Learning to Classify New Foods Incrementally Via Compressed Exemplars

0
Sign in to get full access
Overview
- This paper presents a method for incrementally learning to classify new food items in an efficient and scalable way.
- The key idea is to use "compressed exemplars" - compact representations of past food images - to enable a model to quickly learn new classes without forgetting previous ones.
- This approach aims to address the challenge of continual learning in food classification, where models need to continuously expand their knowledge without degrading performance on earlier tasks.
Plain English Explanation
The research focuses on building AI models that can learn to recognize new types of foods over time, without forgetting what they've learned before. This is an important challenge, as real-world food recognition systems need to be able to expand their knowledge continuously to stay relevant.
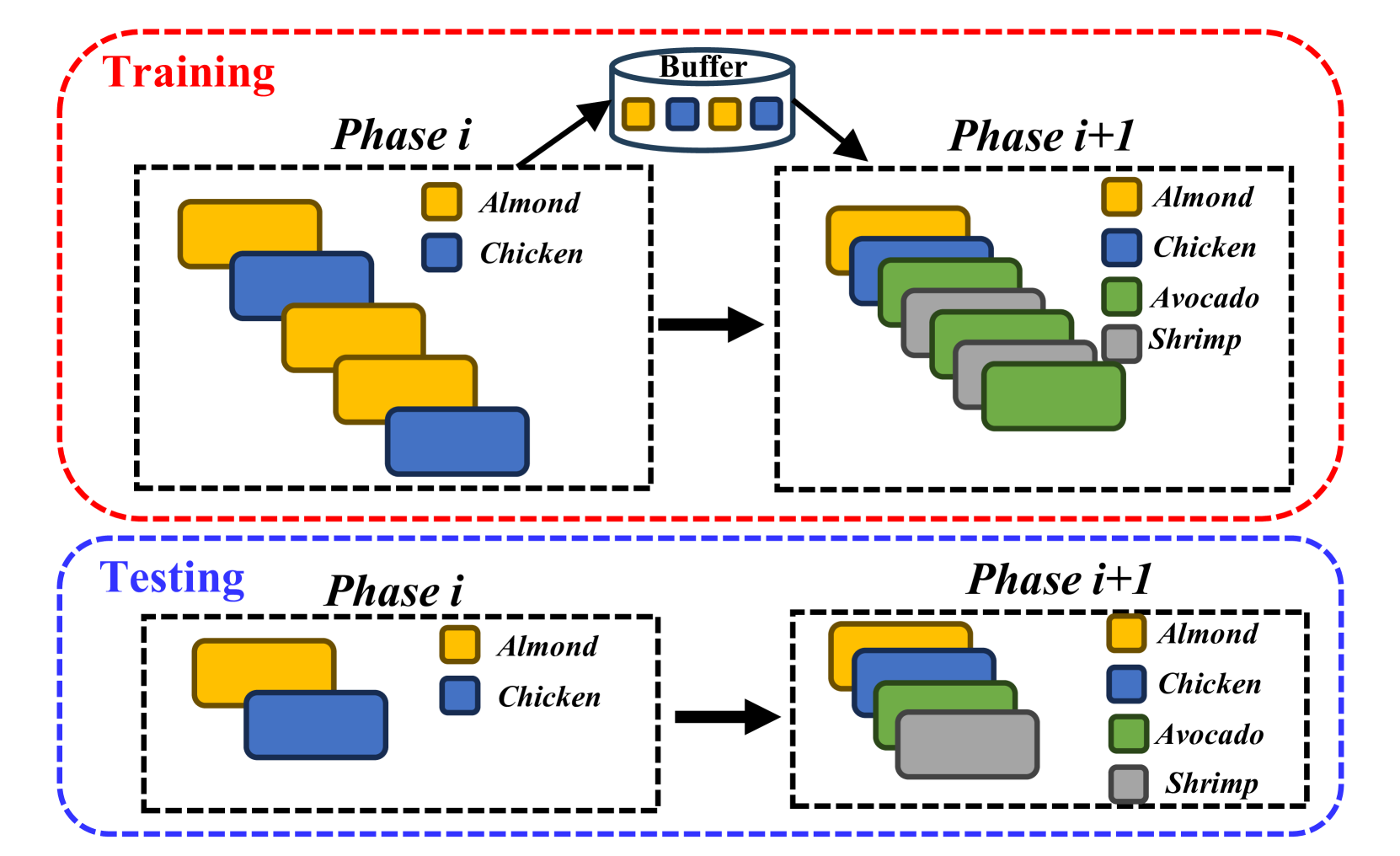
The core innovation is the use of "compressed exemplars" - compact representations of past food images that encode the essential features. When the model encounters a new food class, it can quickly learn from a small number of these compressed exemplars, rather than having to store and revisit all the original training data. This allows the model to efficiently incorporate new knowledge without degrading its performance on previously learned classes, a common issue in continual learning scenarios.
