Feature selection in linear SVMs via hard cardinality constraint: a scalable SDP decomposition approach
2404.10099
0
0

Abstract
In this paper, we study the embedded feature selection problem in linear Support Vector Machines (SVMs), in which a cardinality constraint is employed, leading to a fully explainable selection model. The problem is NP-hard due to the presence of the cardinality constraint, even though the original linear SVM amounts to a problem solvable in polynomial time. To handle the hard problem, we first introduce two mixed-integer formulations for which novel SDP relaxations are proposed. Exploiting the sparsity pattern of the relaxations, we decompose the problems and obtain equivalent relaxations in a much smaller cone, making the conic approaches scalable. To make the best usage of the decomposed relaxations, we propose heuristics using the information of its optimal solution. Moreover, an exact procedure is proposed by solving a sequence of mixed-integer decomposed SDPs. Numerical results on classical benchmarking datasets are reported, showing the efficiency and effectiveness of our approach.
Create account to get full access
Overview
- This research paper proposes a scalable approach to feature selection in linear support vector machines (SVMs) using a hard cardinality constraint.
- The method aims to identify a small subset of relevant features while maintaining the performance of the SVM model.
- The authors introduce a novel semidefinite programming (SDP) decomposition technique to solve the optimization problem efficiently.
Plain English Explanation
Feature selection is an important step in machine learning, as it helps identify the most relevant input variables for a given task. This is particularly crucial when working with high-dimensional data, where there may be many potential features that could be used, but only a few are truly informative.
In this paper, the researchers tackle the problem of feature selection for linear SVM models. The key idea is to impose a "hard" constraint on the number of features that can be selected, rather than using a more traditional "soft" penalty approach. This means the model is explicitly encouraged to use only a small subset of the available features, which can lead to better interpretability and generalization performance.
To solve this optimization problem efficiently, the researchers developed a novel semidefinite programming (SDP) decomposition technique. SDP is a powerful mathematical optimization framework, but it can be computationally expensive, especially for large-scale problems. The authors' decomposition approach helps make the optimization more scalable, allowing the method to be applied to real-world datasets.
Technical Explanation
The authors formulate the feature selection problem for linear SVMs as an optimization task with a hard cardinality constraint on the number of selected features. Mathematically, this can be expressed as:
min_w 1/2 ‖w‖^2 + C ∑_i ℓ(w; x_i, y_i) s.t. ‖w‖_0 ≤ k
Where w is the weight vector, ℓ(·) is the hinge loss function, and k is the desired number of selected features.
To solve this problem efficiently, the authors propose a semidefinite programming (SDP) decomposition approach. They show that the original non-convex optimization problem can be reformulated as an SDP, which can then be decomposed into smaller, more manageable subproblems. This decomposition strategy helps to make the optimization scalable to large-scale datasets.
The authors evaluate their approach on several benchmark datasets and compare it to other feature selection methods for linear SVMs. The results demonstrate that the proposed SDP-based approach can achieve competitive classification performance while selecting a much smaller number of features compared to the baseline methods.
Critical Analysis
The proposed SDP-based feature selection method is a promising approach that addresses an important problem in machine learning. The authors have demonstrated its effectiveness on several datasets, and the scalable optimization strategy is a key contribution.
However, the paper does not discuss potential limitations or caveats of the method. For example, it would be useful to understand the sensitivity of the approach to the choice of the cardinality constraint k, or how it might perform on datasets with different characteristics (e.g., very high-dimensional or highly correlated features).
Additionally, while the authors claim that the selected features are more "interpretable," they do not provide a thorough analysis or user study to substantiate this claim. Evaluating the interpretability of the selected features from the end-user's perspective would be an important next step.
Conclusion
This research paper presents a novel approach to feature selection for linear SVMs, using a hard cardinality constraint and a scalable SDP decomposition technique. The method shows promising results in terms of classification performance and the number of selected features, suggesting it could be a valuable tool for working with high-dimensional data.
