Feature Expansion and enhanced Compression for Class Incremental Learning
2405.08038
0
0
✨
Abstract
Class incremental learning consists in training discriminative models to classify an increasing number of classes over time. However, doing so using only the newly added class data leads to the known problem of catastrophic forgetting of the previous classes. Recently, dynamic deep learning architectures have been shown to exhibit a better stability-plasticity trade-off by dynamically adding new feature extractors to the model in order to learn new classes followed by a compression step to scale the model back to its original size, thus avoiding a growing number of parameters. In this context, we propose a new algorithm that enhances the compression of previous class knowledge by cutting and mixing patches of previous class samples with the new images during compression using our Rehearsal-CutMix method. We show that this new data augmentation reduces catastrophic forgetting by specifically targeting past class information and improving its compression. Extensive experiments performed on the CIFAR and ImageNet datasets under diverse incremental learning evaluation protocols demonstrate that our approach consistently outperforms the state-of-the-art . The code will be made available upon publication of our work.
Create account to get full access
Overview
- Class incremental learning trains models to classify an increasing number of classes over time
- This leads to catastrophic forgetting of previous classes
- Dynamic deep learning architectures can better balance stability and plasticity by dynamically adding and compressing new feature extractors
- The proposed method, Rehearsal-CutMix, enhances compression of previous class knowledge by cutting and mixing patches of previous class samples with new images during compression
Plain English Explanation
Class incremental learning is a way of training AI models to recognize more and more types of objects or classes over time. However, when you only train the model on the new classes, it often "forgets" how to recognize the old classes - this is called catastrophic forgetting.
Recently, some new AI architectures have been developed that can better balance learning new information and remembering old information. These architectures dynamically add new feature extractors (specialized parts of the model) to learn new classes, and then compress the model back to its original size to avoid it getting too big.
The method proposed in this paper, called Rehearsal-CutMix, enhances this compression step by mixing together patches of previous class samples with the new images. This helps the model better remember and compress the knowledge of the old classes when learning the new ones, reducing catastrophic forgetting. Extensive experiments on common benchmark datasets show this approach outperforms other state-of-the-art methods.
Technical Explanation
The paper proposes a new algorithm called Rehearsal-CutMix that enhances the compression of previous class knowledge in dynamic deep learning architectures for class incremental learning. During the compression step, where the model is scaled back to its original size after adding new feature extractors, Rehearsal-CutMix cuts and mixes patches of previous class samples with the new images.
This data augmentation technique specifically targets the past class information, improving its compression and reducing catastrophic forgetting. The authors demonstrate the effectiveness of their approach through extensive experiments on the CIFAR and ImageNet datasets under diverse incremental learning evaluation protocols.
The results show that Rehearsal-CutMix consistently outperforms other state-of-the-art methods in class incremental learning. The code for the proposed algorithm will be made publicly available upon publication of the work.
Critical Analysis
The paper introduces a novel and promising approach to mitigate catastrophic forgetting in class incremental learning. By focusing on enhancing the compression of previous class knowledge, Rehearsal-CutMix provides an effective solution to a longstanding challenge in this field.
However, the paper does not explore the potential limitations or failure cases of the proposed method. For example, it is unclear how Rehearsal-CutMix would perform on datasets with a large number of classes or significant class imbalance. Additionally, the computational overhead of the cutting and mixing operations during compression is not analyzed.
Further research could investigate the trade-offs between the performance gains and the increased computational complexity introduced by Rehearsal-CutMix. Exploring alternative compression techniques or combining this method with other incremental learning approaches could also be valuable avenues for future work.
Conclusion
This paper presents a novel algorithm, Rehearsal-CutMix, that enhances the compression of previous class knowledge in dynamic deep learning architectures for class incremental learning. By cutting and mixing patches of previous class samples with new images during the compression step, the method effectively reduces catastrophic forgetting and outperforms other state-of-the-art approaches.
