Federated Automatic Latent Variable Selection in Multi-output Gaussian Processes

0

Sign in to get full access
Overview
- Federated Automatic Latent Variable Selection in Multi-output Gaussian Processes
- Focuses on multi-output Gaussian processes and federated learning
- Proposes a method for automatically selecting relevant latent variables in a federated setting
Plain English Explanation
This paper presents a technique for multi-output Gaussian processes in a federated learning scenario. The key idea is to automatically identify the most relevant latent variables to include in the model, rather than having to manually select them.
In a federated setting, data is distributed across multiple devices or locations, and the model is trained collaboratively without sharing the raw data. The authors' method allows the model to automatically determine which latent variables are important for each task, rather than relying on the user to make that decision.
This can be useful in heterogenous multi-source data fusion scenarios, where there are multiple input sources and it's not always clear which features are most relevant. The automatic latent variable selection can help the model focus on the most informative aspects of the data.
Technical Explanation
The paper proposes a Federated Automatic Latent Variable Selection (FALVS) method for multi-output Gaussian processes. It uses spike-and-slab priors to automatically determine the relevance of each latent variable for each output task.
The federated setting allows the model to be trained collaboratively across multiple devices or locations without sharing raw data. The automatic latent variable selection helps the model focus on the most informative aspects of the data for each task, rather than relying on manual feature engineering.
The authors evaluate their method on several benchmark datasets and show that it outperforms alternative approaches, particularly in scenarios with heterogeneous or high-dimensional data.
Critical Analysis
The paper presents a novel and promising approach for multi-output Gaussian processes in a federated setting. The automatic latent variable selection is a valuable contribution, as it can help reduce the burden of manual feature engineering.
However, the paper does not extensively discuss the computational complexity of the proposed method, which could be a concern in real-world federated learning scenarios with limited device resources. Additionally, the authors only evaluate the method on relatively small-scale benchmark datasets, and further research may be needed to assess its performance on larger, more diverse datasets.
Finally, while the paper mentions potential applications in areas like healthcare and finance, it does not delve into the broader societal implications or potential ethical considerations of the technology, which could be an important area for future research.
Conclusion
This paper introduces a novel method for Federated Automatic Latent Variable Selection (FALVS) in multi-output Gaussian processes. The key innovation is the ability to automatically determine the relevant latent variables for each output task in a federated learning setting, without the need for manual feature engineering.
The proposed approach shows promising results on benchmark datasets and could be a valuable tool for heterogeneous multi-source data fusion scenarios. Further research is needed to assess the method's scalability and explore its broader implications, but this work represents an important step forward in the field of federated learning and multi-output Gaussian processes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Federated Automatic Latent Variable Selection in Multi-output Gaussian Processes
Jingyi Gao, Seokhyun Chung
This paper explores a federated learning approach that automatically selects the number of latent processes in multi-output Gaussian processes (MGPs). The MGP has seen great success as a transfer learning tool when data is generated from multiple sources/units/entities. A common approach in MGPs to transfer knowledge across units involves gathering all data from each unit to a central server and extracting common independent latent processes to express each unit as a linear combination of the shared latent patterns. However, this approach poses key challenges in (i) determining the adequate number of latent processes and (ii) relying on centralized learning which leads to potential privacy risks and significant computational burdens on the central server. To address these issues, we propose a hierarchical model that places spike-and-slab priors on the coefficients of each latent process. These priors help automatically select only needed latent processes by shrinking the coefficients of unnecessary ones to zero. To estimate the model while avoiding the drawbacks of centralized learning, we propose a variational inference-based approach, that formulates model inference as an optimization problem compatible with federated settings. We then design a federated learning algorithm that allows units to jointly select and infer the common latent processes without sharing their data. We also discuss an efficient learning approach for a new unit within our proposed federated framework. Simulation and case studies on Li-ion battery degradation and air temperature data demonstrate the advantageous features of our proposed approach.