Future work could explore the robustness and generalization of the approach, as well as the interpretability of the selected features from an end-user perspective. Overall, this research contributes to the ongoing efforts to develop efficient and effective feature selection methods for machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Actively Learning Combinatorial Optimization Using a Membership Oracle
Rosario Messana, Rui Chen, Andrea Lodi
0
0
We consider solving a combinatorial optimization problem with an unknown linear constraint using a membership oracle that, given a solution, determines whether it is feasible or infeasible with absolute certainty. The goal of the decision maker is to find the best possible solution subject to a budget on the number of oracle calls. Inspired by active learning based on Support Vector Machines (SVMs), we adapt a classical framework in order to solve the problem by learning and exploiting a surrogate linear constraint. The resulting new framework includes training a linear separator on the labeled points and selecting new points to be labeled, which is achieved by applying a sampling strategy and solving a 0-1 integer linear program. Following the active learning literature, one can consider using SVM as a linear classifier and the information-based sampling strategy known as Simple margin. We improve on both sides: we propose an alternative sampling strategy based on mixed-integer quadratic programming and a linear separation method inspired by an algorithm for convex optimization in the oracle model. We conduct experiments on the pure knapsack problem and on a college study plan problem from the literature to show how different linear separation methods and sampling strategies influence the quality of the results in terms of objective value.
5/24/2024
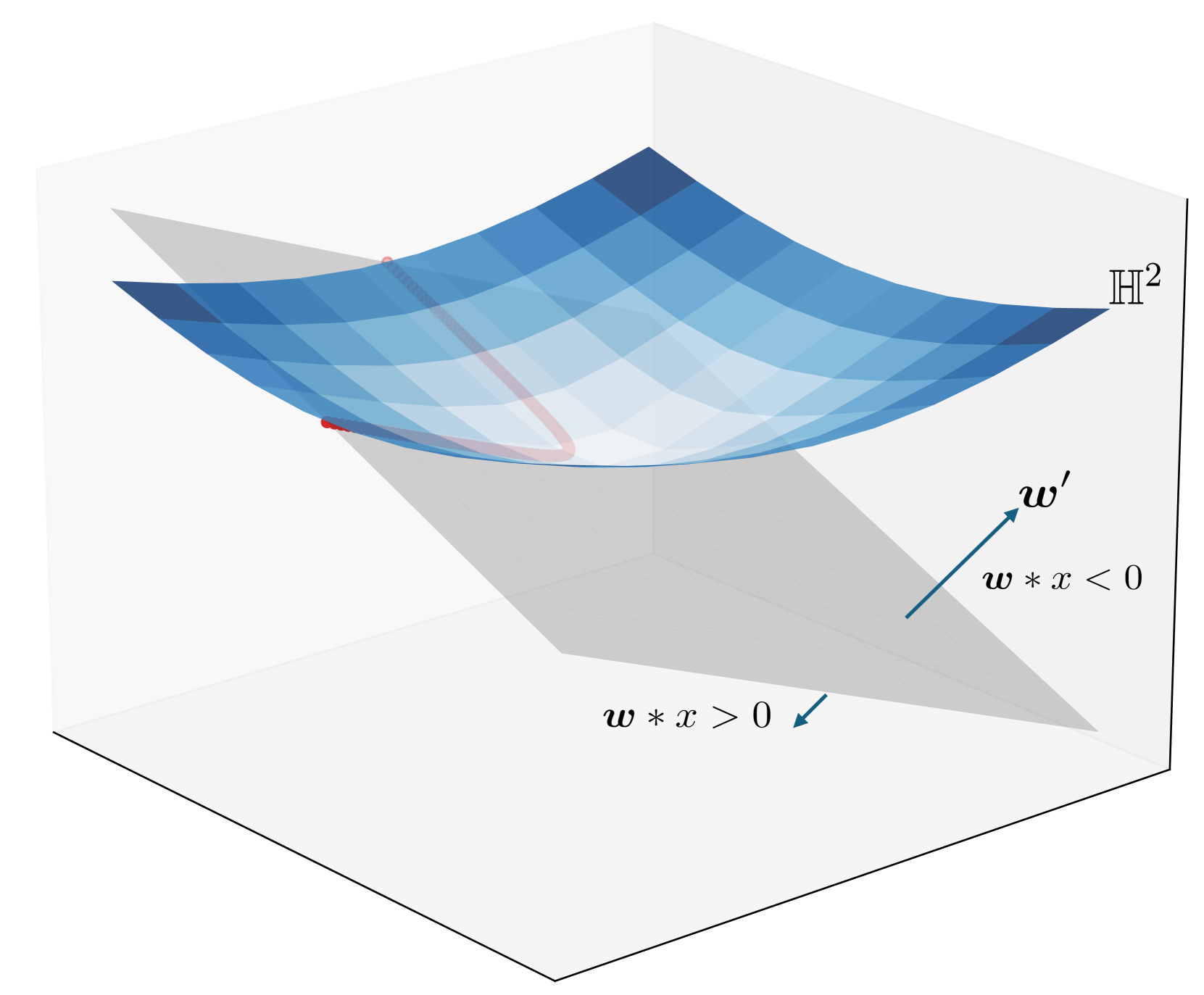
Convex Relaxation for Solving Large-Margin Classifiers in Hyperbolic Space
Sheng Yang, Peihan Liu, Cengiz Pehlevan
0
0
Hyperbolic spaces have increasingly been recognized for their outstanding performance in handling data with inherent hierarchical structures compared to their Euclidean counterparts. However, learning in hyperbolic spaces poses significant challenges. In particular, extending support vector machines to hyperbolic spaces is in general a constrained non-convex optimization problem. Previous and popular attempts to solve hyperbolic SVMs, primarily using projected gradient descent, are generally sensitive to hyperparameters and initializations, often leading to suboptimal solutions. In this work, by first rewriting the problem into a polynomial optimization, we apply semidefinite relaxation and sparse moment-sum-of-squares relaxation to effectively approximate the optima. From extensive empirical experiments, these methods are shown to perform better than the projected gradient descent approach.
5/28/2024

Using Constraints to Discover Sparse and Alternative Subgroup Descriptions
