FedMFS: Federated Multimodal Fusion Learning with Selective Modality Communication

0

Sign in to get full access
Overview
- Proposes a federated learning approach called FedMFS for training multimodal machine learning models across distributed devices
- Allows selective communication of modalities, enabling efficient use of limited network resources
- Outperforms existing federated multimodal learning approaches on various tasks
Plain English Explanation
FedMFS: Federated Multimodal Fusion Learning with Selective Modality Communication is a new approach for training machine learning models that use multiple data types, such as images and text, in a distributed setting where the data is spread across many devices.
The key idea is to only share the most relevant data modalities between devices, rather than transmitting all the data. This helps conserve network resources and allows the model to be trained more efficiently. The approach is called "selective modality communication," and it outperforms existing federated multimodal learning methods on a variety of tasks.
Technical Explanation
FedMFS: Federated Multimodal Fusion Learning with Selective Modality Communication proposes a federated learning framework for training multimodal machine learning models. In federated learning, a shared model is trained across many devices without the raw data ever leaving the device.
The FedMFS approach allows devices to selectively communicate only the most relevant data modalities during the federated training process, rather than transmitting all available modalities. This helps conserve network resources and enables more efficient training of multimodal models.
The framework includes several key components:
- A modality importance estimation module that determines which modalities are most relevant for the current learning task
- A selective modality communication protocol that only shares the important modalities between devices
- A multimodal fusion module that combines the received modalities to update the shared model
Experiments show that FedMFS outperforms existing federated multimodal learning approaches on tasks like image classification and sentiment analysis.
Critical Analysis
The FedMFS paper provides a promising approach for efficient federated multimodal learning, but there are a few potential limitations and areas for further research:
- The modality importance estimation module relies on heuristics and may not always accurately capture the relevance of different modalities. More sophisticated techniques could be explored.
- The experiments are limited to relatively simple multimodal tasks. Applying FedMFS to more complex, real-world multimodal problems would be an important next step.
- The paper does not consider potential privacy or security issues that may arise in federated learning settings. Addressing these concerns would be crucial for real-world deployment.
Overall, FedMFS represents an interesting advance in federated multimodal learning, but further research is needed to fully understand its capabilities and limitations.
Conclusion
FedMFS: Federated Multimodal Fusion Learning with Selective Modality Communication proposes an efficient federated learning approach for training multimodal models by selectively communicating only the most relevant data modalities. This helps conserve network resources and enables more effective training of multimodal machine learning models in distributed settings.
The approach outperforms existing federated multimodal learning methods, but there are still opportunities for improvement, such as enhancing the modality importance estimation and addressing privacy concerns. As federated learning and multimodal AI continue to advance, techniques like FedMFS will play an important role in enabling efficient and privacy-preserving real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FedMFS: Federated Multimodal Fusion Learning with Selective Modality Communication
Liangqi Yuan, Dong-Jun Han, Vishnu Pandi Chellapandi, Stanislaw H. .Zak, Christopher G. Brinton
Multimodal federated learning (FL) aims to enrich model training in FL settings where devices are collecting measurements across multiple modalities (e.g., sensors measuring pressure, motion, and other types of data). However, key challenges to multimodal FL remain unaddressed, particularly in heterogeneous network settings: (i) the set of modalities collected by each device will be diverse, and (ii) communication limitations prevent devices from uploading all their locally trained modality models to the server. In this paper, we propose Federated Multimodal Fusion learning with Selective modality communication (FedMFS), a new multimodal fusion FL methodology that can tackle the above mentioned challenges. The key idea is the introduction of a modality selection criterion for each device, which weighs (i) the impact of the modality, gauged by Shapley value analysis, against (ii) the modality model size as a gauge for communication overhead. This enables FedMFS to flexibly balance performance against communication costs, depending on resource constraints and application requirements. Experiments on the real-world ActionSense dataset demonstrate the ability of FedMFS to achieve comparable accuracy to several baselines while reducing the communication overhead by over 4x.