Read more7/25/2024

0
Interpretable Multi-Source Data Fusion Through Latent Variable Gaussian Process
Sandipp Krishnan Ravi, Yigitcan Comlek, Wei Chen, Arjun Pathak, Vipul Gupta, Rajnikant Umretiya, Andrew Hoffman, Ghanshyam Pilania, Piyush Pandita, Sayan Ghosh, Nathaniel Mckeever, Liping Wang
With the advent of artificial intelligence (AI) and machine learning (ML), various domains of science and engineering communites has leveraged data-driven surrogates to model complex systems from numerous sources of information (data). The proliferation has led to significant reduction in cost and time involved in development of superior systems designed to perform specific functionalities. A high proposition of such surrogates are built extensively fusing multiple sources of data, may it be published papers, patents, open repositories, or other resources. However, not much attention has been paid to the differences in quality and comprehensiveness of the known and unknown underlying physical parameters of the information sources that could have downstream implications during system optimization. Towards resolving this issue, a multi-source data fusion framework based on Latent Variable Gaussian Process (LVGP) is proposed. The individual data sources are tagged as a characteristic categorical variable that are mapped into a physically interpretable latent space, allowing the development of source-aware data fusion modeling. Additionally, a dissimilarity metric based on the latent variables of LVGP is introduced to study and understand the differences in the sources of data. The proposed approach is demonstrated on and analyzed through two mathematical (representative parabola problem, 2D Ackley function) and two materials science (design of FeCrAl and SmCoFe alloys) case studies. From the case studies, it is observed that compared to using single-source and source unaware ML models, the proposed multi-source data fusion framework can provide better predictions for sparse-data problems, interpretability regarding the sources, and enhanced modeling capabilities by taking advantage of the correlations and relationships among different sources.
Read more7/17/2024

0
Heterogenous Multi-Source Data Fusion Through Input Mapping and Latent Variable Gaussian Process
Yigitcan Comlek, Sandipp Krishnan Ravi, Piyush Pandita, Sayan Ghosh, Liping Wang, Wei Chen
Artificial intelligence and machine learning frameworks have served as computationally efficient mapping between inputs and outputs for engineering problems. These mappings have enabled optimization and analysis routines that have warranted superior designs, ingenious material systems and optimized manufacturing processes. A common occurrence in such modeling endeavors is the existence of multiple source of data, each differentiated by fidelity, operating conditions, experimental conditions, and more. Data fusion frameworks have opened the possibility of combining such differentiated sources into single unified models, enabling improved accuracy and knowledge transfer. However, these frameworks encounter limitations when the different sources are heterogeneous in nature, i.e., not sharing the same input parameter space. These heterogeneous input scenarios can occur when the domains differentiated by complexity, scale, and fidelity require different parametrizations. Towards addressing this void, a heterogeneous multi-source data fusion framework is proposed based on input mapping calibration (IMC) and latent variable Gaussian process (LVGP). In the first stage, the IMC algorithm is utilized to transform the heterogeneous input parameter spaces into a unified reference parameter space. In the second stage, a multi-source data fusion model enabled by LVGP is leveraged to build a single source-aware surrogate model on the transformed reference space. The proposed framework is demonstrated and analyzed on three engineering case studies (design of cantilever beam, design of ellipsoidal void and modeling properties of Ti6Al4V alloy). The results indicate that the proposed framework provides improved predictive accuracy over a single source model and transformed but source unaware model.
