Federated Learning driven Large Language Models for Swarm Intelligence: A Survey
2406.09831
0
0
Abstract
Federated learning (FL) offers a compelling framework for training large language models (LLMs) while addressing data privacy and decentralization challenges. This paper surveys recent advancements in the federated learning of large language models, with a particular focus on machine unlearning, a crucial aspect for complying with privacy regulations like the Right to be Forgotten. Machine unlearning in the context of federated LLMs involves systematically and securely removing individual data contributions from the learned model without retraining from scratch. We explore various strategies that enable effective unlearning, such as perturbation techniques, model decomposition, and incremental learning, highlighting their implications for maintaining model performance and data privacy. Furthermore, we examine case studies and experimental results from recent literature to assess the effectiveness and efficiency of these approaches in real-world scenarios. Our survey reveals a growing interest in developing more robust and scalable federated unlearning methods, suggesting a vital area for future research in the intersection of AI ethics and distributed machine learning technologies.
Create account to get full access
Overview
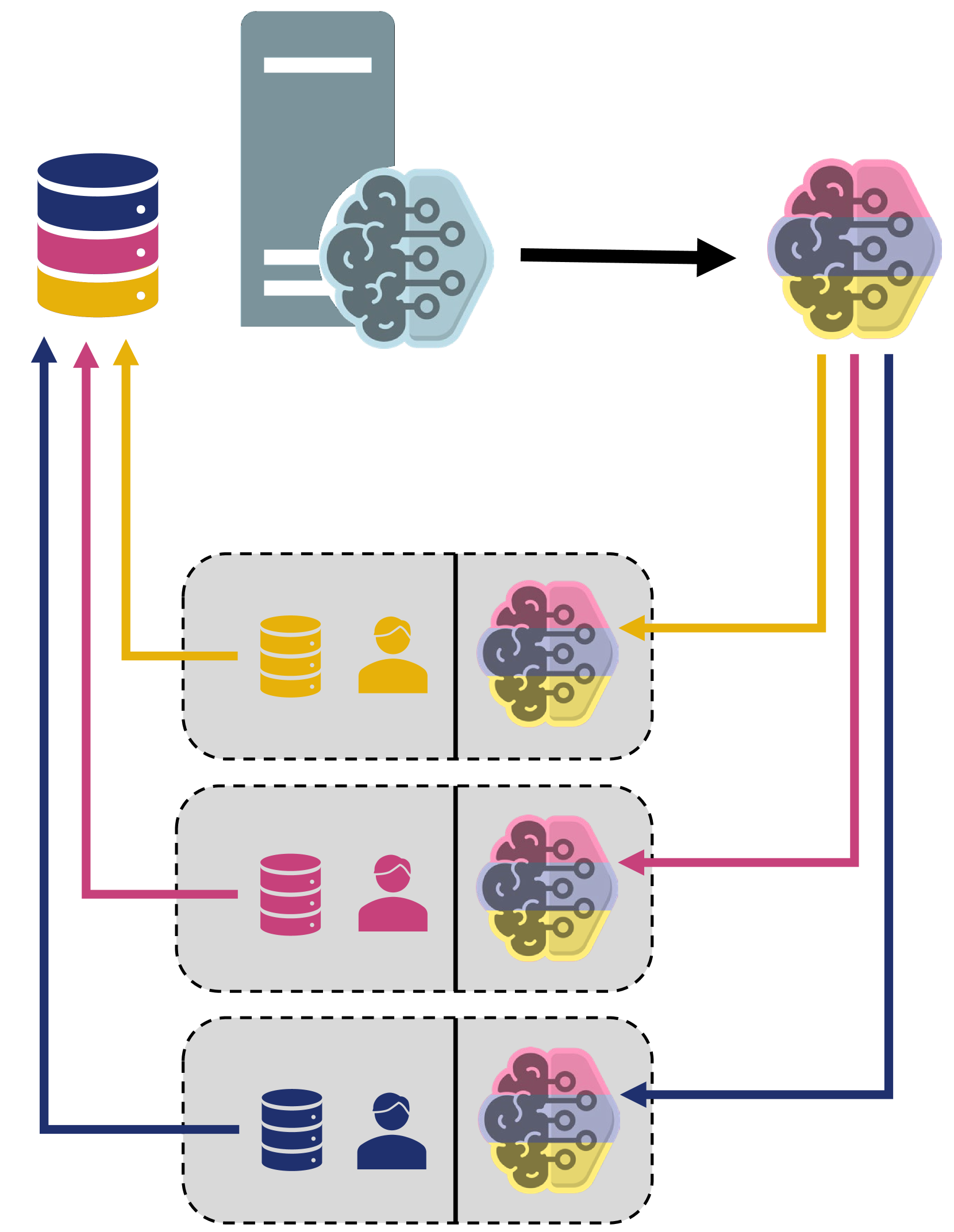
• This paper provides a comprehensive survey of the integration of federated learning (FL) and large language models (LLMs) to enable swarm intelligence (SI) applications.