The strong experimental results on benchmark datasets suggest that Rehearsal-CutMix is a promising step forward in addressing the longstanding challenge of catastrophic forgetting in continual learning. If further refined and combined with other techniques, this approach could have significant implications for developing more flexible and robust AI systems that can continually expand their knowledge over time.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CCSI: Continual Class-Specific Impression for Data-free Class Incremental Learning
Sana Ayromlou, Teresa Tsang, Purang Abolmaesumi, Xiaoxiao Li
0
0
In real-world clinical settings, traditional deep learning-based classification methods struggle with diagnosing newly introduced disease types because they require samples from all disease classes for offline training. Class incremental learning offers a promising solution by adapting a deep network trained on specific disease classes to handle new diseases. However, catastrophic forgetting occurs, decreasing the performance of earlier classes when adapting the model to new data. Prior proposed methodologies to overcome this require perpetual storage of previous samples, posing potential practical concerns regarding privacy and storage regulations in healthcare. To this end, we propose a novel data-free class incremental learning framework that utilizes data synthesis on learned classes instead of data storage from previous classes. Our key contributions include acquiring synthetic data known as Continual Class-Specific Impression (CCSI) for previously inaccessible trained classes and presenting a methodology to effectively utilize this data for updating networks when introducing new classes. We obtain CCSI by employing data inversion over gradients of the trained classification model on previous classes starting from the mean image of each class inspired by common landmarks shared among medical images and utilizing continual normalization layers statistics as a regularizer in this pixel-wise optimization process. Subsequently, we update the network by combining the synthesized data with new class data and incorporate several losses, including an intra-domain contrastive loss to generalize the deep network trained on the synthesized data to real data, a margin loss to increase separation among previous classes and new ones, and a cosine-normalized cross-entropy loss to alleviate the adverse effects of imbalanced distributions in training data.
6/11/2024

Class incremental learning with probability dampening and cascaded gated classifier
Jary Pomponi, Alessio Devoto, Simone Scardapane
0
0
Humans are capable of acquiring new knowledge and transferring learned knowledge into different domains, incurring a small forgetting. The same ability, called Continual Learning, is challenging to achieve when operating with neural networks due to the forgetting affecting past learned tasks when learning new ones. This forgetting can be mitigated by replaying stored samples from past tasks, but a large memory size may be needed for long sequences of tasks; moreover, this could lead to overfitting on saved samples. In this paper, we propose a novel regularisation approach and a novel incremental classifier called, respectively, Margin Dampening and Cascaded Scaling Classifier. The first combines a soft constraint and a knowledge distillation approach to preserve past learned knowledge while allowing the model to learn new patterns effectively. The latter is a gated incremental classifier, helping the model modify past predictions without directly interfering with them. This is achieved by modifying the output of the model with auxiliary scaling functions. We empirically show that our approach performs well on multiple benchmarks against well-established baselines, and we also study each component of our proposal and how the combinations of such components affect the final results.
5/24/2024

Future-Proofing Class Incremental Learning
Quentin Jodelet, Xin Liu, Yin Jun Phua, Tsuyoshi Murata
0
0
Exemplar-Free Class Incremental Learning is a highly challenging setting where replay memory is unavailable. Methods relying on frozen feature extractors have drawn attention recently in this setting due to their impressive performances and lower computational costs. However, those methods are highly dependent on the data used to train the feature extractor and may struggle when an insufficient amount of classes are available during the first incremental step. To overcome this limitation, we propose to use a pre-trained text-to-image diffusion model in order to generate synthetic images of future classes and use them to train the feature extractor. Experiments on the standard benchmarks CIFAR100 and ImageNet-Subset demonstrate that our proposed method can be used to improve state-of-the-art methods for exemplar-free class incremental learning, especially in the most difficult settings where the first incremental step only contains few classes. Moreover, we show that using synthetic samples of future classes achieves higher performance than using real data from different classes, paving the way for better and less costly pre-training methods for incremental learning.