Read more8/21/2024
0
Federated Learning with Incomplete Sensing Modalities
Adiba Orzikulova, Jaehyun Kwak, Jaemin Shin, Sung-Ju Lee
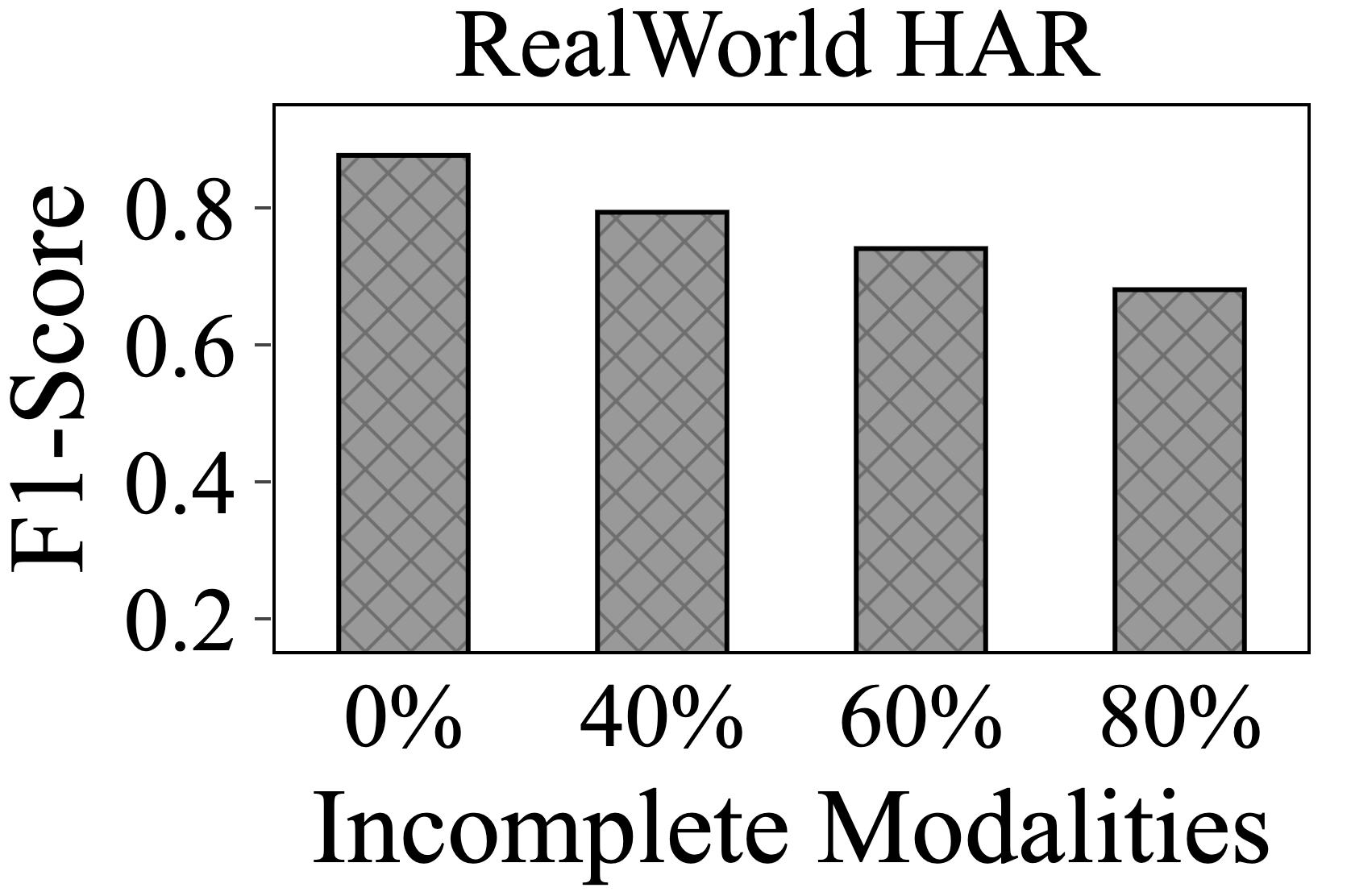
Many mobile sensing applications utilize data from various modalities, including motion and physiological sensors in mobile and wearable devices. Federated Learning (FL) is particularly suitable for these applications thanks to its privacy-preserving feature. However, challenges such as limited battery life, poor network conditions, and sensor malfunctions can restrict the use of all available modalities for local model training. Additionally, existing multimodal FL systems also struggle with scalability and efficiency as the number of modality sources increases. To address these issues, we introduce FLISM, a framework designed to enable multimodal FL with incomplete modalities. FLISM leverages simulation technique to learn robust representations that can handle missing modalities and transfers model knowledge across clients with varying set of modalities. The evaluation results using three real-world datasets and simulations demonstrate FLISM's effective balance between model performance and system efficiency. It shows an average improvement of .067 in F1-score, while also reducing communication (2.69x faster) and computational (2.28x more efficient) overheads compared to existing methods addressing incomplete modalities. Moreover, in simulated scenarios involving tasks with a larger number of modalities, FLISM achieves a significant speedup of 3.23x~85.10x in communication and 3.73x~32.29x in computational efficiency.
Read more5/21/2024

0
Overcome Modal Bias in Multi-modal Federated Learning via Balanced Modality Selection
Yunfeng Fan, Wenchao Xu, Haozhao Wang, Fushuo Huo, Jinyu Chen, Song Guo
Selecting proper clients to participate in each federated learning (FL) round is critical to effectively harness a broad range of distributed data. Existing client selection methods simply consider the mining of distributed uni-modal data, yet, their effectiveness may diminish in multi-modal FL (MFL) as the modality imbalance problem not only impedes the collaborative local training but also leads to a severe global modality-level bias. We empirically reveal that local training with a certain