Jakob Bach
0
0
Subgroup-discovery methods allow users to obtain simple descriptions of interesting regions in a dataset. Using constraints in subgroup discovery can enhance interpretability even further. In this article, we focus on two types of constraints: First, we limit the number of features used in subgroup descriptions, making the latter sparse. Second, we propose the novel optimization problem of finding alternative subgroup descriptions, which cover a similar set of data objects as a given subgroup but use different features. We describe how to integrate both constraint types into heuristic subgroup-discovery methods. Further, we propose a novel Satisfiability Modulo Theories (SMT) formulation of subgroup discovery as a white-box optimization problem, which allows solver-based search for subgroups and is open to a variety of constraint types. Additionally, we prove that both constraint types lead to an NP-hard optimization problem. Finally, we employ 27 binary-classification datasets to compare heuristic and solver-based search for unconstrained and constrained subgroup discovery. We observe that heuristic search methods often yield high-quality subgroups within a short runtime, also in scenarios with constraints.
6/4/2024

Suboptimality bounds for trace-bounded SDPs enable a faster and scalable low-rank SDP solver SDPLR+
Yufan Huang, David F. Gleich
0
0
Semidefinite programs (SDPs) and their solvers are powerful tools with many applications in machine learning and data science. Designing scalable SDP solvers is challenging because by standard the positive semidefinite decision variable is an $n times n$ dense matrix, even though the input is often an $n times n$ sparse matrix. However, the information in the solution may not correspond to a full-rank dense matrix as shown by Bavinok and Pataki. Two decades ago, Burer and Monterio developed an SDP solver $texttt{SDPLR}$ that optimizes over a low-rank factorization instead of the full matrix. This greatly decreases the storage cost and works well for many problems. The original solver $texttt{SDPLR}$ tracks only the primal infeasibility of the solution, limiting the technique's flexibility to produce moderate accuracy solutions. We use a suboptimality bound for trace-bounded SDP problems that enables us to track the progress better and perform early termination. We then develop $texttt{SDPLR+}$, which starts the optimization with an extremely low-rank factorization and dynamically updates the rank based on the primal infeasibility and suboptimality. This further speeds up the computation and saves the storage cost. Numerical experiments on Max Cut, Minimum Bisection, Cut Norm, and Lov'{a}sz Theta problems with many recent memory-efficient scalable SDP solvers demonstrate its scalability up to problems with million-by-million decision variables and it is often the fastest solver to a moderate accuracy of $10^{-2}$.
6/18/2024