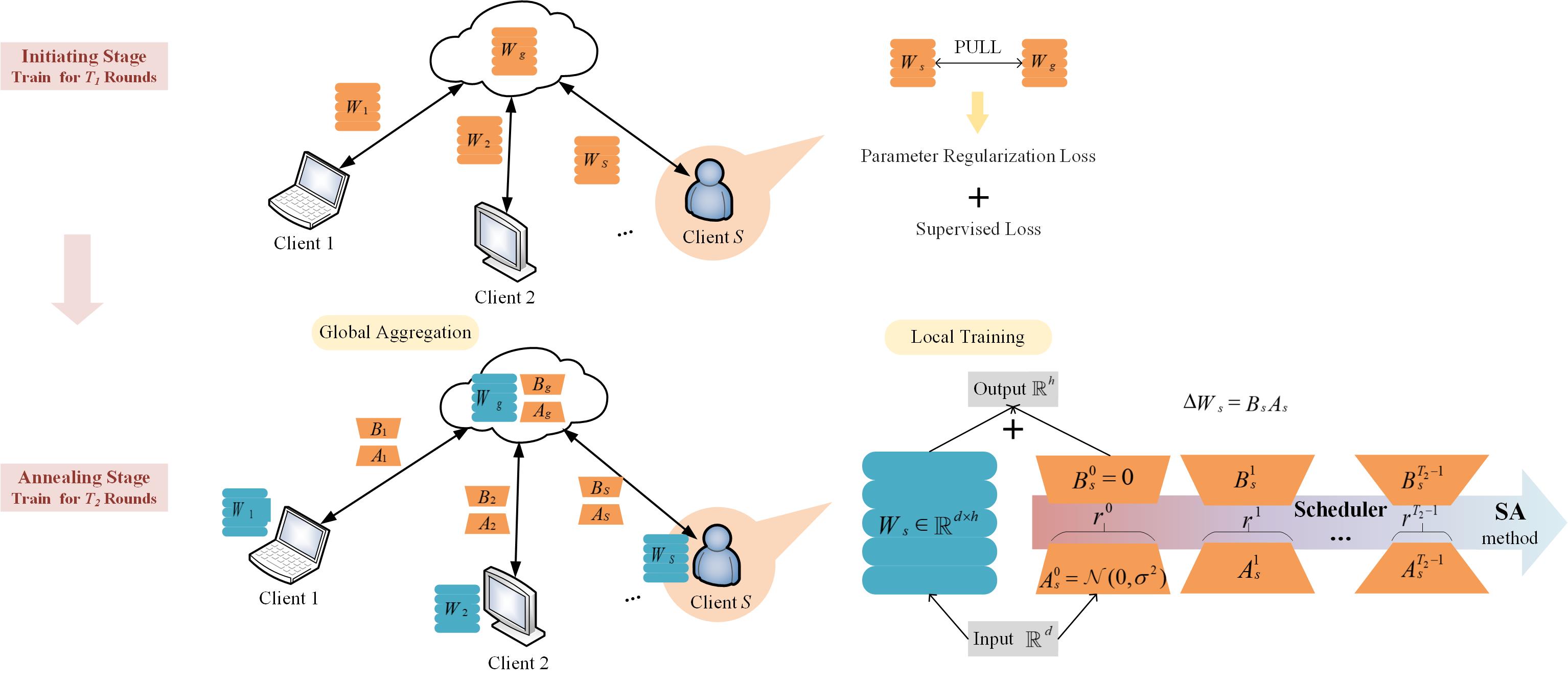
SA-FedLora: Adaptive Parameter Allocation for Efficient Federated Learning with LoRA Tuning
Yuning Yang, Xiaohong Liu, Tianrun Gao, Xiaodong Xu, Guangyu Wang
0
0
Fine-tuning large-scale pre-trained models via transfer learning is an emerging important paradigm for a wide range of downstream tasks, with performance heavily reliant on extensive data. Federated learning (FL), as a distributed framework, provides a secure solution to train models on local datasets while safeguarding raw sensitive data. However, FL networks encounter high communication costs due to the massive parameters of large-scale pre-trained models, necessitating parameter-efficient methods. Notably, parameter efficient fine tuning, such as Low-Rank Adaptation (LoRA), has shown remarkable success in fine-tuning pre-trained models. However, prior research indicates that the fixed parameter budget may be prone to the overfitting or slower convergence. To address this challenge, we propose a Simulated Annealing-based Federated Learning with LoRA tuning (SA-FedLoRA) approach by reducing trainable parameters. Specifically, SA-FedLoRA comprises two stages: initiating and annealing. (1) In the initiating stage, we implement a parameter regularization approach during the early rounds of aggregation, aiming to mitigate client drift and accelerate the convergence for the subsequent tuning. (2) In the annealing stage, we allocate higher parameter budget during the early 'heating' phase and then gradually shrink the budget until the 'cooling' phase. This strategy not only facilitates convergence to the global optimum but also reduces communication costs. Experimental results demonstrate that SA-FedLoRA is an efficient FL, achieving superior performance to FedAvg and significantly reducing communication parameters by up to 93.62%.
5/16/2024

Federated LoRA with Sparse Communication
Kevin Kuo, Arian Raje, Kousik Rajesh, Virginia Smith
0
0
Low-rank adaptation (LoRA) is a natural method for finetuning in communication-constrained machine learning settings such as cross-device federated learning. Prior work that has studied LoRA in the context of federated learning has focused on improving LoRA's robustness to heterogeneity and privacy. In this work, we instead consider techniques for further improving communication-efficiency in federated LoRA. Unfortunately, we show that centralized ML methods that improve the efficiency of LoRA through unstructured pruning do not transfer well to federated settings. We instead study a simple approach, textbf{FLASC}, that applies sparsity to LoRA during communication while allowing clients to locally fine-tune the entire LoRA module. Across four common federated learning tasks, we demonstrate that this method matches the performance of dense LoRA with up to $10times$ less communication. Additionally, despite being designed primarily to target communication, we find that this approach has benefits in terms of heterogeneity and privacy relative to existing approaches tailored to these specific concerns. Overall, our work highlights the importance of considering system-specific constraints when developing communication-efficient finetuning approaches, and serves as a simple and competitive baseline for future work in federated finetuning.
6/11/2024