FedMAP: Unlocking Potential in Personalized Federated Learning through Bi-Level MAP Optimization
2405.19000
0
0
Abstract
Federated Learning (FL) enables collaborative training of machine learning models on decentralized data while preserving data privacy. However, data across clients often differs significantly due to class imbalance, feature distribution skew, sample size imbalance, and other phenomena. Leveraging information from these not identically distributed (non-IID) datasets poses substantial challenges. FL methods based on a single global model cannot effectively capture the variations in client data and underperform in non-IID settings. Consequently, Personalized FL (PFL) approaches that adapt to each client's data distribution but leverage other clients' data are essential but currently underexplored. We propose a novel Bayesian PFL framework using bi-level optimization to tackle the data heterogeneity challenges. Our proposed framework utilizes the global model as a prior distribution within a Maximum A Posteriori (MAP) estimation of personalized client models. This approach facilitates PFL by integrating shared knowledge from the prior, thereby enhancing local model performance, generalization ability, and communication efficiency. We extensively evaluated our bi-level optimization approach on real-world and synthetic datasets, demonstrating significant improvements in model accuracy compared to existing methods while reducing communication overhead. This study contributes to PFL by establishing a solid theoretical foundation for the proposed method and offering a robust, ready-to-use framework that effectively addresses the challenges posed by non-IID data in FL.
Create account to get full access
Overview
- This paper presents a new federated learning approach called FedMAP that aims to improve personalization in federated learning settings.
- FedMAP uses a bi-level optimization approach to simultaneously learn a global model and personalized models for each client.
- The key idea is to leverage data heterogeneity across clients to learn more accurate personalized models while maintaining the benefits of federated learning.
Plain English Explanation
Federated learning is a way for multiple devices or organizations to train an AI model together without sharing their private data. This is useful when the data is spread across many different locations and can't be combined, like on people's personal phones. However, the standard federated learning approach struggles when the data on each device is very different, which is often the case in real-world applications.
The FedMAP method proposed in this paper tries to address this challenge. The key idea is to learn both a global model that works well across all the devices, as well as personalized models tailored to the unique data on each individual device. This is done through a "bi-level optimization" approach, where the global model and personalized models are optimized simultaneously.