The compressed exemplars act as a sort of "shorthand" for the original data, enabling the model to adapt to new foods in a scalable way. This is an important step towards more realistic continual learning systems that can keep up with the ever-changing world of food.
Technical Explanation
The authors propose a continual learning framework for food image classification that relies on compressed exemplars to enable efficient and scalable incremental learning. The core components are:
-
Exemplar Compression: The model compresses past training examples into a smaller set of "exemplars" that capture the essential features. This is done using a variational autoencoder (VAE) to generate a compact latent representation for each image.
-
Incremental Learning: When a new food class is introduced, the model fine-tunes its classifier head on the compressed exemplars for both the new and previous classes. This allows it to expand its knowledge without significantly degrading performance on earlier tasks, addressing a key challenge in continual learning.
-
Exemplar Management: The system dynamically allocates memory for storing compressed exemplars, removing less important ones to make room for new ones as the number of classes grows over time.
The authors evaluate their approach on standard food classification benchmarks, demonstrating improved performance compared to baseline continual learning methods that do not leverage compressed exemplars. They also analyze the trade-offs between exemplar compression, memory usage, and classification accuracy.
Critical Analysis
The proposed compressed exemplar approach is a compelling solution to the continual learning problem in food classification. By compactly representing past knowledge, the model can efficiently incorporate new classes without catastrophic forgetting, a common issue in many continual learning settings.
However, the authors acknowledge several limitations and avenues for future work:
- The exemplar compression method requires careful hyperparameter tuning to balance accuracy and memory usage.
- The current approach assumes a fixed set of food classes, whereas real-world systems may need to handle open-ended class expansion.
- Evaluating the method on more diverse and challenging food datasets could provide additional insights.
Additionally, one could question the reliance on a VAE-based compression scheme, as other techniques like prototypical networks or meta-learning might offer alternative approaches to efficient exemplar storage and retrieval.
Overall, this work presents a promising step towards more realistic continual learning systems for food image classification, with opportunities to further refine and expand the core ideas.
Conclusion
This paper introduces a novel continual learning framework for food image classification that leverages compressed exemplars to enable efficient and scalable incremental learning. By compactly representing past knowledge, the model can quickly adapt to new food classes without forgetting previous ones - a critical capability for real-world food recognition systems.
The compressed exemplar approach offers a promising direction for addressing the challenges of continual learning in computer vision, with potential applications beyond just food classification. As the world of food continues to evolve, this type of adaptive and memory-efficient learning will become increasingly important for maintaining robust and up-to-date AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning to Classify New Foods Incrementally Via Compressed Exemplars
Justin Yang, Zhihao Duan, Jiangpeng He, Fengqing Zhu
Food image classification systems play a crucial role in health monitoring and diet tracking through image-based dietary assessment techniques. However, existing food recognition systems rely on static datasets characterized by a pre-defined fixed number of food classes. This contrasts drastically with the reality of food consumption, which features constantly changing data. Therefore, food image classification systems should adapt to and manage data that continuously evolves. This is where continual learning plays an important role. A challenge in continual learning is catastrophic forgetting, where ML models tend to discard old knowledge upon learning new information. While memory-replay algorithms have shown promise in mitigating this problem by storing old data as exemplars, they are hampered by the limited capacity of memory buffers, leading to an imbalance between new and previously learned data. To address this, our work explores the use of neural image compression to extend buffer size and enhance data diversity. We introduced the concept of continuously learning a neural compression model to adaptively improve the quality of compressed data and optimize the bitrates per pixel (bpp) to store more exemplars. Our extensive experiments, including evaluations on food-specific datasets including Food-101 and VFN-74, as well as the general dataset ImageNet-100, demonstrate improvements in classification accuracy. This progress is pivotal in advancing more realistic food recognition systems that are capable of adapting to continually evolving data. Moreover, the principles and methodologies we've developed hold promise for broader applications, extending their benefits to other domains of continual machine learning systems.