• The paper discusses the foundations of SI and LLMs, how they can be combined to leverage their respective strengths, and the key challenges and opportunities in this emerging field.
Plain English Explanation
The paper explores the exciting intersection of federated learning, large language models, and swarm intelligence. Federated learning allows AI models to be trained collaboratively across many devices without centralizing the data. Large language models are powerful AI systems that can understand and generate human-like text. Swarm intelligence refers to the collective behavior of decentralized, self-organized systems, like ant colonies or bird flocks.
The paper explains how combining these three elements can create advanced AI systems that can solve complex problems in a distributed, adaptive, and intelligent way. For example, a swarm of robots could use federated learning and large language models to coordinate their actions, share knowledge, and respond to dynamic environments. This could be useful for applications like search and rescue, environmental monitoring, or logistics optimization.
Technical Explanation
The paper first provides an overview of the foundations of SI and LLMs, explaining how they can complement each other. It then delves into the key technical challenges and design considerations in integrating these two paradigms, such as:
- Model architectures and training techniques to enable decentralized, collaborative learning within a swarm
- Communication protocols and coordination mechanisms to facilitate efficient information sharing and decision-making
- Privacy-preserving techniques to protect sensitive data within the swarm
- Scalability and robustness considerations as the swarm size and complexity increases
The paper also discusses several promising application domains, such as robotic swarms, edge computing, and complex systems modeling, and outlines future research directions in this emerging field.
Critical Analysis
The paper provides a thorough and well-structured overview of the opportunities and challenges in integrating federated learning and large language models for swarm intelligence applications. However, the authors acknowledge several limitations and open questions, such as:
- The complexity of designing effective communication and coordination protocols for large-scale swarms
- The potential for security and privacy vulnerabilities in decentralized systems
- The computational and memory constraints of deploying LLMs on resource-constrained edge devices
- The need for more comprehensive benchmarking and evaluation frameworks to assess the performance of these hybrid systems
Additionally, while the paper covers a broad range of technical aspects, it could have delved deeper into specific algorithmic innovations or empirical evaluations to provide more concrete insights for researchers and practitioners in this field.