By learning personalized models, FedMAP can better capture the unique patterns in each device's data, leading to more accurate predictions. At the same time, the global model helps ensure that the personalized models don't overfit to their local data and maintains the benefits of federated learning, like improved privacy and efficiency.
Overall, the FedMAP approach aims to unlock the full potential of federated learning by enabling more personalized models, which could lead to significant performance improvements in a wide range of real-world applications.
Technical Explanation
The FedMAP method proposed in this paper builds on previous work on personalized federated learning, such as MAP, Multi-Layer PFL, pFedAFM, and pFedER.
The key innovation of FedMAP is the use of a bi-level optimization approach to jointly learn a global model and personalized models for each client. The global model is learned by optimizing the average performance across all clients, while the personalized models are learned by optimizing the performance on each client's local data.
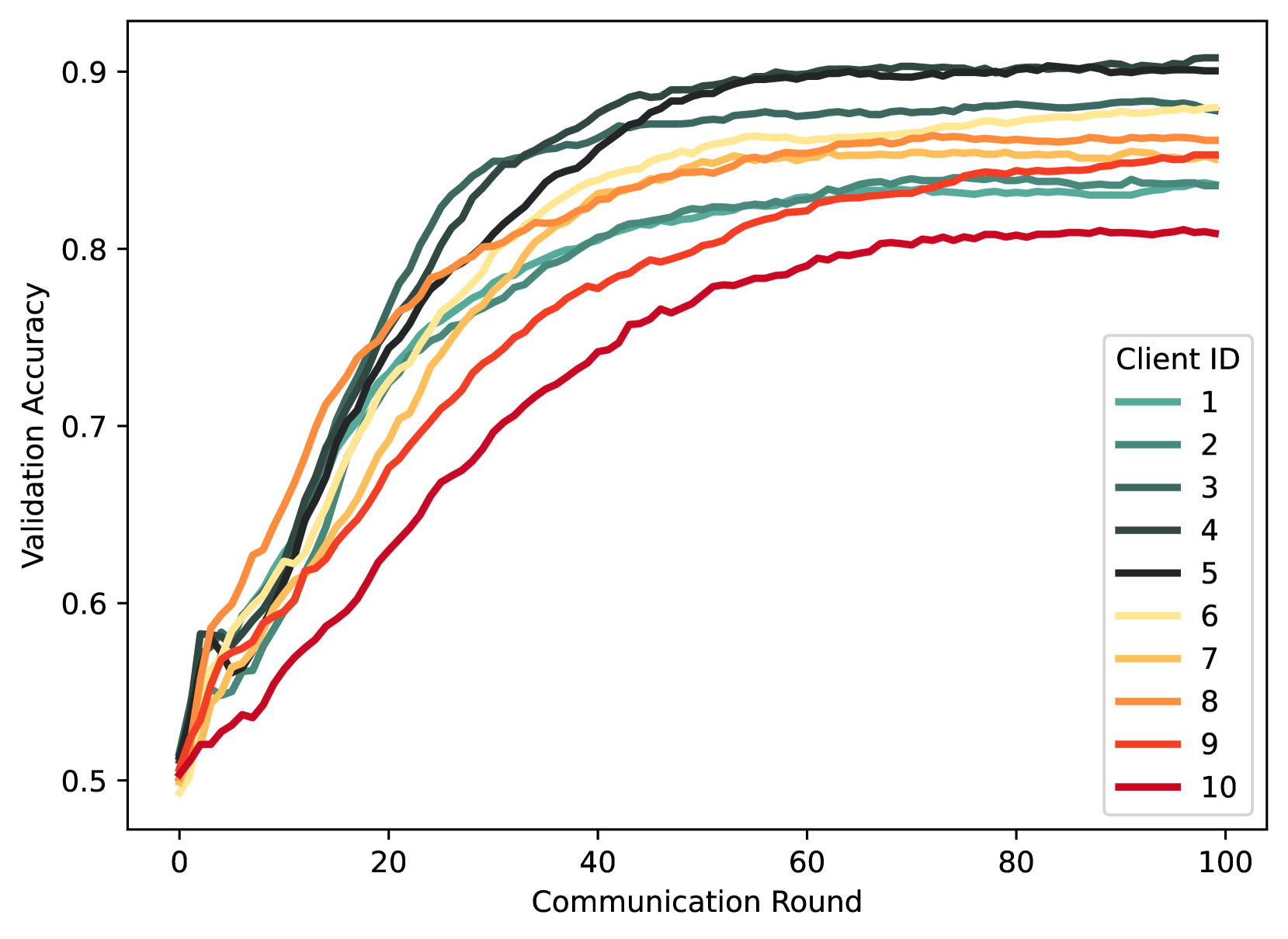
The paper presents a detailed algorithm for implementing this bi-level optimization process and analyzes its theoretical properties, including convergence guarantees. Extensive experiments on both synthetic and real-world datasets demonstrate the effectiveness of FedMAP in improving personalization and model performance compared to standard federated learning approaches.
Critical Analysis
The paper provides a thorough analysis of the FedMAP method and its advantages over previous personalized federated learning approaches. However, the authors acknowledge several limitations and areas for future research:
- The bi-level optimization process can be computationally expensive, especially as the number of clients grows. The authors suggest exploring ways to reduce the optimization complexity.
- The current FedMAP formulation assumes that the global model and personalized models share the same underlying architecture. Extending the approach to handle more flexible model structures could be an interesting direction.
- The experiments in the paper focus on relatively simple tasks and datasets. Evaluating FedMAP on more complex, real-world applications would help further validate its capabilities and practical relevance.
Additionally, one could raise the question of whether the personalized models learned by FedMAP could potentially lead to unfair or biased predictions if the client data is not representative of the overall population. The authors do not address this concern in the paper, and it would be an important aspect to consider in future research.
Conclusion
The FedMAP method proposed in this paper represents an exciting advance in the field of personalized federated learning. By leveraging a bi-level optimization approach, FedMAP can learn both global and personalized models, unlocking the potential of federated learning to deliver more accurate and tailored predictions in a wide range of applications.