Read more4/12/2024
✨
0
Feature Expansion and enhanced Compression for Class Incremental Learning
Quentin Ferdinand (ENSTA Bretagne, Lab-STICC_MATRIX), Gilles Le Chenadec (ENSTA Bretagne, Lab-STICC_MATRIX), Benoit Clement (CROSSING, ENSTA Bretagne, Lab-STICC_MATRIX), Panagiotis Papadakis (Lab-STICC_RAMBO, IMT Atlantique - INFO), Quentin Oliveau
Class incremental learning consists in training discriminative models to classify an increasing number of classes over time. However, doing so using only the newly added class data leads to the known problem of catastrophic forgetting of the previous classes. Recently, dynamic deep learning architectures have been shown to exhibit a better stability-plasticity trade-off by dynamically adding new feature extractors to the model in order to learn new classes followed by a compression step to scale the model back to its original size, thus avoiding a growing number of parameters. In this context, we propose a new algorithm that enhances the compression of previous class knowledge by cutting and mixing patches of previous class samples with the new images during compression using our Rehearsal-CutMix method. We show that this new data augmentation reduces catastrophic forgetting by specifically targeting past class information and improving its compression. Extensive experiments performed on the CIFAR and ImageNet datasets under diverse incremental learning evaluation protocols demonstrate that our approach consistently outperforms the state-of-the-art . The code will be made available upon publication of our work.
Read more5/15/2024

0
FMiFood: Multi-modal Contrastive Learning for Food Image Classification
Xinyue Pan, Jiangpeng He, Fengqing Zhu
Food image classification is the fundamental step in image-based dietary assessment, which aims to estimate participants' nutrient intake from eating occasion images. A common challenge of food images is the intra-class diversity and inter-class similarity, which can significantly hinder classification performance. To address this issue, we introduce a novel multi-modal contrastive learning framework called FMiFood, which learns more discriminative features by integrating additional contextual information, such as food category text descriptions, to enhance classification accuracy. Specifically, we propose a flexible matching technique that improves the similarity matching between text and image embeddings to focus on multiple key information. Furthermore, we incorporate the classification objectives into the framework and explore the use of GPT-4 to enrich the text descriptions and provide more detailed context. Our method demonstrates improved performance on both the UPMC-101 and VFN datasets compared to existing methods.
Read more8/9/2024
👁️
0
Expanding continual few-shot learning benchmarks to include recognition of specific instances
Gideon Kowadlo, Abdelrahman Ahmed, Amir Mayan, David Rawlinson
Continual learning and few-shot learning are important frontiers in progress toward broader Machine Learning (ML) capabilities. Recently, there has been intense interest in combining both. One of the first examples to do so was the Continual few-shot Learning (CFSL) framework of Antoniou et al. arXiv:2004.11967. In this study, we extend CFSL in two ways that capture a broader range of challenges, important for intelligent agent behaviour in real-world conditions. First, we increased the number of classes by an order of magnitude, making the results more comparable to standard continual learning experiments. Second, we introduced an 'instance test' which requires recognition of specific instances of classes -- a capability of animal cognition that is usually neglected in ML. For an initial exploration of ML model performance under these conditions, we selected representative baseline models from the original CFSL work and added a model variant with replay. As expected, learning more classes is more difficult than the original CFSL experiments, and interestingly, the way in which image instances and classes are presented affects classification performance. Surprisingly, accuracy in the baseline instance test is comparable to other classification tasks, but poor given significant occlusion and noise. The use of replay for consolidation substantially improves performance for both types of tasks, but particularly for the instance test.
Read more7/10/2024