Conclusion
This survey paper offers a comprehensive, well-researched look at the intersection of federated learning, large language models, and swarm intelligence. By combining these cutting-edge AI technologies, researchers can unlock new possibilities for collaborative, adaptive, and intelligent systems that can tackle complex real-world challenges. The paper provides a solid foundation for further exploration and development in this promising area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
SoK: Challenges and Opportunities in Federated Unlearning
Hyejun Jeong, Shiqing Ma, Amir Houmansadr
0
0
Federated learning (FL), introduced in 2017, facilitates collaborative learning between non-trusting parties with no need for the parties to explicitly share their data among themselves. This allows training models on user data while respecting privacy regulations such as GDPR and CPRA. However, emerging privacy requirements may mandate model owners to be able to emph{forget} some learned data, e.g., when requested by data owners or law enforcement. This has given birth to an active field of research called emph{machine unlearning}. In the context of FL, many techniques developed for unlearning in centralized settings are not trivially applicable! This is due to the unique differences between centralized and distributed learning, in particular, interactivity, stochasticity, heterogeneity, and limited accessibility in FL. In response, a recent line of work has focused on developing unlearning mechanisms tailored to FL. This SoK paper aims to take a deep look at the emph{federated unlearning} literature, with the goal of identifying research trends and challenges in this emerging field. By carefully categorizing papers published on FL unlearning (since 2020), we aim to pinpoint the unique complexities of federated unlearning, highlighting limitations on directly applying centralized unlearning methods. We compare existing federated unlearning methods regarding influence removal and performance recovery, compare their threat models and assumptions, and discuss their implications and limitations. For instance, we analyze the experimental setup of FL unlearning studies from various perspectives, including data heterogeneity and its simulation, the datasets used for demonstration, and evaluation metrics. Our work aims to offer insights and suggestions for future research on federated unlearning.
6/7/2024
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
0
0
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
5/28/2024
🏅
Unlearning during Learning: An Efficient Federated Machine Unlearning Method
Hanlin Gu, Gongxi Zhu, Jie Zhang, Xinyuan Zhao, Yuxing Han, Lixin Fan, Qiang Yang
0
0
In recent years, Federated Learning (FL) has garnered significant attention as a distributed machine learning paradigm. To facilitate the implementation of the right to be forgotten, the concept of federated machine unlearning (FMU) has also emerged. However, current FMU approaches often involve additional time-consuming steps and may not offer comprehensive unlearning capabilities, which renders them less practical in real FL scenarios. In this paper, we introduce FedAU, an innovative and efficient FMU framework aimed at overcoming these limitations. Specifically, FedAU incorporates a lightweight auxiliary unlearning module into the learning process and employs a straightforward linear operation to facilitate unlearning. This approach eliminates the requirement for extra time-consuming steps, rendering it well-suited for FL. Furthermore, FedAU exhibits remarkable versatility. It not only enables multiple clients to carry out unlearning tasks concurrently but also supports unlearning at various levels of granularity, including individual data samples, specific classes, and even at the client level. We conducted extensive experiments on MNIST, CIFAR10, and CIFAR100 datasets to evaluate the performance of FedAU. The results demonstrate that FedAU effectively achieves the desired unlearning effect while maintaining model accuracy.
5/27/2024

Safely Learning with Private Data: A Federated Learning Framework for Large Language Model
JiaYing Zheng, HaiNan Zhang, LingXiang Wang, WangJie Qiu, HongWei Zheng, ZhiMing Zheng
0
0
Private data, being larger and quality-higher than public data, can greatly improve large language models (LLM). However, due to privacy concerns, this data is often dispersed in multiple silos, making its secure utilization for LLM training a challenge. Federated learning (FL) is an ideal solution for training models with distributed private data, but traditional frameworks like FedAvg are unsuitable for LLM due to their high computational demands on clients. An alternative, split learning, offloads most training parameters to the server while training embedding and output layers locally, making it more suitable for LLM. Nonetheless, it faces significant challenges in security and efficiency. Firstly, the gradients of embeddings are prone to attacks, leading to potential reverse engineering of private data. Furthermore, the server's limitation of handle only one client's training request at a time hinders parallel training, severely impacting training efficiency. In this paper, we propose a Federated Learning framework for LLM, named FL-GLM, which prevents data leakage caused by both server-side and peer-client attacks while improving training efficiency. Specifically, we first place the input block and output block on local client to prevent embedding gradient attacks from server. Secondly, we employ key-encryption during client-server communication to prevent reverse engineering attacks from peer-clients. Lastly, we employ optimization methods like client-batching or server-hierarchical, adopting different acceleration methods based on the actual computational capabilities of the server. Experimental results on NLU and generation tasks demonstrate that FL-GLM achieves comparable metrics to centralized chatGLM model, validating the effectiveness of our federated learning framework.
6/27/2024