The strong empirical results and thorough analysis presented in the paper suggest that FedMAP could have a significant impact, particularly in domains where data heterogeneity across clients is a major challenge. As the authors outline, further research is needed to address the computational complexity and potential bias concerns, but the core ideas behind FedMAP are a promising step forward in the quest for truly personalized and privacy-preserving machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Multi-level Personalized Federated Learning on Heterogeneous and Long-Tailed Data
Rongyu Zhang, Yun Chen, Chenrui Wu, Fangxin Wang, Bo Li
0
0
Federated learning (FL) offers a privacy-centric distributed learning framework, enabling model training on individual clients and central aggregation without necessitating data exchange. Nonetheless, FL implementations often suffer from non-i.i.d. and long-tailed class distributions across mobile applications, e.g., autonomous vehicles, which leads models to overfitting as local training may converge to sub-optimal. In our study, we explore the impact of data heterogeneity on model bias and introduce an innovative personalized FL framework, Multi-level Personalized Federated Learning (MuPFL), which leverages the hierarchical architecture of FL to fully harness computational resources at various levels. This framework integrates three pivotal modules: Biased Activation Value Dropout (BAVD) to mitigate overfitting and accelerate training; Adaptive Cluster-based Model Update (ACMU) to refine local models ensuring coherent global aggregation; and Prior Knowledge-assisted Classifier Fine-tuning (PKCF) to bolster classification and personalize models in accord with skewed local data with shared knowledge. Extensive experiments on diverse real-world datasets for image classification and semantic segmentation validate that MuPFL consistently outperforms state-of-the-art baselines, even under extreme non-i.i.d. and long-tail conditions, which enhances accuracy by as much as 7.39% and accelerates training by up to 80% at most, marking significant advancements in both efficiency and effectiveness.
5/13/2024

MAP: Model Aggregation and Personalization in Federated Learning with Incomplete Classes
Xin-Chun Li, Shaoming Song, Yinchuan Li, Bingshuai Li, Yunfeng Shao, Yang Yang, De-Chuan Zhan
0
0
In some real-world applications, data samples are usually distributed on local devices, where federated learning (FL) techniques are proposed to coordinate decentralized clients without directly sharing users' private data. FL commonly follows the parameter server architecture and contains multiple personalization and aggregation procedures. The natural data heterogeneity across clients, i.e., Non-I.I.D. data, challenges both the aggregation and personalization goals in FL. In this paper, we focus on a special kind of Non-I.I.D. scene where clients own incomplete classes, i.e., each client can only access a partial set of the whole class set. The server aims to aggregate a complete classification model that could generalize to all classes, while the clients are inclined to improve the performance of distinguishing their observed classes. For better model aggregation, we point out that the standard softmax will encounter several problems caused by missing classes and propose restricted softmax as an alternative. For better model personalization, we point out that the hard-won personalized models are not well exploited and propose inherited private model to store the personalization experience. Our proposed algorithm named MAP could simultaneously achieve the aggregation and personalization goals in FL. Abundant experimental studies verify the superiorities of our algorithm.
4/16/2024
🤔
Multi-Layer Personalized Federated Learning for Mitigating Biases in Student Predictive Analytics
Yun-Wei Chu, Seyyedali Hosseinalipour, Elizabeth Tenorio, Laura Cruz, Kerrie Douglas, Andrew Lan, Christopher Brinton
0
0
Conventional methods for student modeling, which involve predicting grades based on measured activities, struggle to provide accurate results for minority/underrepresented student groups due to data availability biases. In this paper, we propose a Multi-Layer Personalized Federated Learning (MLPFL) methodology that optimizes inference accuracy over different layers of student grouping criteria, such as by course and by demographic subgroups within each course. In our approach, personalized models for individual student subgroups are derived from a global model, which is trained in a distributed fashion via meta-gradient updates that account for subgroup heterogeneity while preserving modeling commonalities that exist across the full dataset. The evaluation of the proposed methodology considers case studies of two popular downstream student modeling tasks, knowledge tracing and outcome prediction, which leverage multiple modalities of student behavior (e.g., visits to lecture videos and participation on forums) in model training. Experiments on three real-world online course datasets show significant improvements achieved by our approach over existing student modeling benchmarks, as evidenced by an increased average prediction quality and decreased variance across different student subgroups. Visual analysis of the resulting students' knowledge state embeddings confirm that our personalization methodology extracts activity patterns clustered into different student subgroups, consistent with the performance enhancements we obtain over the baselines.
5/29/2024

Personalized Federated Learning via Stacking
Emilio Cantu-Cervini
0
0
Traditional Federated Learning (FL) methods typically train a single global model collaboratively without exchanging raw data. In contrast, Personalized Federated Learning (PFL) techniques aim to create multiple models that are better tailored to individual clients' data. We present a novel personalization approach based on stacked generalization where clients directly send each other privacy-preserving models to be used as base models to train a meta-model on private data. Our approach is flexible, accommodating various privacy-preserving techniques and model types, and can be applied in horizontal, hybrid, and vertically partitioned federations. Additionally, it offers a natural mechanism for assessing each client's contribution to the federation. Through comprehensive evaluations across diverse simulated data heterogeneity scenarios, we showcase the effectiveness of our method.
4/23/2024