Read more7/17/2024
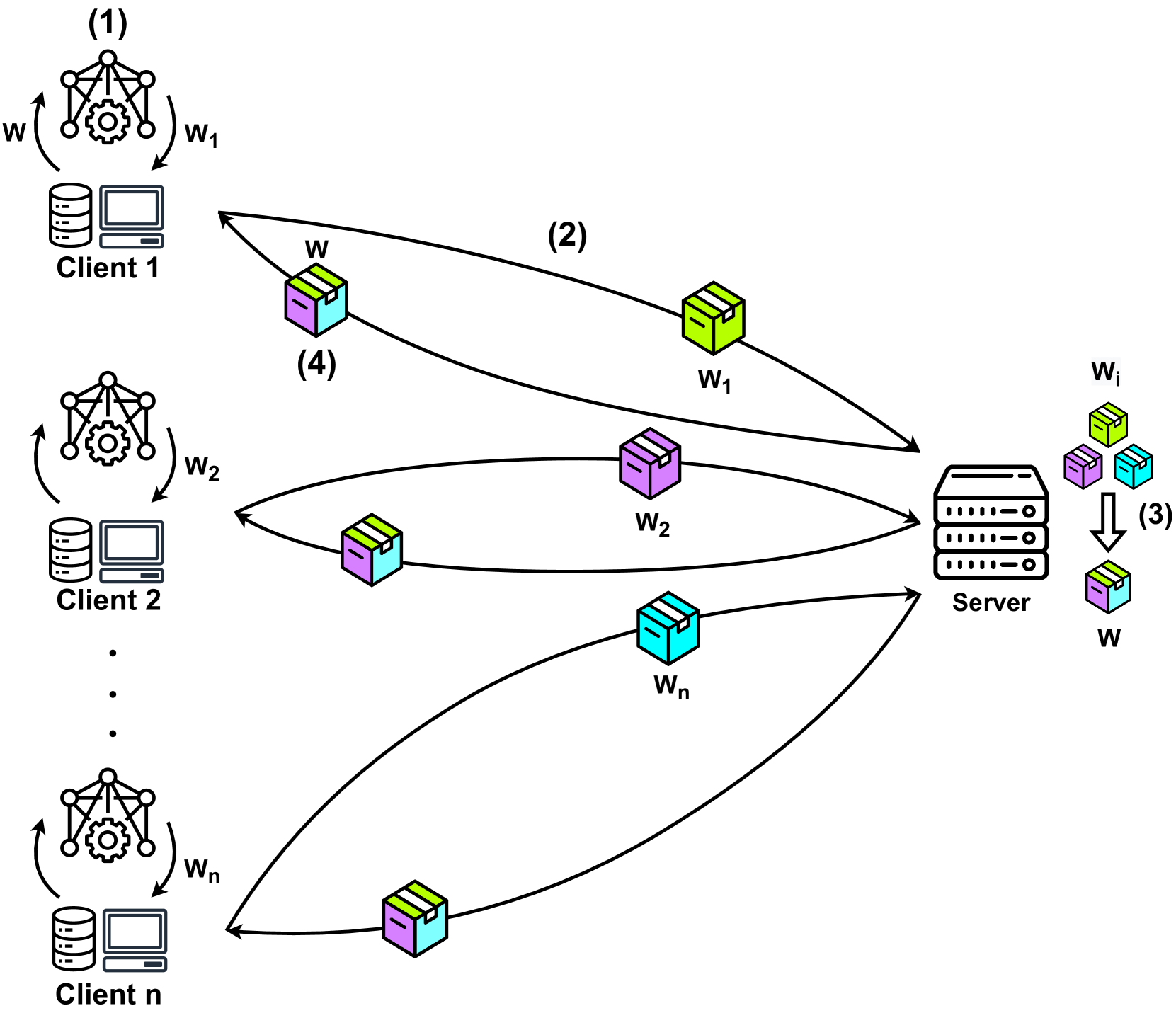
0
Federated Learning for Misbehaviour Detection with Variational Autoencoders and Gaussian Mixture Models
Enrique M'armol Campos, Aurora Gonz'alez Vidal, Jos'e Luis Hern'andez Ramos, Antonio Skarmeta
Federated Learning (FL) has become an attractive approach to collaboratively train Machine Learning (ML) models while data sources' privacy is still preserved. However, most of existing FL approaches are based on supervised techniques, which could require resource-intensive activities and human intervention to obtain labelled datasets. Furthermore, in the scope of cyberattack detection, such techniques are not able to identify previously unknown threats. In this direction, this work proposes a novel unsupervised FL approach for the identification of potential misbehavior in vehicular environments. We leverage the computing capabilities of public cloud services for model aggregation purposes, and also as a central repository of misbehavior events, enabling cross-vehicle learning and collective defense strategies. Our solution integrates the use of Gaussian Mixture Models (GMM) and Variational Autoencoders (VAE) on the VeReMi dataset in a federated environment, where each vehicle is intended to train only with its own data. Furthermore, we use Restricted Boltzmann Machines (RBM) for pre-training purposes, and Fedplus as aggregation function to enhance model's convergence. Our approach provides better performance (more than 80 percent) compared to recent proposals, which are usually based on supervised techniques and artificial divisions of the VeReMi dataset.
Read more5/17/2024