4/5/2024
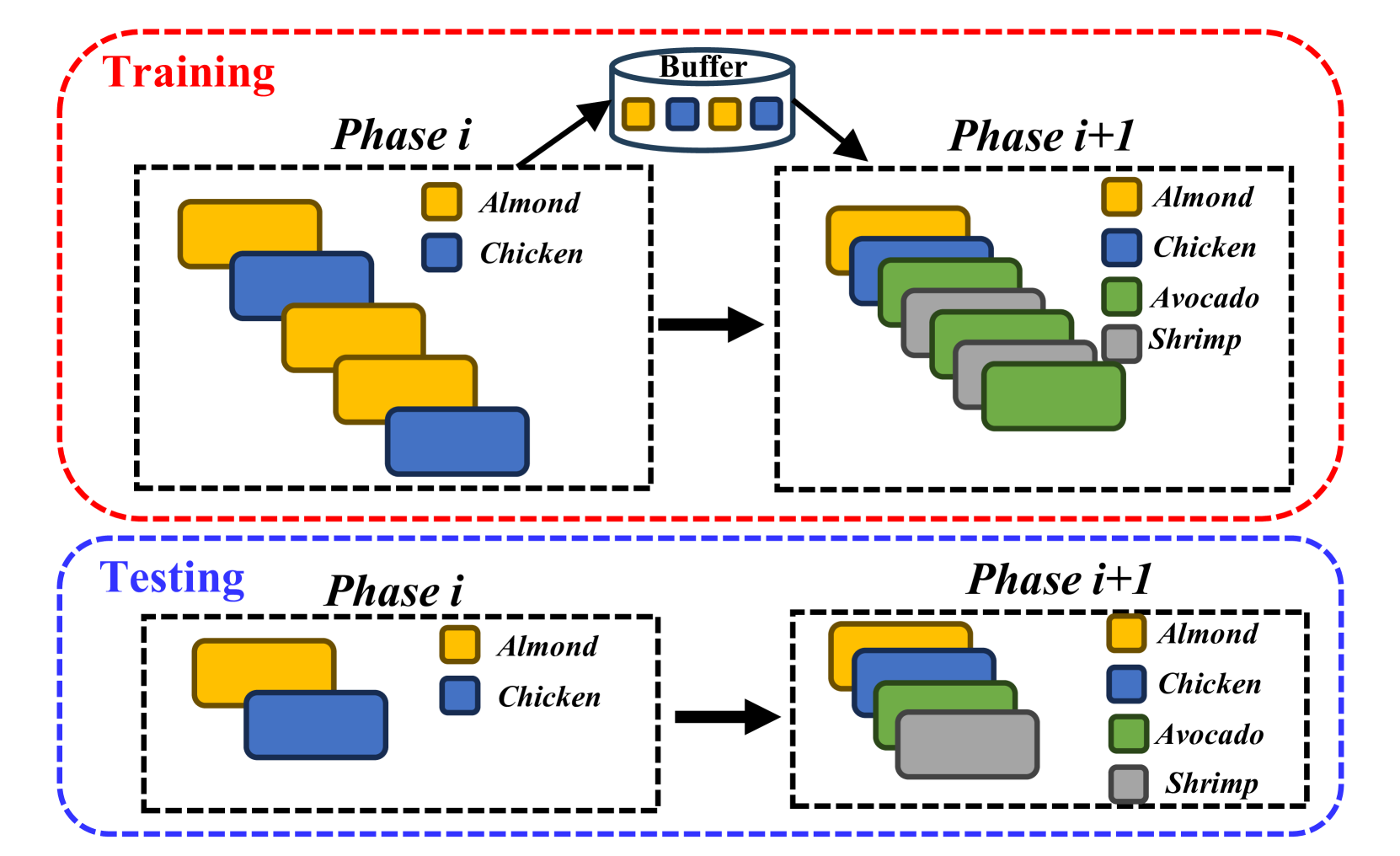
Learning to Classify New Foods Incrementally Via Compressed Exemplars
Justin Yang, Zhihao Duan, Jiangpeng He, Fengqing Zhu
0
0
Food image classification systems play a crucial role in health monitoring and diet tracking through image-based dietary assessment techniques. However, existing food recognition systems rely on static datasets characterized by a pre-defined fixed number of food classes. This contrasts drastically with the reality of food consumption, which features constantly changing data. Therefore, food image classification systems should adapt to and manage data that continuously evolves. This is where continual learning plays an important role. A challenge in continual learning is catastrophic forgetting, where ML models tend to discard old knowledge upon learning new information. While memory-replay algorithms have shown promise in mitigating this problem by storing old data as exemplars, they are hampered by the limited capacity of memory buffers, leading to an imbalance between new and previously learned data. To address this, our work explores the use of neural image compression to extend buffer size and enhance data diversity. We introduced the concept of continuously learning a neural compression model to adaptively improve the quality of compressed data and optimize the bitrates per pixel (bpp) to store more exemplars. Our extensive experiments, including evaluations on food-specific datasets including Food-101 and VFN-74, as well as the general dataset ImageNet-100, demonstrate improvements in classification accuracy. This progress is pivotal in advancing more realistic food recognition systems that are capable of adapting to continually evolving data. Moreover, the principles and methodologies we've developed hold promise for broader applications, extending their benefits to other domains of continual machine learning systems.
4/12/2024