single modality may contribute more to the global model than training with all local modalities. To effectively exploit the distributed multiple modalities, we propose a novel Balanced Modality Selection framework for MFL (BMSFed) to overcome the modal bias. On the one hand, we introduce a modal enhancement loss during local training to alleviate local imbalance based on the aggregated global prototypes. On the other hand, we propose the modality selection aiming to select subsets of local modalities with great diversity and achieving global modal balance simultaneously. Our extensive experiments on audio-visual, colored-gray, and front-back datasets showcase the superiority of BMSFed over baselines and its effectiveness in multi-modal data exploitation.
Read more7/30/2024
0
Prioritizing Modalities: Flexible Importance Scheduling in Federated Multimodal Learning
Jieming Bian, Lei Wang, Jie Xu
Federated Learning (FL) is a distributed machine learning approach that enables devices to collaboratively train models without sharing their local data, ensuring user privacy and scalability. However, applying FL to real-world data presents challenges, particularly as most existing FL research focuses on unimodal data. Multimodal Federated Learning (MFL) has emerged to address these challenges, leveraging modality-specific encoder models to process diverse datasets. Current MFL methods often uniformly allocate computational frequencies across all modalities, which is inefficient for IoT devices with limited resources. In this paper, we propose FlexMod, a novel approach to enhance computational efficiency in MFL by adaptively allocating training resources for each modality encoder based on their importance and training requirements. We employ prototype learning to assess the quality of modality encoders, use Shapley values to quantify the importance of each modality, and adopt the Deep Deterministic Policy Gradient (DDPG) method from deep reinforcement learning to optimize the allocation of training resources. Our method prioritizes critical modalities, optimizing model performance and resource utilization. Experimental results on three real-world datasets demonstrate that our proposed method significantly improves the performance of MFL models.
Read more8/14/2024